Ч. Уэзерелл Этюды для программистов
А вы ноктюрн сыграть могли бы? или Предисловие редактора перевода
Своим внешним видом новый суперкомпьютер CRAY-1 мало похож на привычную всем нам вычислительную машину. Это круглый диван с высокой спинкой и мягкими кожаными сиденьями. До предела набитый электроникой, самый дорогой в мире «диванчик» вправе претендовать на включение в «Книгу рекордов Гиннеса». Но, конечно, дело не в форме, а в содержании. Машина выполняет сотни миллионов операций в секунду, и разговор о миллиардах операций уже не воспринимается как лишенная здравого смысла фантазия. А как изменилось программирование! Никого теперь не удивить программой из одной-двух тысяч команд, когда счет идет на мегабайты. Операционные системы, разного рода АСУ — поистине монументальные произведения, настоящие симфонии из мириад нулей и единиц. И в такой симфонии не должно прозвучать ни одной фальшивой ноты, а ведь пишут ее порой сотни людей — программирование становится массовой профессией. Как же в этих новых условиях учить и как учиться программировать? Существуют, конечно, задачники по программированию, в которых в достатке найдется примеров-миниатюр. Но, написав программу для вычисления квадратного корня, можно ли браться за разработку компилятора? Уготовано ли блестящее музыкальное будущее тому, кто преодолел только гаммы и сольфеджио? В 1978 г. издательство «Мир» выпустило два учебных пособия по программированию (Ламуатье Ж.-П. Упражнения по программированию на Фортране IV; Дрейфус М., Ганглоф К. Практика программирования на Фортране), совершенно не похожих на прежние задачники. В них демонстрируется работа над небольшими программами с подробным обсуждением всех этапов работы. Книги оказались чрезвычайно полезными для начального обучения и в ряде вузов были немедленно использованы в учебном процессе. Но как далек еще путь от камерной пьесы к симфонии! Книга Ч. Уэзерелла призвана заполнить еще одну «экологическую нишу» в учебной литературе по программированию. В книге в живой и увлекательной форме ставится 27 вполне реальных (или близких к реальным) задач-этюдов. Напомним, как определяется этюд в энциклопедическом словаре: «Этюд — музыкальная пьеса, основанная на определенном приеме исполнения и предназначенная для развития технического мастерства исполнителя. Создаются и высокохудожественные виртуозные сочинения этого жанра, предназначенные для концертного исполнения (фортепианные этюды Ф. Листа, Ф. Шопена, Р. Шумана и др.)». Действительно, почти каждый представленный здесь этюд несет в себе свою «изюминку»: структуры данных или управляющие структуры, обработку текстов или рекурсию… И почти каждый из них может служить заданием для курсовой работы. Есть, однако, столь «высокохудожественные» этюды (компилятор для алгебраического языка или интерпретатор-макропроцессор), что не всякий преподаватель осмелится предложить их даже в качестве дипломной работы. Разумеется, не только студенты, но и опытные программисты с пользой и интересом прочтут книгу, обнаружив в ней немало советов, соображений, приемов. Я уже не говорю о том, что этюды будут хорошим подспорьем для преподавателей программирования. По манере изложения книгу можно было бы отнести к разряду научно-популярных. Эта особенность, несомненно, привлечет к ней внимание многих читателей, далеких от программирования. Рекомендуя книгу Ч. Уэзерелла для перевода, чл.-корр. АН СССР А. П. Ершов отметил еще один важный момент: «Перевод этой книги полезен и сам по себе, и как побудительное средство к дальнейшему составлению подобного рода сборников задач по программированию». Неординарность книги создала определенные трудности при ее переводе. В каждой главе — своя тема, своя ситуация. Рассматривая ситуации, автор не связывает себя формальными рамками, да и самим ситуациям, заимствованным из американской жизни, не всегда находятся аналоги в нашей действительности. Переводчикам Н. И. Вьюковой, В. А. Галатенко, А. О. Лацису, А. Н. Полюдову и А. Б. Ходулеву помимо обычной переводческой деятельности пришлось заняться исполнительской практикой: некоторые этюды были проиграны, у некоторых проверены приведенные ответы. Там, где это необходимо, были даны примечания или добавлены партии переводчика, а библиография дополнена изданиями, доступными советскому читателю. Материал, добавленный при переводе, помечен знаком *. Ю. Банковский Февраль 1982 г.Предисловие
Программирование — это ремесло, и каждый программист должен достичь нужного профессионального уровня. Надо сказать, что программированием, как правило, занимаются кустарно, в небольших организациях, где имеются лишь примитивные инструменты, многое делается вручную, необходимые сведения в лучшем случае черпаются у более опытных мастеров, а бывает, что получить их и вовсе неоткуда. Подобно тому как в средние века образовывались гильдии ремесленников — отчасти для обучения молодых работников, отчасти для повышения профессионального уровня, — так и в наши дни созданы многочисленные учебные заведения для подготовки программистов, и все меньшее и меньшее их число обучается (или убеждается в своей профессиональной непригодности) на собственных синяках и шишках. Однако выяснилось, что для подготовки мастеров высокого класса усилий одних лишь преподавателей недостаточно. В этом отношении ученичество в гильдиях обладало неоспоримыми преимуществами. Классическое обучение ремеслу состояло в том, что ученик в течение многих лет выполнял простейшие вспомогательные операции, перенимая основные приемы у более опытных работников. Постепенно на него возлагались все более серьезные обязанности, и после формальной проверки навыков он получал официальное подтверждение своей профессиональной компетентности. Теперь это был ремесленник, способный выполнять любые работы по своей специальности. Он покидал мастерскую, где учился, и в поисках заказов бродил по свету. А в один прекрасный день, если музы были к нему благосклонны, представлял на суд гильдии свой шедевр и поднимался на высшую ступень профессиональной иерархии, становясь мастером гильдии. Творения этих мастеров, даже самого утилитарного назначения, воспринимаются часто как величайшие проявления человеческого гения. В наши дни начинающему программисту уже не нужно семь лет[1] вытряхивать отходы от пробивки перфокарт, скапливающиеся в перфорирующих устройствах — необходимые технические знания ему проще получить, посещая лекции и изучая литературу. Теперь нет никакой надобности, заглядывая через плечо опытного программиста, изо дня в день наблюдать за его работой. А вот на то, чтобы набить руку на выполнении реальных программистских задач, усвоить и закрепить основные методы и принципы работы, просто для практики, наконец, действительно нужно время. Ясно, что, прочитав несколько книг по столярному делу, нельзя сразу взять и произвести на свет что-нибудь изящное в стиле Чиппендейла[2]. Так почему же человек, прочитавший одно-два руководства по программированию, вдруг сразу начнет писать стройные, грамотные программы? В учебных заведениях, готовящих программистов, — в колледжах, профессиональных школах, на курсах повышения квалификации— процесс обучения сопровождается выполнением лабораторных, курсовых работ по программированию, дипломных проектов по обычным курсам. Преподавателям, ведущим такие занятия, необходимо иметь набор задач для своих учеников. Для удовлетворения этой потребности и предназначаются наши этюды. Каждый этюд — самостоятельная задача со своей информационной основой, формулировкой и предполагаемым методом решения. Большинство из них допускает вариации, так что преподаватель может привязать задачу к конкретным условиям. Разнообразие предлагаемых композиций весьма велико. Некоторые этюды требуют прежде всего интеллектуальных усилий (гл. 9), у других основная трудность заключена в реализации (гл. 12); есть совсем короткие этюды (гл. 16) и, напротив, очень длинные (гл. 6); в некоторых используются широко известные методы реализации (гл. 5), в других же (гл. 2) методы реализации можно непрерывно совершенствовать. Главы 25–28 образуют связный цикл, который можно включить в курсы по языкам программирования и системам. Для выполнения этих этюдов нужно подобрать группы студентов, обладающих необходимыми знаниями по системному программированию (как правило, раньше студенты и не подозревали, что работа в группе программистов — совсем не то же самое, что работа в одиночку). Главы 5, 6, 13, 17, 19 и 25 могут дать хороший материал для курса по моделированию на ЭВМ, а гл. 6, 11, 14, 19, 20 связаны с задачами искусственного интеллекта. Разумеется, широко представлены также традиционные задачи по информатике. Студенты, выполняющие лабораторный практикум, смогут оценить четкие формулировки задач. (Сколько несчастных поклялось никогда в жизни и близко к машине не подходить после отчаянных попыток разобрать неряшливые формулировки, нечетко отпечатанные на ротапринте.) Те же студенты, которые могли сами выбирать задачи (как в курсе, послужившем основой этой книги), оценят разнообразие предоставляемого им здесь выбора — ни одному преподавателю не хватило бы энергии подготовить столько задач. Разумеется, наш сборник, равного которому по объему еще не было, окажется полезным тем, кто повышает свою квалификацию самостоятельно. Отдельные этюды могут послужить источником методов программирования для лиц, уже окончивших учебные заведения. Как и всегда в подобных случаях, книга не могла быть написана без помощи многих и многих людей. Джордж Майкл впервые выдвинул идею обучения на задачах (которая теперь нашла признание во многих других учебных заведениях). Студенты нескольких групп охотно испытывали задачи, предлагая исправления и даже новые темы. Хэнк Молл написал программу форматирования текстов, при помощи которой была подготовлена рукопись книги, и всегда был готов по мере надобности вносить в свою программу изменения. Рукопись с включенными в нее иллюстрациями была напечатана изящными шрифтами благодаря программе Джона Битти. Обе эти программы позволили лучше представить себе окончательный внешний вид книги, что очень помогло автору при ее создании. Многие мои друзья читали, обсуждали и критиковали книгу и ободряли автора. Наконец, перфораторщицы Ливерморской лаборатории не только никогда не жаловались на плохой почерк, а всегда быстро возвращали готовые колоды карт, да еще с исправленными орфографическими ошибками. Не будь всех этих помощников — не было бы и книги; лишь благодаря их участию она увидела свет. Чарлз Уэзерелл1. Что бы это значило? или Как читать книгу
Преподавание программирования — дело почти безнадежное, а его изучение — непосильный труд. Преподаватель может всячески возиться со студентами, читать лекции, делать критические замечания, направлять по верному пути. Студент[3] может все тщательно записывать, запоминать, читать, сдавать зачеты, дискутировать хоть до двух часов ночи. Но все усилия тщетны, если студент не будет практиковаться в написании программ, поскольку навык программирования (как, впрочем, и всякий навык) дается только практикой. Более того, учиться надо на «настоящих» программах, а не на упрощенных примерах, вроде тех, которыми изобилует большинство руководств по языкам программирования. Сколько ни бренчи чижика, вторым Рубинштейном не станешь. Точно так же долбежка языка APL вряд ли поможет вам достичь высот в программировании. Поэтому в настоящей книге представлены довольно объемистые задачи. В качестве учебных проектов они вполне подойдут новичкам, стремящимся стать сначала просто грамотными программистами, а затем и специалистами высокого класса. Способности, необходимые программисту, можно сравнить с теми, которые требуются, например, очеркисту. Как и очеркист, программист должен владеть некоторыми правилами правописания и грамматики, но, вопреки общепринятому мнению, для них обоих это не главное. Гораздо важнее быть наблюдательным и ищущим, уметь анализировать и ясно выражать свои мысли. Перечислим те способности, которые жизненно необходимы всякому программисту (и очеркисту тоже). Способность читать и понимать описание поставленной задачи, улавливать пожелания того, кто ее ставит (что не всегда легко, так как и задачи, и те, кто их ставит, часто отличаются именно неуловимостью). Способность четко видеть действительные трудности и отбрасывать все, не относящееся к делу. Способность выявлять все случаи, где можно применить теорию, самостоятельно решиться на ее применение или обратиться за советом к специалисту. Способность разбить задачу на ряд обозримых независимых частей и понять взаимосвязи этих частей. Способность оценивать эффективность предлагаемых решений с точки зрения затрат на программирование, машинных ресурсов и удовлетворения потребностей пользователя и находить приемлемый компромисс между этими видами эффективности. Способность объединять множество частных решений воедино, получая при этом четкое и изящное решение всей задачи. Способность выражать решения на простом и понятном языке. Естественный это язык или искусственный — роли не играет, важно лишь, чтобы правильность решения была ясна и людям, и машине. И наконец, способность при неудаче подавить самолюбие и поискать другой подход (или даже другую задачу). Способности эти, как видим, столь сложны и многообразны, что приобрести их можно только на практике. Этюды дают возможность отработать конкретные технические приемы. Накапливая опыт, студент постепенно приобретает качества, необходимые программисту. Составлять этюды, однако, не так просто, как может показаться. Все еще слишком часто задачки из книжек по программированию представляют собой просто технические «упражнения для пальцев». Полезные для выработки навыков уверенного использования простейших языковых конструкций, они редко бывают «высокохудожественными», что требуется от этюда в определении, приводимом в энциклопедическом словаре. Несмотря на то что этюд — упражнение, «основанное на определенном техническом приеме исполнения» (см. тот же словарь), хороший этюд должен быть достаточно большим, чтобы ощущалась взаимосвязь этого приема с другими областями программирования. Все это наталкивает на мысль взять задачи непосредственно из жизни. «Настоящие» задачи, однако, изобилуют несущественными деталями, требуют обработки массы данных, порождают гору результатов и к тому же меняются чуть ли не каждый день, так как руководство никак не может принять окончательное решение. Из студента, способного освоить профессию прямо в производственном коллективе, конечно, выйдет прекрасный специалист, но слишком многие из обучающихся программированию таким образом не выдерживают и, отчаявшись, бросают. Так что этюд должен лежать где-то посередине между реальной жизнью и тривиальными упражнениями. Две области — игры и информатика — породили, в сущности, почти все эти этюды и наделили их рядом полезных черт. Программисты, как правило, интересуются и тем, и другим приложением (уж лучше бы только информатикой, разумеется). Поскольку культура — всеобщее достояние, большинство игр доступно пониманию каждого; объяснить прикладную задачу в наше время также нетрудно. Очень часто поведение игровой программы или, скажем, транслятора поддается строгому описанию, так что корректность решения можно проверить. Входные данные обычно невелики по объему, и готовить их легко; выходные данные легко воспринимаются. Обе упомянутые области требуют применения весьма развитых алгоритмов и структур данных, так что вряд ли какие-либо сложности в прикладных программах смогут впоследствии поставить студента в тупик. Наконец, в обеих этих областях ЭВМ предстает перед нами как мощный объект абстрактного «разума» (такой подход принят в задачах искусственного интеллекта); возможно, в нашем подборе задач чувствуется давний интерес к «разумным» машинам. Имеется, конечно, много задач и из других прикладных областей. При их отборе мы руководствовались в основном легкостью объяснения ситуации, которая приводит к постановке задачи. Тем, кому некоторые этюды покажутся легкомысленными, мы напомним, что Гайдн создал симфонию из колыбельной песни.Как исполнять этюд
Предполагается, что новичок, берущийся за этюд, уже написал несколько программ и знает сравнительно хорошо хотя бы один язык. Здесь не ставится задача научить конкретным приемам программирования, структурам данных или языкам. Если для решения задачи требуются какие-то специальные знания, трудные места обсуждаются достаточно подробно, а источники дополнительной информации указаны в библиографии. Более того, мы не описываем какой-либо конкретный стиль программирования и не обсуждаем вопросы структурного программирования. Вероятно, большинство читателей слушает лекции или посещает семинарские занятия и может воспользоваться советами преподавателя. Занимающиеся самостоятельно могут почерпнуть сведения по технике и стилю программирования из источников, перечисленных в конце главы. Каждый этюд распадается на разделы (некоторые из них необязательные). В первом разделе описывается реальная ситуация, во втором — конкретная программа, которую предстоит написать. Обычно ситуация разъясняется достаточно подробно, а постановка задачи — совсем короткая. Затем следует обсуждение трудностей, которые могут встретиться при реализации, и намеки на возможные пути решения. Рассматриваются только существенные моменты. Затем следуют разделы, в которых обсуждается выбор языка и длительность исполнения этюда[4]. Временные оценки, которые рассчитаны на аспирантов первого года обучения, выделяющих для решения задачи четверть своего рабочего времени, могут оказаться малы для программистов, работающих не столь увлеченно. Кроме того, временные оценки могут увеличиваться под влиянием условий доступа к машине. В конце этюда часто содержится расширение поставленной задачи и аннотированная библиография. Решение, найденное с использованием дополнительной литературы, более полезно для студента. Конечно, результатом работы над этюдом должна быть понятная и четкая программа, стиль и комментарии которой соответствовали бы задаче и выбранному языку. Но этого мало. Еще необходим набор тестов, достаточный для демонстрации работы программы и ее реакции на экстремальные ситуации и неправильное обращение. Наряду с самой программой требуется краткое словесное описание методов решения. Особый упор в нем следует сделать на положенные в основу решения алгоритмы и структуры данных. Наряду с описанием программы программист должен с достаточной степенью правдоподобности хотя бы неформально проиллюстрировать ее правильность (при недостатке времени можно ограничиться рассмотрением ключевых мест). Наконец, должен быть произведен подсчет затраченных ресурсов, как людских, так и машинных; особое внимание следует обратить на обоснование затрат. Также следует указать, чему программист научился на примере этой задачи (на этот вопрос легко ответить, если сформулировать его в виде: «Что я в следующий раз сделаю иначе?»). Такой объем документации может показаться избыточным. Заметим, однако, что умению вовремя поставить точку тоже очень полезно научиться. Решение небольшой задачи не следует перегружать документацией. Один знакомый автору преподаватель определяет оценку на 40% тем, что студент убедил его в правильности программы, на 50% легкостью, с которой его удалось убедить, и только на 10% отличным программированием. Очень хорошая оценка — это 80% и более. А поскольку часть документации — результаты машинных прогонов, такая отметка означает, что программа произвела благоприятное впечатление и на преподавателя, и на ЭВМ.Советы преподавателю
Первоначально книга предназначалась для студентов — слушателей вводного курса по информатике. Лекционная часть этого курса охватывает широкий спектр вопросов, включая языки и технику программирования, архитектуру ЭВМ, структуры данных, алгоритмы и некоторые сведения из теории. Лектор может использовать некоторые задачи в качестве примеров (скажем, задачу о раскрашивании карты — для обучения Паскалю), но в целом задачи предназначены для самостоятельного решения. Предполагается только, что общее время, отводимое на решение задач, будет не меньше, чем продолжительность всего курса. На структуру самого курса не налагается практически никаких ограничений. С другой стороны, имеются четыре задачи специально для курсов по компиляторам. Эти задачи прямо ориентированы на поддержку обучения методам реализации языков программирования. В нескольких задачах представлены некоторые основные аспекты программирования игр. Другие могут служить материалом для практических занятий по программированию коммерческих задач и задач имитационного моделирования. Заинтересованный преподаватель сможет найти здесь задачи из любой области, кроме численного анализа.Литература
Science Citation Index. Institute for Scientific Information, Philadelphia, PA. Yearly. Если вы хотите узнать побольше по какому-либо из затронутых в нашей книге направлений, можно воспользоваться цитированной литературой, затем — библиографией из этих работ и т. д. Но как найти работы, которые вышли в свет уже после перечисленных в книге? Если у вас есть некий источник по какой-либо теме, то в Science Citation Index можно найти работы, ссылающиеся на имеющуюся у вас. В каждом из ежегодных выпусков разъясняется, как им пользоваться, да и библиотекарь вам в этом поможет. Конвей, Грис (Conway R., Gries D.). An Introduction to Programming, 2nd ed. Winthrop, Cambridge, MA, 1975. Строго говоря, это — введение в программирование (а заодно и хорошее руководство по PL/I). Но, кроме того, это прекрасный учебник по надежности и методам доказательства правильности программ. Перед тем как приступить к вашему первому этюду, имеет смысл повторить материал по построению программ, приведенный в этой книге. Вирт (Wirth N.). Algorithms + Data Structures = Programs, Prentice-Hall, Englewood Cliffs, NJ, 1976. Дейкстра (Dijkstra E. W.). A Discipline of Programming, Prentice-Hall, Englewood Cliffs, NJ, 1976. [Имеется перевод: Дейкстра Э. Дисциплина программирования.— М.: Мир, 1978.] Работы Дейкстры и Вирта перекликаются друг с другом, хотя и написаны независимо. Примерный курс мог бы выглядеть так: прочитайте Конвея и Гриса; попробуйте несколько несложных задач; прочитайте Вирта; попробуйте несколько более трудных задач; прочитайте Дейкстру и снова решите уже пройденные задачи. Вирт, по существу, приводит примеры программ и методы их построения для некоторых задач среднего размера. Дейкстра обсуждает в целом только критические циклы, а также структуры данных, но приводит больше формальных доказательств. В книге Дейкстры также содержатся размышления о программировании как творческой деятельности, и эти мысли, может быть, самая ценная часть книги (но для того, чтобы их оценить, требуется некоторый опыт). Грисуолд, Поудж, Полонски (Griswold R. E., Poage J. E., Polonsky I. P.). The SNOBOL4 Programming Language, 2nd ed. Prentice-Hall; Englewood Cliffs, NJ, 1971. [Имеется перевод: Грисуолд Р., Поудж Дж., Полонски И. Язык программирования Снобол-4. — М.: Мир, 1980.] Имеется множество книг по таким языкам, как Фортран, Кобол, Бейсик, Алгол, языки ассемблера и PL/I. Айверсон разработал язык APL как алгоритмический; перед тем как приступить к работе с его конкретной реализацией, ознакомьтесь с соответствующим руководством. Книга Мак-Кимана и др. — эталонное описание языка XPL. Перед тем как работать с языками Лисп или Снобол, очень желательно ознакомиться с особенностями конкретной реализации. Айверсон (Iverson К. Е.). A Programming Language. Wiley, New York, 1962. *Гилман, Роуз. Курс АПЛ: диалоговый подход. Пер. с англ. — М.: Мир, 1979. Йенсен, Вирт (Jensen К., Wirt N.) PASCAL User Manual and Report. Lecture Notes in Computer Science, 18, Springer-Verlag, Berlin, 1974. *Грогоно. Программирование на языке Паскаль. Пер. с англ. — М.: Мир, 1982. Кнут (Knuth D. E.). The Art of Computer Programming/Fundamental Algorithms. Addison-Wesley, Reading, MA, 1968. [Имеется перевод: Кнут Д. Искусство программирования для ЭВМ. Т. 1. Основные алгоритмы. — М.: Мир, 1976.] Серия книг Кнута[5], если он когда-нибудь ее закончит, имеет все шансы стать библией программистов. Конечно же, первый том содержит наиболее элементарные сведения о структурах данных и алгоритмах работы с ними. Если вы не понимаете, как воспользоваться предложенной в настоящей книге структурой данных, — справьтесь у Кнута. Мы, однако, не предлагаем стиль программирования Кнута как образец структурирования программ. Люка (Lucas F. L.). Style. Collier, New York, 1962. Эта книга вовсе не о программировании. Вам со временем понадобится писать обширную документацию — тут-то и может помочь эта книга. Более того, многие наблюдения автора применимы также и к написанию программ. Люка сосредоточивает внимание на способах убеждения, а программисту приходится убеждать и машину, и человека. Мак-Карти и др. (McCarthy J. et al.). LISP 1.5 Programmer's Manual. MIT Press, Cambridge, MA, 1972. Мак-Киман, Хорнинг, Уортмен (McKeeman W. M., Horning J. J. Wortman D. B.)s A Compiler Generator. Prentice-Hall; Englewood Cliffs, NJ, 1970. Вегнер (Wegner P.). Programming Languages, Information Structures, and Machine Organization. McGraw-Hill, New York, 1968. Если у вас возникнут какие-либо вопросы об архитектуре ЭВМ, языках, структурах данных, а также их взаимосвязях, книга Вегнера, возможно, даст ключ к ответу. В книге собрано и увязано воедино исключительное количество распространенных терминов. Приводится краткий обзор информатики и ценный список литературы.2. Жизнь диктует свои законы, или Клеточные автоматы и машинная графика
Жизнь — это многоклеточное сообщество, населяющее пустыни Флатландии. Пустыня представляет собой квадратную решетку, каждая ячейка которой вмещает одну клетку Жизни. Мерой течения времени служит смена поколений Жизни, приносящая в колонию клеток смерть и рождение. Чтобы проследить за историей развития колонии, разместим в пустыне клетки Жизни в их начальном положении. Смена поколений будет происходить по следующим правилам. 1. Соседями клетки считаются все клетки, находящиеся в восьми ячейках, расположенных рядом с данной по горизонтали, вертикали или диагонали. 2. Если у некоторой клетки меньше двух соседей, она погибает от одиночества. Если клетка имеет больше трех соседей, она погибает от тесноты. 3. Если рядом с пустой ячейкой окажется ровно три соседние клетки Жизни, то в этой ячейке рождается новая клетка. 4. Гибель и рождение происходят в момент смены поколений. Таким образом, гибнущая клетка может способствовать рождению новой, но рождающаяся клетка не может воскресить гибнущую, и гибель одной клетки, уменьшив локальную плотность населения, не может предотвратить гибель другой. На рис. 2.1 показана история еще одной колонии клеток Жизни.
На рис. 2.1 показана история еще одной колонии клеток Жизни.
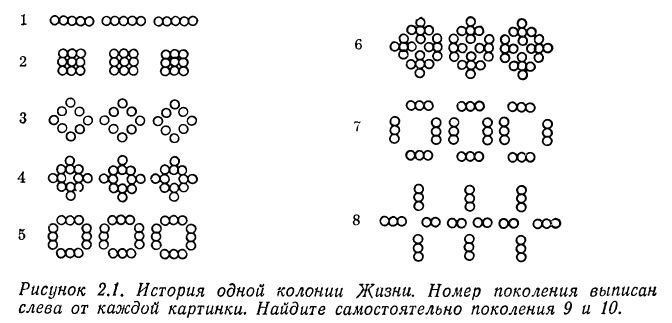 Тема. Напишите программу, моделирующую колонию Жизни. Исходными данными служит начальное расположение клеток, а в качестве результата нужно получить вид сверху всех поколений колонии. Для вывода истории можно воспользоваться обычным устройством построчной печати (АЦПУ), но такой способ дает весьма неприглядные изображения. Если в вашем распоряжении имеется графопостроитель или графический терминал, воспользуйтесь их возможностями для получения более изящной картинки.
Рекомендации исполнителю. Хотя этого и не видно из примеров, некоторые колонии разрастаются невероятным образом при весьма скромных начальных размерах. Есть другие колонии, которые медленно перемещаются по пустыне, переходя на все новые и новые территории. Ваша программа должна обрабатывать большие колонии без чрезмерной траты памяти или времени. Многократный просмотр большого массива для построения следующих поколений — это банальный подход; здесь программистская задача состоит в выборе более экономичных структур данных и алгоритмов. Вам, возможно, захочется испытать какой-либо метод, отслеживающий только занятые квадраты. Растущая или движущаяся колония может выйти из поля зрения, если его положение и границы зафиксированы, поэтому, вероятно, понадобится еще и метод вывода, перемещающий нашу точку зрения вслед за изменениями колонии[6].
Инструментовка. Для этой задачи подойдет язык APL благодаря наличию в нем операций над векторами и матрицами, однако можно использовать почти любой язык высокого уровня, если в нем предусмотрена работа с массивами. На примере этой задачи хорошо изучать, как сказывается использование языка ассемблера: насколько замедляется программирование и каков выигрыш в эффективности внутреннего цикла. Наконец, для тех, кто имеет доступ к оборудованию ЭВМ, интересным экспериментом могла бы быть микропрограммная реализация; машина при этом превращается в колонию Жизни.
Длительность исполнения. Одному исполнителю на 3 недели.
Развитие темы. Колония может все время расти, непрерывно меняя свое расположение, форму или число клеток. Однако чаще колония становится в конце концов стационарной, начиная циклически повторять один и тот же конечный набор состояний. Длина цикла называется периодом колонии. (По этому определению период мертвой и пустой колонии равен единице.) Измените вашу программу так, чтобы она выявляла стационарные колонии и сообщала о них. Можете ли вы придумать хоть какой-нибудь алгоритм, не использующий запоминания всех предыдущих поколений, который мог бы распознать любую стационарную колонию?
История колонии... Жизнь зачаровывает, если ее просматривать как фильм (это одно из соображений в пользу графического терминала), но она будет еще увлекательней, если предстанет в цвете. Каждой клетке при рождении может быть приписан некоторый цвет, определяемый, возможно, ее поколением или генами, переданными ей родителями. Циклические, но при этом движущиеся колонии (а таких немало) великолепны в своем сверкающем многоцветном наряде.
Любая колония имеет преемника, но не у каждой есть предшественник. Такие изолированные колонии называются садами Эдема. Сад Эдема можно увидеть, только если поместить его на плоскость в качестве начальной конфигурации. Подумайте, как использовать вашу программу для нахождения сада Эдема.
Тема. Напишите программу, моделирующую колонию Жизни. Исходными данными служит начальное расположение клеток, а в качестве результата нужно получить вид сверху всех поколений колонии. Для вывода истории можно воспользоваться обычным устройством построчной печати (АЦПУ), но такой способ дает весьма неприглядные изображения. Если в вашем распоряжении имеется графопостроитель или графический терминал, воспользуйтесь их возможностями для получения более изящной картинки.
Рекомендации исполнителю. Хотя этого и не видно из примеров, некоторые колонии разрастаются невероятным образом при весьма скромных начальных размерах. Есть другие колонии, которые медленно перемещаются по пустыне, переходя на все новые и новые территории. Ваша программа должна обрабатывать большие колонии без чрезмерной траты памяти или времени. Многократный просмотр большого массива для построения следующих поколений — это банальный подход; здесь программистская задача состоит в выборе более экономичных структур данных и алгоритмов. Вам, возможно, захочется испытать какой-либо метод, отслеживающий только занятые квадраты. Растущая или движущаяся колония может выйти из поля зрения, если его положение и границы зафиксированы, поэтому, вероятно, понадобится еще и метод вывода, перемещающий нашу точку зрения вслед за изменениями колонии[6].
Инструментовка. Для этой задачи подойдет язык APL благодаря наличию в нем операций над векторами и матрицами, однако можно использовать почти любой язык высокого уровня, если в нем предусмотрена работа с массивами. На примере этой задачи хорошо изучать, как сказывается использование языка ассемблера: насколько замедляется программирование и каков выигрыш в эффективности внутреннего цикла. Наконец, для тех, кто имеет доступ к оборудованию ЭВМ, интересным экспериментом могла бы быть микропрограммная реализация; машина при этом превращается в колонию Жизни.
Длительность исполнения. Одному исполнителю на 3 недели.
Развитие темы. Колония может все время расти, непрерывно меняя свое расположение, форму или число клеток. Однако чаще колония становится в конце концов стационарной, начиная циклически повторять один и тот же конечный набор состояний. Длина цикла называется периодом колонии. (По этому определению период мертвой и пустой колонии равен единице.) Измените вашу программу так, чтобы она выявляла стационарные колонии и сообщала о них. Можете ли вы придумать хоть какой-нибудь алгоритм, не использующий запоминания всех предыдущих поколений, который мог бы распознать любую стационарную колонию?
История колонии... Жизнь зачаровывает, если ее просматривать как фильм (это одно из соображений в пользу графического терминала), но она будет еще увлекательней, если предстанет в цвете. Каждой клетке при рождении может быть приписан некоторый цвет, определяемый, возможно, ее поколением или генами, переданными ей родителями. Циклические, но при этом движущиеся колонии (а таких немало) великолепны в своем сверкающем многоцветном наряде.
Любая колония имеет преемника, но не у каждой есть предшественник. Такие изолированные колонии называются садами Эдема. Сад Эдема можно увидеть, только если поместить его на плоскость в качестве начальной конфигурации. Подумайте, как использовать вашу программу для нахождения сада Эдема.
Литература
Беркс (ред.) (Burks A. W. (Ed.)). Essays on Cellular Automata. University of Illinois Press, Urbana, IL, 1970. Кодд (Codd E. F.). Cellular Automata. Academic Press, New York, NY, 1968. Обе эти книги значительно серьезнее статей Гарднера в Scientific American. Вторая из названных книг познакомит вас с основами предмета, а книга Беркса представляет собой сборник разнородных статей, охватывающих всю область клеточных автоматов. После изучения этих книг читателю будет доступен практически весь математический материал. Гарднер (Gardner Martin). Mathematical Games. Scientific American, 223, 10, pp. 120–123, October 1970, and 224, 2, pp. 112–117, February 1971. [Имеется перевод: Гарднер М. Математические досуги. — Мл Мир, 1972, с. 458.] Мартин Гарднер описал игру Жизнь в своей колонке журнала, и это вызвало такой отклик читателей, что он вынужден был немедленно (по меркам ежемесячного журнала) посвятить ей еще одну колонку. Игра Жизнь, несомненно, принесла славу Джону Хортону Конвею, ее талантливому и продуктивному изобретателю. В более поздних статьях содержится много дополнительного материала об игре Жизнь, а также о других работах Конвея. Уэйнрайт (ред.) (Wainwright R. Т. (Ed.)). Lifeline. 1280 Edcris Road, Yorktown Heights, NY 10598. Lifeline — ежеквартальный журнал, посвященный Жизни и родственным темам. Ориентированный на фанатиков этой игры, журнал содержит всевозможную информацию о Жизни, и его чтение может оказаться захватывающим занятием.3. Папочка, а почему море синее? или Раскрашивание карты методом исчерпывающего поиска
Чтобы на географической карте было удобно различать регионы, ее раскрашивают по следующему правилу: два региона должны быть окрашены в разные цвета, если их границы имеют более чем конечное число общих точек. (Обычно составители карт не страдают топологическими патологиями и не ищут вырожденных примеров, противоречащих здравому смыслу.) С другой стороны, картографам предстоит оплачивать типографские счета, поэтому, чем меньше цветов будет использовано, тем лучше. В частности, картографы, расписывающие карту как попало, распишутся лишь в своем легкомыслии: им придется использовать больше красок, чем это необходимо. Свои действия нужно планировать заранее. Итак, задача о раскрашивании карты сводится, в сущности, к определению минимального числа красок. Для решения этой задачи обратимся к помощи компьютера. Тут нас подстерегают трудности: большинство ЭВМ лишено зрения, поэтому они не могут посмотреть на карту; к счастью, им нужно знать лишь, какие регионы являются соседями, т. е. смежны друг другу. Размер и форма регионов не влияют на раскраску, важно лишь наличие нетривиальных контактов между ними. Для представления отношения смежности полезно воспользоваться неориентированным графом. Неориентированный граф состоит из конечного множества вершин и конечного множества ребер, связывающих вершины. Любые две вершины связаны не более чем одним ребром; не должно быть двух дублирующих друг друга ребер; кроме того, для рассматриваемой задачи мы запрещаем ребру связывать вершину с самой собой. На рис. 3.1 изображен неориентированный граф, представляющий первые 49 американских штатов. Ввести граф в ЭВМ несложно: достаточно перечислить все вершины, сопроводив каждую списком смежных ей вершин. Граф может не иметь вершин, а значит, и ребер; такой граф называется пустым. Вершина может быть изолированной, если нет ребер, связывающих ее с другими вершинами (примером тому могли бы служить Аляска и Гавайи); точно так же две части графа окажутся изолированными друг от друга, если нет ребер, их связывающих. Аналогия между картами и неориентированными графами столь тесна, что мы будем использовать эти понятия как равнозначные. Ну, а польза, приносимая графами, столь велика, что всем программистам следует иметь представление об их основных свойствах. Рисунок 3.1. Топологическая карта Соединенных Штатов. Для нее достаточно четырех цветов. (WA — Вашингтон, OR — Орегон, CA — Калифорния, NV — Невада, ID — Айдахо, UT — Юта, AZ — Аризона, МТ — Монтана, WY — Вайоминг, СО — Колорадо, NM — Нью-Мексико, ND — Северная Дакота, SD — Южная Дакота, NE — Небраска, КА — Канзас, ОК — Оклахома, ТХ — Техас, MN — Миннесота, IA — Айова, МО — Миссури, AR — Арканзас, LA — Луизиана, WI — Висконсин, IL — Иллинойс, IN — Индиана, MS — Миссисипи, AL — Алабама, Ml — Мичиган, ОН — Огайо, KY — Кентукки, TN — Теннесси, GA — Джорджия, FL — Флорида, РА — Пенсильвания, WV — Западная Виргиния, VA — Виргиния, NC — Северная Каролина, SC — Южная Каролина, NY — Нью-Йорк, NJ — Нью-Джерси, DE — Делавэр, MD — Мэриленд, DC — округ Колумбия, VT — Вермонт, МА — Массачусетс, СТ — Коннектикут, WE — Мэн, NH — Нью-Гэмпшир, RI — Род-Айленд.)
Тема. Напишите программу, раскрашивающую карту в минимальное число цветов. Исходными данными служит список регионов с указанием соседей каждого региона. Результатом должен быть список регионов с приписанными им цветами и общее число использованных цветов. Обычно проще всего для обозначения регионов и цветов применить положительные числа, но куда приятнее (и полезнее для отладки), если допускается ввод более привычных названий. Исходные данные должны проверяться на непротиворечивость; выявляйте нелепые номера вершин и связанные с собой вершины. Постарайтесь сделать программу по возможности эффективной, иначе раскраска тяжелых случаев окажется для вас слишком дорогим удовольствием.
Указания исполнителю. Исходная карта не обязана быть планарной. В самом деле, вполне допустимыми крайними случаями служат карты, в которых любые два региона — соседи, и карты, в которых никакие два региона не являются соседями. Последний случай соответствует раскраске множества раздельных шаров, когда достаточно только одного цвета. Проверка планарности — важная тема информатики, ей посвящено немало статей. Возможно, вас заинтересует проверка гипотезы о четырех красках, утверждающей, что для любой планарной карты требуется не более четырех красок. Если вам удастся подтвердить или опровергнуть ее, вы сделаете себе имя[7].
Из ресурсов, требуемых данной задачей, самый важный — время. Конечно, нет смысла перебирать все возможные решения, поскольку их число быстро увеличивается с ростом числа регионов, а доля правильных решений (даже если таковых несколько) мала. Лучше воспользоваться методом перебора с возвратами. Начните с выбора некоторого региона и приписывания ему цвета. В дальнейшем переходите к соседнему нераскрашенному региону и пытайтесь приписать ему какой-нибудь из использованных цветов, совместимый с уже сделанной раскраской. (Может случиться, что раскрашивать больше нечего, тогда задача решена. Возможен и случай, когда не осталось нераскрашенных регионов, соседних с раскрашенными, т. е. попалась несвязная карта.) Если в некоторый момент новый регион не удается раскрасить, отступайте от уже раскрашенных регионов (в соответствии с порядком раскраски) до тех пор, пока не найдется регион, цвет которого можно изменить. Раскрасьте его в цвет, которого он ранее не имел, и снова продвигайтесь вперед. Если при отступлении вы возвратились в регион, раскрашенный первым, добавьте к своей палитре новый цвет и начните сначала.
Инструментовка. Для решения задачи достаточно таких структур данных, как массивы и стеки, поэтому годится почти любой алгебраический язык высокого уровня с подходящими управляющими структурами. (Попытки записи решения на Фортране или Бейсике должны показать скудость этих языков.) С другой стороны, перебор с возвратами выглядит элегантно в рекурсивной формулировке. Поэтому, возможно, полезным окажется язык с рекурсивными процедурами. И рекурсия, и подходящие структуры данных имеются в языке Лисп.
Длительность исполнения. Одному исполнителю на 1 неделю.
Развитие темы. При использовании метода перебора с возвратами огромное влияние на время работы оказывает порядок выбора регионов. Учитывая этот эффект, можно заранее упорядочить регионы или использовать некоторые эвристики для выбора очередного региона. По-видимому, те регионы, у которых много соседей, раскрасить труднее, поскольку на их цвет накладывается больше ограничений. Из тех же соображений почти изолированную группу регионов следует рассмотреть отдельно, так как если ее не удастся раскрасить некоторым набором цветов, то и всю карту — тоже. Идея в обоих случаях состоит в том, что, если раскраска какого-либо региона может вызвать затруднения, ее нужно выполнить пораньше, чтобы не тратить время на разрушение почти законченной раскраски. Разумеется, полное решение такой «предварительной» задачи равносильно решению исходной задачи, но ведь и небольшой вклад может принести вполне ощутимую прибыль. Сравните несколько стратегий предварительного упорядочения по стоимости и эффекту.
Рисунок 3.1. Топологическая карта Соединенных Штатов. Для нее достаточно четырех цветов. (WA — Вашингтон, OR — Орегон, CA — Калифорния, NV — Невада, ID — Айдахо, UT — Юта, AZ — Аризона, МТ — Монтана, WY — Вайоминг, СО — Колорадо, NM — Нью-Мексико, ND — Северная Дакота, SD — Южная Дакота, NE — Небраска, КА — Канзас, ОК — Оклахома, ТХ — Техас, MN — Миннесота, IA — Айова, МО — Миссури, AR — Арканзас, LA — Луизиана, WI — Висконсин, IL — Иллинойс, IN — Индиана, MS — Миссисипи, AL — Алабама, Ml — Мичиган, ОН — Огайо, KY — Кентукки, TN — Теннесси, GA — Джорджия, FL — Флорида, РА — Пенсильвания, WV — Западная Виргиния, VA — Виргиния, NC — Северная Каролина, SC — Южная Каролина, NY — Нью-Йорк, NJ — Нью-Джерси, DE — Делавэр, MD — Мэриленд, DC — округ Колумбия, VT — Вермонт, МА — Массачусетс, СТ — Коннектикут, WE — Мэн, NH — Нью-Гэмпшир, RI — Род-Айленд.)
Тема. Напишите программу, раскрашивающую карту в минимальное число цветов. Исходными данными служит список регионов с указанием соседей каждого региона. Результатом должен быть список регионов с приписанными им цветами и общее число использованных цветов. Обычно проще всего для обозначения регионов и цветов применить положительные числа, но куда приятнее (и полезнее для отладки), если допускается ввод более привычных названий. Исходные данные должны проверяться на непротиворечивость; выявляйте нелепые номера вершин и связанные с собой вершины. Постарайтесь сделать программу по возможности эффективной, иначе раскраска тяжелых случаев окажется для вас слишком дорогим удовольствием.
Указания исполнителю. Исходная карта не обязана быть планарной. В самом деле, вполне допустимыми крайними случаями служат карты, в которых любые два региона — соседи, и карты, в которых никакие два региона не являются соседями. Последний случай соответствует раскраске множества раздельных шаров, когда достаточно только одного цвета. Проверка планарности — важная тема информатики, ей посвящено немало статей. Возможно, вас заинтересует проверка гипотезы о четырех красках, утверждающей, что для любой планарной карты требуется не более четырех красок. Если вам удастся подтвердить или опровергнуть ее, вы сделаете себе имя[7].
Из ресурсов, требуемых данной задачей, самый важный — время. Конечно, нет смысла перебирать все возможные решения, поскольку их число быстро увеличивается с ростом числа регионов, а доля правильных решений (даже если таковых несколько) мала. Лучше воспользоваться методом перебора с возвратами. Начните с выбора некоторого региона и приписывания ему цвета. В дальнейшем переходите к соседнему нераскрашенному региону и пытайтесь приписать ему какой-нибудь из использованных цветов, совместимый с уже сделанной раскраской. (Может случиться, что раскрашивать больше нечего, тогда задача решена. Возможен и случай, когда не осталось нераскрашенных регионов, соседних с раскрашенными, т. е. попалась несвязная карта.) Если в некоторый момент новый регион не удается раскрасить, отступайте от уже раскрашенных регионов (в соответствии с порядком раскраски) до тех пор, пока не найдется регион, цвет которого можно изменить. Раскрасьте его в цвет, которого он ранее не имел, и снова продвигайтесь вперед. Если при отступлении вы возвратились в регион, раскрашенный первым, добавьте к своей палитре новый цвет и начните сначала.
Инструментовка. Для решения задачи достаточно таких структур данных, как массивы и стеки, поэтому годится почти любой алгебраический язык высокого уровня с подходящими управляющими структурами. (Попытки записи решения на Фортране или Бейсике должны показать скудость этих языков.) С другой стороны, перебор с возвратами выглядит элегантно в рекурсивной формулировке. Поэтому, возможно, полезным окажется язык с рекурсивными процедурами. И рекурсия, и подходящие структуры данных имеются в языке Лисп.
Длительность исполнения. Одному исполнителю на 1 неделю.
Развитие темы. При использовании метода перебора с возвратами огромное влияние на время работы оказывает порядок выбора регионов. Учитывая этот эффект, можно заранее упорядочить регионы или использовать некоторые эвристики для выбора очередного региона. По-видимому, те регионы, у которых много соседей, раскрасить труднее, поскольку на их цвет накладывается больше ограничений. Из тех же соображений почти изолированную группу регионов следует рассмотреть отдельно, так как если ее не удастся раскрасить некоторым набором цветов, то и всю карту — тоже. Идея в обоих случаях состоит в том, что, если раскраска какого-либо региона может вызвать затруднения, ее нужно выполнить пораньше, чтобы не тратить время на разрушение почти законченной раскраски. Разумеется, полное решение такой «предварительной» задачи равносильно решению исходной задачи, но ведь и небольшой вклад может принести вполне ощутимую прибыль. Сравните несколько стратегий предварительного упорядочения по стоимости и эффекту.
Литература
Битнер, Рейнгольд (Bitner J. R., Reingold E. M.). Backtrack Programming Techniques. С ACM, 18, 11, pp. 651–656, November 1975. Эта статья — очень краткое руководство по программированию методом перебора с возвратами. Но если приведенных авторами примеров окажется недостаточно, чтобы вы поняли суть метода, к вашим услугам обширная библиография по проблемам, которые решены методом перебора с возвратами или которые целесообразно этим методом решать. Ope (Ore О.). The Four Color Problem. Academic Press, New York, 1967. В книге дан обзор математических вопросов, связанных с гипотезой четырех красок. По ней можно ознакомиться со многими разделами теории графов; можно почерпнуть и способ ускорения перебора с возвратами. Но не пытайтесь найти в книге быстрого алгоритмического решения. *Ершов А. П. Введение в теоретическое программирование. — М.: Наука, 1977. *Абрамов С. А. Математические построения и программирование. М.: Наука, 1978. *Харари Ф. Теория графов, гл. 12. Пер. с англ. — М.: Мир, 1973.4. Печатник-подмастерье, или Автоматическое форматирование текста
Известно вам или нет, но с недавних пор еще одно тяжкое бремя свалилось с плеч человечества. Заботу о создании и размещении опечаток в тексте взяли на себя компьютеры. Там, где раньше линотипы отливали горячий свинец в строки, теперь небольшие, вполне доступные по цене компьютеры методами фотонабора выдают нескончаемые потоки готовых текстов. Жаль только, что с появлением новых эффективных методов уходит очарование доброго старого времени. Ну какой, скажите, интерес выискивать опечатки в воскресном номере Нью-Йорк Таймс, в которых и заключается весь юмор этого обширного собрания важных скучностей, если вы знаете, что компьютер способен делать ошибки в сотни раз быстрее, чем человек? Такова цена, которую приходится платить за прогресс. Конечно, реальный прогресс заключен в том, что в издательском деле компьютер привлекается в качестве подмастерья, некоего чудесного помощника, способного выполнять черную работу быстро и — при аккуратном программировании — почти бесплатно. Программисты уже пользуются руководствами по вычислительной технике, изданными при помощи ЭВМ. Такие руководства часто очень неудобны для чтения из-за неудачного шрифта, которым снабжено печатающее устройство машины. Однако большинство людей и не подозревает, что многие журналы, газеты и книги также печатаются с помощью ЭВМ. Они выглядят гораздо привлекательнее благодаря тому, что машина не только редактирует и соответствующим образом располагает текст, но и управляет специальными периферийными фотонаборными устройствами. Последние, обладая десятками шрифтов различной гарнитуры, выдают готовую к изданию продукцию. Черновик настоящей книги также был подготовлен при помощи такой системы, и первые читатели были уверены, что держат в руках фотокопию реальной книги, а вовсе не некий аналог обычного машинописного экземпляра. Система подготовки публикаций состоит из четырех компонентов. Во-первых, необходима хорошая файловая система, в которой можно хранить готовящиеся и архивные текстовые файлы. Обычно память для хранения файлов предоставляется операционной системой, но известен случай, когда в качестве такой памяти использовался шкаф для перфокарт вкабинете автора. Конечно, перфокарты не самый практичный носитель, когда речь идет об операциях над большими объемами информации, например при издании газет. Во-вторых, нужен редактор текстов, для того чтобы вносить изменения и поправки в файлы перед выдачей на печать. Редакторы текстов также имеются, в большинстве операционных систем, но может понадобиться специальный редактор издания, обладающий именно теми возможностями, которые требуются при подготовке публикаций. Третий элемент — форматор, который умеет размещать заголовки, выбирать размер страницы, располагать материал в таблицах, выделять абзацы и т. п. Форматор работает с такими элементами текста, как слова, предложения, абзацы, т. е. уже на том уровне, на котором текст воспринимается человеком. Наконец, имеется программа-наборщик, которая преобразует форматированный текст в его образ на внешнем носителе. Работа этой программы связана в первую очередь с особенностями шрифтов, физическими размерами, командами выводного устройства, отдельными литерами и тому подобными вещами. Программа-наборщик, так же как и оператор линотипа, готова выдать на печать любой вздор, лишь бы он поместился в отведенное ему место. Функционально файловая система и редактор текстов заботятся о содержании текста, а форматор и наборщик — о том, как он будет выглядеть. Этот этюд посвящен форматированию[8] текстов.Форматор
Процесс форматирования текста вручную проходит несколько этапов. Вначале автор создает черновик рукописи, и он перепечатывается набело. Затем автор вместе с редактором (по крайней мере, когда речь идет о больших публикациях) принимаются терзать эту рукопись, пока там не останется живого места, после чего автор начинает работу над новым вариантом рукописи. Этот цикл повторяется до тех пор, пока и автор, и редактор не будут удовлетворены. Затем рукопись еще раз перепечатывается (как правило, через два интервала) и передается техническому редактору. Он размечает рукопись, давая всевозможные указания относительно наборных шрифтов, размера и расположения заголовков, полосы набора, курсива и прочих деталей, определяющих в конечном счете внешний вид издания. Разметка делается при помощи специальных обозначений, и каждый значок ставится в то место рукописи, к которому он относится. Размеченная рукопись отправляется в наборный цех, где текст набирают и делают корректурный оттиск в нескольких экземплярах, называемый версткой. Верстка возвращается в редакцию, где редактор и корректор сверяют ее с окончательным вариантом рукописи. Мелкие ошибки легко исправить в наборном цехе, заменив одну строку набора другой. Но как быть, если автор вдруг решит, что вся четвертая глава никуда не годится, или художнику покажется, что гарнитура бодони будет выглядеть лучше литературной? Такие изменения повлекут за собой новый набор и обойдутся недешево. Можно только диву даваться, насколько по-разному воспринимаются типографский текст и тот же текст, напечатанный на машинке. Система подготовки публикаций с помощью ЭВМ исключает из этого цикла большую часть работы и множество людей. Как и прежде, автор должен подготовить первоначальный вариант рукописи. Но затем рукопись поступает не в машинописное бюро, а в файловую систему машины. Текст рукописи можно ввести, как и любую информацию для ЭВМ, либо с перфокарт, либо непосредственно через терминальное устройство машины. (Большая часть этой рукописи была отперфорирована.) Автор исполняет также и функции технического редактора, сопровождая текст простейшими командами для форматора. Текстовый файл с рукописью обрабатывается форматором и наборщиком, в результате чего получается черновая верстка окончательного печатного текста. Эта черновая верстка выглядит куда как более чисто, чем машинописный вариант, — она оформлена в виде отпечатанных типографским способом страниц с правильными номерами, радующим глаз шрифтом и т. п. Заметим, что все это происходит еще до начала какого-либо пересмотра рукописи. Затем автор и редактор начинают работать над рукописью. Интеллектуальная часть работы точно такая же, как и раньше, но теперь им значительно проще представить себе конечный результат, поскольку рукопись выглядит почти как готовое печатное издание. Да и процесс редактирования уже не такой трудоемкий. Для того чтобы добавить или убрать фразу, не нужно ничего перепечатывать — все изменения вносятся при помощи редактора текстов, подобно тому как заменяются строки в программах. Переупорядочение больших разделов, а также вызов текстов, временно отсутствующих в основной памяти, осуществляется средствами файловой системы. Поскольку текст в любом случае придется переформатировать, то можно поменять и команды форматора, тоже просто изменив содержимое текстового файла. Наконец, выполнение программы форматора на ЭВМ стоит такие пустяки, что все множество сеансов форматирования текста обойдется наверняка несравненно дешевле, чем одна перепечатка его на машинке при старом способе работы. Имеется, правда, единственное опасение — авторы, зачарованные столь аккуратно оформленной рукописью, будут неохотно вносить в нее изменения; ведь в течение долгих лет за всякое исправление в верстке, противоречащее рукописи, им приходилось расплачиваться из авторского гонорара. Поэтому если мы хотим правильно использовать ЭВМ для подготовки публикаций, то и авторов необходимо должным образом перестроить[9].Команды форматирования
Как работает типичный форматор? В исходном файле текст, предназначенный для редактирования, оформлен как обычная машинопись (с той разницей, что здесь не нужно заботиться об интервале, полях и т. п.) с добавленными командами форматирования. Команды должны располагаться с первой позиции записи и начинаться со знака «?», чтобы их можно было отличить от обычного текста, по крайней мере в нашем примере. Для самого простого вывода достаточно иметь команды для установки размера страницы и для разбиения текста на абзацы. В пределах одного абзаца исходный текст можно вывести в одном из трех режимов: Неплотный — строки исходного текста передаются на вывод в том виде, в котором они записаны в исходном файле. Этот режим обычно используется для выдачи таблиц и других заранее оформленных материалов без каких бы то ни было изменений. Плотный — строки вывода формируются из исходного текста слева направо наиболее плотным образом, переход на следующую строку происходит только тогда, когда очередное слово исходного текста не помещается в предыдущей строке вывода. Между словами оставляется один пробел, а после символов конца предложения, т. е. после точки, вопросительного и восклицательного знаков, дается два пробела. Именно в этом режиме обычно печатается текст на машинке. Заметим, что в плотном режиме избыточные пробелы между словами исходного текста игнорируются, пробелы служат только для разделения слов исходного текста. Выравнивание — сначала из исходного текста формируется полный абзац в плотном режиме. Затем в каждую строку, кроме последней, добавляются пробелы между словами так, чтобы последнее слово заканчивалось у правого края страницы. Ни в один промежуток нельзя добавить (n + 1)-й пробел, пока во всех остальных промежутках данной строки не стало по n пробелов, а пробел после символа конца предложения можно добавить, лишь если во всех других промежутках строки уже есть по два пробела. Пробелы следует добавлять в случайно выбираемые промежутки между словами; если пробелы вставлять по какому-нибудь заранее выбранному правилу, то в выводном тексте образуются неприятные для глаза белые полосы. Выровненный текст по внешнему виду приближается к книжному, но не так совершенен, поскольку не учитываются неодинаковые размеры букв. Для обработки простого текста достаточно иметь команды ?размер, ?абзац и ?режим. Действие этих команд продемонстрировано на рис. 4.1 и 4.2. Рисунок 4.1. Пример необработанного исходного текста.
Рисунок 4.1. Пример необработанного исходного текста.
 Рисунок 4.2. Тот же текст после форматирования.
?размер высота ширина
Команда ?размер устанавливает размер страниц текста; страница измеряется аргументами высота, равным количеству строк, и ширина, равным количеству литер в каждой строке. Как только выведены очередные строки в количестве высота штук, форматор начинает новую страницу. Выводные строки могут заполнять все пространство между колонками с номерами 1 и ширина. Новую команду ?размер можно выдать в любом месте текста, но она приводит к автоматическому завершению текущего абзаца. Формирование прерванного абзаца завершается со старыми значениями высота и ширина, а затем начинают действовать новые значения. Изменение размера страницы может привести также к переходу на новую страницу, если новое значение высота меньше прежнего. В начале сеанса форматирования значение высота равно 40, а ширина — 72, и если пользователя эти значения устраивают, то команда ?размер необязательна.
?режим тип заполнения
Команда ?режим устанавливает режим обработки выводимого текста. Аргумент тип заполнения может принимать в качестве значения одну из цепочек: неплотный, плотный или выравнивание (другие значения не допускаются). По команде ?режим текущий абзац прерывается, но его обработка завершается в прежнем режиме. В начале работы установлен плотный режим; если пользователя это устраивает, то команда ?режим необязательна.
?абзац отступ отбивка
По команде ?абзац начинается новый абзац. Первая строка нового абзаца начинается на отступ позиций правее левого поля (отступ может быть нулевым, а позже вы увидите также, что он может быть отрицательным), а между предыдущим и новым абзацем оставляются пустые строки, количество которых задает аргумент отбивка. Если не указана отбивка или отбивка и отступ, то их значения берутся из последней команды ?абзац, где они были указаны. Начальное значение отступ равно 3, а отбивка — 0; если эти значения удовлетворительны, то в команде ?абзац можно не указывать аргументы. Заметим, что при значении отступ, равном 3, первая строка нового абзаца начинается в колонке 4.
Но команд ?размер, ?режим и ?абзац недостаточно. Полный форматор должен включать по меньшей мере еще следующие команды.
?поле слева справа
Команда ?поле указывает, что выводимый текст будет иметь левое и правое поля, начинающиеся в колонках слева и справа. Естественно, что левое поле должно начинаться в колонке с номером 1 или более, а правое — в колонке с номером не больше текущего значения ширина страницы. По команде ?поле начинается новый абзац. С введением полей приобретает смысл отрицательный аргумент отступ в команде ?абзац; первая строка нового абзаца начинается с выступом относительно левого края страницы.
?интервал отбивка
Команда ?интервал устанавливает, что между строками вывода нужно оставлять отбивка − 1 пустых строк. Установка значения отбивка, равного 1, соответствует указанию для машинистки печатать через один интервал. Отбивка 2 соответствует печати через два интервала, отбивка 3 — через три интервала и т. д. Эта команда прерывает текущий абзац.
?пусто n
По команде ?пусто завершается текущий абзац, выводится n пустых строк с текущим значением интервала между строками. Эта команда по своему действию эквивалентна (n + 1) возвратам каретки на пишущей машинке. Если из-за вывода пустых строк происходит переход на следующую страницу, то новая страница действительно начинается, но пустые строки в начале страницы не выводятся. По умолчанию значение n нулевое.
?пропуск n
Команда ?пропуск работает так же, как ?пусто, но выводится точно n пустых строк; текущее значение аргумента команды ?интервал не учитывается. Это действие эквивалентно повороту валика пишущей машинки на n + 1 интервалов.
?центр
Команда ?центр выбирает из входного текста очередную строку, убирает из нее лишние пробелы и центрирует то, что получилось, между левым и правым полями следующей выводной строки. Текущий абзац не заканчивается, но перед центрируемой строкой может получиться более короткая строка. Центрируемая строка выводится с текущим интервалом. Если центрируемая строка слишком длинная и не помещается между установленными полями, то имеет место ошибка.
?страница
По этой команде прерывается текущий абзац и после вывода последней строки абзаца происходит переход на новую страницу выводного текста.
?остаток n
По этой команде текущий абзац завершается и выводится. Если в текущей странице осталось меньше чем n пустых строк, то команда ?остаток действует как ?страница. В противном случае она игнорируется. Таким образом, эта команда проверяет, осталось ли еще достаточно места в текущей странице.
?колонтитул глубина место позиция
Команда ?колонтитул устанавливает текст колонтитула, который будет печататься сверху на каждой странице, начиная со следующей. Последующие глубина строк исходного текста запоминаются без изменений и выводятся в качестве колонтитула в верхние глубина строк каждой новой страницы. В строке номер место печатается номер страницы слева, справа или в центре, в зависимости от значения аргумента позиция, который может быть одной из цепочек: слева, справа или центр. Страницы нумеруются числами, начиная с единицы, при переходе к следующей странице номер увеличивается на 1. При выводе колонтитула используются те значения полей, которые действовали в момент задания колонтитула. Колонтитул можно отменить при помощи команды ?колонтитул с нулевым значением аргумента глубина. Команда ?колонтитул не прерывает текущий абзац.
?номер n
По команде ?номер номер текущей страницы устанавливается равным n; текущий абзац не прерывается.
?прерывание
Команда ?прерывание означает переход к новому абзацу.
?сноска глубина
По команде ?сноска следующие глубина строк, включая команды, помещаются в конце страницы в качестве сноски. Значения управляющих параметров форматора — поля, интервал и т. д. — сохраняются и затем используются в качестве начального состояния при обработке сноски. Из исходного файла после сноски выбирается достаточное количество слов для заполнения той строки, которая обрабатывалась, когда встретилась команда ?сноска. Затем обрабатывается сноска и помещается в конец страницы. Если в текущей странице уже были сноски, то они выталкиваются в верхние строки, освобождая место для новой сноски. Если при этом сноски начинают наезжать на уже сформатированные строки текущей страницы, то страница завершается, а остаток сноски попадает на следующую страницу (именно поэтому сначала заполняется текущая строка основного текста, а уж потом начинается обработка сноски). После вывода глубина строк сноски продолжается обработка основного текста с прежними значениями управляющих параметров форматора (хотя номер страницы мог уже измениться), Очевидно, что команда ?сноска не должна прерывать текущий абзац и не может находиться внутри другой сноски.
?имя фиктивное настоящее
Эта команда сообщает форматору, что впредь до следующей команды ?имя вместо литеры, имеющей настоящее имя будет использоваться литера, имеющая фиктивное имя. Каждый раз перед выдачей строки на печать все фиктивные литеры заменяются соответствующими настоящими литерами. Например, пробелы используются специальным образом для разделения слов; при помощи команды ?имя можно включить в выводной текст пробелы, не разрывая при этом слов. Команда ?имя не прерывает текущий абзац. Все переименования можно отменить, выдав команду ?имя без аргументов.
Рисунок 4.2. Тот же текст после форматирования.
?размер высота ширина
Команда ?размер устанавливает размер страниц текста; страница измеряется аргументами высота, равным количеству строк, и ширина, равным количеству литер в каждой строке. Как только выведены очередные строки в количестве высота штук, форматор начинает новую страницу. Выводные строки могут заполнять все пространство между колонками с номерами 1 и ширина. Новую команду ?размер можно выдать в любом месте текста, но она приводит к автоматическому завершению текущего абзаца. Формирование прерванного абзаца завершается со старыми значениями высота и ширина, а затем начинают действовать новые значения. Изменение размера страницы может привести также к переходу на новую страницу, если новое значение высота меньше прежнего. В начале сеанса форматирования значение высота равно 40, а ширина — 72, и если пользователя эти значения устраивают, то команда ?размер необязательна.
?режим тип заполнения
Команда ?режим устанавливает режим обработки выводимого текста. Аргумент тип заполнения может принимать в качестве значения одну из цепочек: неплотный, плотный или выравнивание (другие значения не допускаются). По команде ?режим текущий абзац прерывается, но его обработка завершается в прежнем режиме. В начале работы установлен плотный режим; если пользователя это устраивает, то команда ?режим необязательна.
?абзац отступ отбивка
По команде ?абзац начинается новый абзац. Первая строка нового абзаца начинается на отступ позиций правее левого поля (отступ может быть нулевым, а позже вы увидите также, что он может быть отрицательным), а между предыдущим и новым абзацем оставляются пустые строки, количество которых задает аргумент отбивка. Если не указана отбивка или отбивка и отступ, то их значения берутся из последней команды ?абзац, где они были указаны. Начальное значение отступ равно 3, а отбивка — 0; если эти значения удовлетворительны, то в команде ?абзац можно не указывать аргументы. Заметим, что при значении отступ, равном 3, первая строка нового абзаца начинается в колонке 4.
Но команд ?размер, ?режим и ?абзац недостаточно. Полный форматор должен включать по меньшей мере еще следующие команды.
?поле слева справа
Команда ?поле указывает, что выводимый текст будет иметь левое и правое поля, начинающиеся в колонках слева и справа. Естественно, что левое поле должно начинаться в колонке с номером 1 или более, а правое — в колонке с номером не больше текущего значения ширина страницы. По команде ?поле начинается новый абзац. С введением полей приобретает смысл отрицательный аргумент отступ в команде ?абзац; первая строка нового абзаца начинается с выступом относительно левого края страницы.
?интервал отбивка
Команда ?интервал устанавливает, что между строками вывода нужно оставлять отбивка − 1 пустых строк. Установка значения отбивка, равного 1, соответствует указанию для машинистки печатать через один интервал. Отбивка 2 соответствует печати через два интервала, отбивка 3 — через три интервала и т. д. Эта команда прерывает текущий абзац.
?пусто n
По команде ?пусто завершается текущий абзац, выводится n пустых строк с текущим значением интервала между строками. Эта команда по своему действию эквивалентна (n + 1) возвратам каретки на пишущей машинке. Если из-за вывода пустых строк происходит переход на следующую страницу, то новая страница действительно начинается, но пустые строки в начале страницы не выводятся. По умолчанию значение n нулевое.
?пропуск n
Команда ?пропуск работает так же, как ?пусто, но выводится точно n пустых строк; текущее значение аргумента команды ?интервал не учитывается. Это действие эквивалентно повороту валика пишущей машинки на n + 1 интервалов.
?центр
Команда ?центр выбирает из входного текста очередную строку, убирает из нее лишние пробелы и центрирует то, что получилось, между левым и правым полями следующей выводной строки. Текущий абзац не заканчивается, но перед центрируемой строкой может получиться более короткая строка. Центрируемая строка выводится с текущим интервалом. Если центрируемая строка слишком длинная и не помещается между установленными полями, то имеет место ошибка.
?страница
По этой команде прерывается текущий абзац и после вывода последней строки абзаца происходит переход на новую страницу выводного текста.
?остаток n
По этой команде текущий абзац завершается и выводится. Если в текущей странице осталось меньше чем n пустых строк, то команда ?остаток действует как ?страница. В противном случае она игнорируется. Таким образом, эта команда проверяет, осталось ли еще достаточно места в текущей странице.
?колонтитул глубина место позиция
Команда ?колонтитул устанавливает текст колонтитула, который будет печататься сверху на каждой странице, начиная со следующей. Последующие глубина строк исходного текста запоминаются без изменений и выводятся в качестве колонтитула в верхние глубина строк каждой новой страницы. В строке номер место печатается номер страницы слева, справа или в центре, в зависимости от значения аргумента позиция, который может быть одной из цепочек: слева, справа или центр. Страницы нумеруются числами, начиная с единицы, при переходе к следующей странице номер увеличивается на 1. При выводе колонтитула используются те значения полей, которые действовали в момент задания колонтитула. Колонтитул можно отменить при помощи команды ?колонтитул с нулевым значением аргумента глубина. Команда ?колонтитул не прерывает текущий абзац.
?номер n
По команде ?номер номер текущей страницы устанавливается равным n; текущий абзац не прерывается.
?прерывание
Команда ?прерывание означает переход к новому абзацу.
?сноска глубина
По команде ?сноска следующие глубина строк, включая команды, помещаются в конце страницы в качестве сноски. Значения управляющих параметров форматора — поля, интервал и т. д. — сохраняются и затем используются в качестве начального состояния при обработке сноски. Из исходного файла после сноски выбирается достаточное количество слов для заполнения той строки, которая обрабатывалась, когда встретилась команда ?сноска. Затем обрабатывается сноска и помещается в конец страницы. Если в текущей странице уже были сноски, то они выталкиваются в верхние строки, освобождая место для новой сноски. Если при этом сноски начинают наезжать на уже сформатированные строки текущей страницы, то страница завершается, а остаток сноски попадает на следующую страницу (именно поэтому сначала заполняется текущая строка основного текста, а уж потом начинается обработка сноски). После вывода глубина строк сноски продолжается обработка основного текста с прежними значениями управляющих параметров форматора (хотя номер страницы мог уже измениться), Очевидно, что команда ?сноска не должна прерывать текущий абзац и не может находиться внутри другой сноски.
?имя фиктивное настоящее
Эта команда сообщает форматору, что впредь до следующей команды ?имя вместо литеры, имеющей настоящее имя будет использоваться литера, имеющая фиктивное имя. Каждый раз перед выдачей строки на печать все фиктивные литеры заменяются соответствующими настоящими литерами. Например, пробелы используются специальным образом для разделения слов; при помощи команды ?имя можно включить в выводной текст пробелы, не разрывая при этом слов. Команда ?имя не прерывает текущий абзац. Все переименования можно отменить, выдав команду ?имя без аргументов.
Несколько слов о словах, буквах и аргументах
Для того чтобы правильно заполнять строки и выравнивать текст, форматор должен уметь распознавать слова и предложения. Со словами все просто — любая цепочка литер без пробелов, заканчивающаяся пробелом или концом записи, является словом. Заметим, что по этому определению знаки препинания входят в состав предшествующего слова. Предложение обычно заканчивается точкой, а в конце предложения, как правило, вместо одного пробела оставляется два. Но ведь точка может стоять внутри скобок или кавычек, а после двоеточия правилами предусматривается два пробела. Поэтому слова, заканчивающиеся литерами . ? ! .) ?) !) ." ?" !" .") ?") !") : следует считать концом предложения. Могут быть также и другие варианты, которые здесь не упомянуты; авторы часто весьма вольно обращаются с пунктуацией. Если ваш форматор будет работать в системе разделения времени, которая умеет вводить прописные и строчные буквы и допускает вывод на терминал, то, несомненно, алфавит языка, на котором реализован форматор, должен включать большие и малые буквы. Но если вы работаете в системе, ориентированной на ввод с перфокарт, то у вас возникнут трудности с чтением букв двух видов, поскольку на перфораторах, как правило, отсутствует переключатель регистров (лучше, если системе все-таки удастся каким-то образом печатать буквы обоих видов, иначе ваше начинание обречено на провал). Для ввода с перфокарт выберите какую-нибудь литеру, например ↑, которая будет служить признаком прописной буквы. Так, текст Машина БЭСМ-6 нужно перфорировать как ↑машина ↑б↑э↑с↑м-6 Прописные буквы отмечаются специальным образом, поскольку они встречаются значительно реже строчных. Заметим, что буквы, отперфорированные обычным образом, считаются строчными, хотя на перфокартах они выглядят как прописные. Аргументы команд могут быть двух видов. Некоторые аргументы представляют собой целые числа и задают либо значения управляющих параметров для форматора, либо число строк исходного текста, относящихся к этой команде. Другие аргументы являются словами или отдельными литерами, которые непосредственно используются в команде. Аргументы обоих видов разделяются пробелами, избыточные пробелы игнорируются, В команде ?имя второй аргумент может отсутствовать, тогда считается, что он равен пробелу (иначе при данных соглашениях пробел представить трудно). Следует позаботиться о том, чтобы для неправильных команд выдавались сообщения об ошибках. Тема. Напишите для вашей системы форматор текстов, понимающий описанные выше команды. Поскольку форматирование текста не имеет большого смысла без возможности вывода прописных и строчных букв, то следует использовать выводное устройство с буквами обоих видов. Скорее всего, такое устройство окажется довольно дорогим, и вы не сможете позволить себе достаточное количество тестовых пусков. И хотя, естественно, вы рассчитываете, что у вас с первого же раза все правильно заработает, полезно все же уметь делать тестовые выдачи, по форме аналогичные вводу с перфокарт. Такие выдачи можно делать на обычном АЦПУ. Указания исполнителю. Вы обнаружите, вероятно, что ваша программа тратит большую часть времени на ввод и вывод и совсем немного времени — на перемещение слов в строке. Значительная часть времени обработки будет уходить, по-видимому, на поиск пробелов между словами. С учетом всего этого ясно, что львиную долю усилий по оптимизации программы следует направить на центральный алгоритм сканирования и на взаимодействие форматора с внешним миром. Обработка команд и алгоритм размещения слов должны быть запрограммированы так, чтобы все было понятно. Как правило, для ввода/вывода следует пользоваться стандартными языковыми средствами, но в данной задаче мы сталкиваемся с тем случаем, когда особенности вашей операционной системы можно употребить с пользой для дела. Важно помнить только, что использование этих особенностей должно быть сконцентрировано в пределах подпрограмм ввода-вывода, а не рассеяно по всему форматору. Набор команд был подобран с таким расчетом, чтобы требуемый вывод можно было получить за один просмотр входных данных. Ни для одной команды алгоритм не должен требовать повторного просмотра ввода. Если для некоторых алгоритмов потребуется рабочее пространство, как, например, для алгоритма обработки сноски, то попробуйте применить двойную буферизацию вывода и использовать свободный буфер в качестве рабочего пространства. Для оценки времени работы укажем, что форматор, с помощью которого был получен английский оригинал настоящего издания, тратил на одну страницу вывода примерно 2 с времени ЦП, а написан он был на некоем диалекте языка Трак (см. гл. 28). Да и большинство других форматоров тратит на оформление каждой страницы вывода тоже примерно 1–2 с независимо от скорости ЭВМ, на которой они работают. Единственное разумное объяснение этому факту — то, что пользователи находят такую скорость приемлемой, и программисты соответственно не считают нужным тратить усилия на ускорение форматоров. Инструментовка. В простейшем варианте эта задача традиционно входит в курсы по Сноболу, но думается, что большинство снобольных реализаций окажутся слишком медленными для практического использования. С другой стороны, язык, не имеющий хотя бы простейших средств для обработки текстов, будет в лучшем случае не слишком удобным. Золотой серединой, пожалуй, был бы язык типа XPL или BLISS. На многих машинах имеются стандартные средства для обработки текстов, например для поиска пробелов, для разбиения цепочек, для сравнения цепочек. Поэтому, для того чтобы извлечь выгоду из этих средств, разумно самые внутренние циклы писать на языке ассемблера. Длительность исполнения. Одному исполнителю на 4 недели. Развитие темы. В этой книге можно встретить полужирный шрифт, курсив, греческие буквы, латинские рукописные и другие специальные символы. Все это имелось на выводных устройствах, но, как нетрудно догадаться, ни перфораторы, ни файловая память подобными возможностями не обладают. Для представления таких специальных литер используются специальные соглашения. Пусть, например, слова “et cetera” требуется набрать курсивом. Для этого нужно ввести текст “&i+ et cetera &i−”, и тогда на выводе получится “et cetera”. Тройка литер, начинающаяся значком “&”, называется переключателем шрифта. В данном примере вы видели включение и выключение курсива[10]. Рассматривая подчеркивания, верхние и нижние индексы и т. п. как специальные начертания шрифтов, можно таким образом обеспечить доступ ко всем дополнительным средствам, имеющимся на вашем устройстве вывода. Разумеется, можно включить одновременно несколько переключателей, например чтобы вывести подчеркнутые греческие верхние индексы. (Возможно, вам понадобится также переключатель шрифта для возвратов по тексту вида & × n, где n — цифра от 1 до 9.)Литература
Керниган, Черри (Kernighan B. W., Cherry L. L.). A System for Typesetting Mathematics, CACM, 18, 3, pp. 151–157, 1975. В этой статье описывается только система для набора математических формул, но система встроена в форматор текстов общего назначения. Сама статья, как, сообщается в журнале САСМ, является фотокопией с результата работы форматора и для публикации повторно не набиралась. Керниган и Черри, между прочим, продают свою систему. Керниган, Плоджер (Kernighan В. W., Plouger P. J.). Software Tools. Addison-Wesley, Reading MA, 1976. В книге Кернигана и Плоджера обсуждаются системы программного обеспечения, которые могут оказаться полезными при работе над большим (а пожалуй, и любым) проектом. Каждое такое средство, как и в этих этюдах, сначала обрисовывается в общих чертах, а затем формулируется в виде проекта. Одно из описываемых средств — форматор текстов. Даются также некоторые указания по реализации. Возможно, прежде чем браться за этот этюд, вы захотите сравнить свойства двух форматоров. *Баяковский Ю. М., Мишакова С. Т. Автоматизированная система подготовки публикаций и документов (АСПИД), ИПМ АН СССР им. М. В. Келдыша. Препринт № 19, 1977. Система АСПИД написана на Фортране и на машине БЭСМ-6 тратит на подготовку страницы вывода также около 2 с.5 Победителей судят, или Составление и оценка турнира
Едва ли не каждый из нас в свое время был болельщиком местной, чуть ли не самой сильной команды. Состоявшийся в конце сезона турнир должен был выявить чемпиона города, округа, штата, страны, мира или Вселенной. Но какое невезение — местные герои проиграли будущему победителю уже в первом круге турнира с немедленным выбыванием. Игра оказалась малоинтересной — никто даже не успел размяться. И ведь как обидно: самые настоящие слабаки в итоге занимают место, которое по праву должно принадлежать нашим парням, а болельщиков вместо волнующей борьбы в финале ждет убогое зрелище. А виноват во всем турнир с немедленным выбыванием. Пусть имеется 2n команд, n > 0. Тогда в первом круге команда 1 играет с командой 2, команда 3 с командой 4, …, команда 2n − 1 с командой 2n. Проигравшие вылетают, а победители выходят в следующий круг. Рисунок 5.1. Простой турнир с немедленным выбыванием. Окончательное упорядочение, как это определено в тексте, имеет вид 1, 3, 5, 2, 8, 6, 4, 7.
На рис. 5.1 изображен турнир восьми команд. Если предположить, что более сильная команда всегда выигрывает (т. е. что не бывает срывов), лучшая команда, очевидно, завоюет первое место. Однако второй участник финальной игры может занимать в общей табели о рангах лишь место 2n−1 + 1 при условии, что все более сильные команды оказались в одной группе с победителем. Победитель по мере своего продвижения выведет из розыгрыша хорошие команды, и слабой команде достанутся совсем никудышные соперники. Избежать подобной ситуации можно несколькими способами. Во-первых, команды (в дальнейшем будем называть их соперниками) можно рассеять, чтобы сильные соперники (оценка дается по итогам предыдущих выступлений) разместились по всей турнирной сетке. Например, самый сильный соперник попадает в позицию 1, второй по силе — в 2n−1 + 1, третий — в 2n−1 + 2n−2 + 1, четвертый — в 2n−2 + 1 и т. д. Если предварительная оценка была достаточно точной, сильные соперники не выбьют друг друга в первых кругах. Во-вторых, можно устроить турнир с отложенным выбыванием, когда выбывают после двух поражений. Но на самом деле идеальным решением (хорошо бы еще и практичным!) был бы круговой турнир, в котором все соперники играют друг с другом ровно один раз. В предположении отсутствия срывов сильнейший соперник выиграет 2n − 1 встреч и проиграет 0, второй по силе соответственно 2n — 2 и 1 (уступит лишь сильнейшему), …, а самый слабый — 0 и 2n − 1 (проиграет всем). Трудность в том, что в круговом турнире нужно провести 2n−1(2n − 1) встреч, в то время как в турнире с немедленным выбыванием лишь 2n − 1.
Рисунок 5.1. Простой турнир с немедленным выбыванием. Окончательное упорядочение, как это определено в тексте, имеет вид 1, 3, 5, 2, 8, 6, 4, 7.
На рис. 5.1 изображен турнир восьми команд. Если предположить, что более сильная команда всегда выигрывает (т. е. что не бывает срывов), лучшая команда, очевидно, завоюет первое место. Однако второй участник финальной игры может занимать в общей табели о рангах лишь место 2n−1 + 1 при условии, что все более сильные команды оказались в одной группе с победителем. Победитель по мере своего продвижения выведет из розыгрыша хорошие команды, и слабой команде достанутся совсем никудышные соперники. Избежать подобной ситуации можно несколькими способами. Во-первых, команды (в дальнейшем будем называть их соперниками) можно рассеять, чтобы сильные соперники (оценка дается по итогам предыдущих выступлений) разместились по всей турнирной сетке. Например, самый сильный соперник попадает в позицию 1, второй по силе — в 2n−1 + 1, третий — в 2n−1 + 2n−2 + 1, четвертый — в 2n−2 + 1 и т. д. Если предварительная оценка была достаточно точной, сильные соперники не выбьют друг друга в первых кругах. Во-вторых, можно устроить турнир с отложенным выбыванием, когда выбывают после двух поражений. Но на самом деле идеальным решением (хорошо бы еще и практичным!) был бы круговой турнир, в котором все соперники играют друг с другом ровно один раз. В предположении отсутствия срывов сильнейший соперник выиграет 2n − 1 встреч и проиграет 0, второй по силе соответственно 2n — 2 и 1 (уступит лишь сильнейшему), …, а самый слабый — 0 и 2n − 1 (проиграет всем). Трудность в том, что в круговом турнире нужно провести 2n−1(2n − 1) встреч, в то время как в турнире с немедленным выбыванием лишь 2n − 1.
 Оказавшись между двумя крайностями, выберем компромиссное решение — швейцарскую систему. В первом круге соперник, «посеянный» первым, встречается с последним, второй — с предпоследним и т. д. После каждого круга соперники упорядочиваются в соответствии с набранными очками. Внутри каждой группы (с равным количеством очков) соперники упорядочиваются по среднему числу очков у побежденных ими противников (тем самым ничья не учитывается). В следующем круге соперник, стоящий в описанной классификации на первом месте, встречается с соперником, занимающим наиболее высокое место из тех, с кем он еще не играл. Остальные пары определяются аналогичным образом: соперники должны иметь почти равное количество очков, причем повторные встречи не допускаются. В табл. 5.1 показан возможный трехкруговой турнир по швейцарской системе с восемью участниками. Крупный шахматный деятель Харкнесс утверждает, что турнир по швейцарской системе в
Оказавшись между двумя крайностями, выберем компромиссное решение — швейцарскую систему. В первом круге соперник, «посеянный» первым, встречается с последним, второй — с предпоследним и т. д. После каждого круга соперники упорядочиваются в соответствии с набранными очками. Внутри каждой группы (с равным количеством очков) соперники упорядочиваются по среднему числу очков у побежденных ими противников (тем самым ничья не учитывается). В следующем круге соперник, стоящий в описанной классификации на первом месте, встречается с соперником, занимающим наиболее высокое место из тех, с кем он еще не играл. Остальные пары определяются аналогичным образом: соперники должны иметь почти равное количество очков, причем повторные встречи не допускаются. В табл. 5.1 показан возможный трехкруговой турнир по швейцарской системе с восемью участниками. Крупный шахматный деятель Харкнесс утверждает, что турнир по швейцарской системе в  кругов, где N — число игроков, правильно расставит k + 1 первых игроков (и, из соображений симметрии, k + 1 последних игроков). Швейцарская система справедливее немедленного выбывания и гораздо быстрее круговой. Она позволяет всем соперникам играть в каждом круге. Вопрос состоит в том, как ведут себя подобные турниры в условиях реальных соревнований. Предположим, имеется 2n соперников. Соперник 1 — сильнейший, соперник 2 — второй по силе, …, соперник 2n — слабейший. Для начала проведем круговой турнир, записывая результаты каждого матча. Если встречаются соперники i и j, i < j, положим вероятность победы игрока i равной
1/2 + (j − i)/2n+1.
Тем самым более сильный соперник побеждает с вероятностью, превышающей половину. Упорядочим соперников в соответствии с набранным в круговом турнире количеством очков. Внутри каждой группы команд с равным количеством очков упорядочим их по среднему числу очков, набранных побежденными ими соперниками. Если и здесь наблюдаются совпадения, соперники упорядочиваются по исходным номерам. В результате получается круговая классификация, которую мы будем считать самой «справедливой»; она используется для оценки других способов организации турниров.
Следующий шаг состоит в том, чтобы с одной и той же базой данных провести турниры по швейцарской системе и с немедленным выбыванием. Для разбиения соперников на пары в каждом из этих турниров берутся результаты кругового турнира. Заметьте, что в обоих турнирах два соперника могут встретиться лишь однажды. Швейцарская классификация — это упорядочение после заключительного круга (всего n кругов), причем все оставшиеся неясности разрешаются в соответствии с начальным упорядочением. Затем начните турнир с немедленным выбыванием, составив пары для первого круга случайным образом. В классификации по выбыванию победитель финальной встречи идет первым, побежденный — вторым, и, вообще, проигравшие в i-м круге располагаются перед ранее выбывшими и после всех победивших в i-м и следующих кругах. Внутри группы побежденных в i-м круге соперники располагается в соответствии с итоговыми местами победивших их команд.
Чтобы сравнить эти классификации, используем новую и старую статистики, Старая статистика — это корреляция мест определяемая как
R = 1 − 6
кругов, где N — число игроков, правильно расставит k + 1 первых игроков (и, из соображений симметрии, k + 1 последних игроков). Швейцарская система справедливее немедленного выбывания и гораздо быстрее круговой. Она позволяет всем соперникам играть в каждом круге. Вопрос состоит в том, как ведут себя подобные турниры в условиях реальных соревнований. Предположим, имеется 2n соперников. Соперник 1 — сильнейший, соперник 2 — второй по силе, …, соперник 2n — слабейший. Для начала проведем круговой турнир, записывая результаты каждого матча. Если встречаются соперники i и j, i < j, положим вероятность победы игрока i равной
1/2 + (j − i)/2n+1.
Тем самым более сильный соперник побеждает с вероятностью, превышающей половину. Упорядочим соперников в соответствии с набранным в круговом турнире количеством очков. Внутри каждой группы команд с равным количеством очков упорядочим их по среднему числу очков, набранных побежденными ими соперниками. Если и здесь наблюдаются совпадения, соперники упорядочиваются по исходным номерам. В результате получается круговая классификация, которую мы будем считать самой «справедливой»; она используется для оценки других способов организации турниров.
Следующий шаг состоит в том, чтобы с одной и той же базой данных провести турниры по швейцарской системе и с немедленным выбыванием. Для разбиения соперников на пары в каждом из этих турниров берутся результаты кругового турнира. Заметьте, что в обоих турнирах два соперника могут встретиться лишь однажды. Швейцарская классификация — это упорядочение после заключительного круга (всего n кругов), причем все оставшиеся неясности разрешаются в соответствии с начальным упорядочением. Затем начните турнир с немедленным выбыванием, составив пары для первого круга случайным образом. В классификации по выбыванию победитель финальной встречи идет первым, побежденный — вторым, и, вообще, проигравшие в i-м круге располагаются перед ранее выбывшими и после всех победивших в i-м и следующих кругах. Внутри группы побежденных в i-м круге соперники располагается в соответствии с итоговыми местами победивших их команд.
Чтобы сравнить эти классификации, используем новую и старую статистики, Старая статистика — это корреляция мест определяемая как
R = 1 − 6  (хi − yi)2/(N3 − N),
где xi — место соперника i в одной классификации, уi — место в другой классификации, N — общее число соперников (в данном случае 2n). Другая статистика подсчитывает совпадения и определяется как
М = maxi (∀j) (j ≤ i ⊃ хj = уj).
Тем самым М равно максимальному числу мест (считая от сильнейших к слабейшим), в которых обе классификации в точности совпадают. Статистика R характеризует близость двух классификаций в целом, а M — совпадение верхних частей классификаций[11].
Тема. Напишите программу, читающую исходное значение n, проводящую каждый из трех турниров для 2n соперников и вычисляющую статистики R и M для каждой из трех пар классификаций. Проведите эксперимент большое число раз с постоянным значением n и подсчитайте средние значения M и R. Сравните, какая из двух систем — швейцарская или с немедленным выбыванием — лучше повторяет результаты кругового турнира.
Указания исполнителю. Разумеется, нужно досконально разбираться в разных системах проведения турниров, нужно эффективно программировать подбор пар. Но не упустите из виду еще один момент. Размеры кругового турнира заставляют эффективно запрограммировать внутренний цикл и экономно расходовать память для хранения результатов встреч. Разумеется, вам понадобится хороший генератор случайных чисел для определения результатов встреч. Наконец, при швейцарской системе возможны попытки дважды свести одну и ту же пару соперников, поэтому либо докажите, что такого не произойдет, либо измените алгоритм, избегая повторных встреч, но подчиняясь общему правилу: старайтесь сводить в пары соперников, набравших почти равное количество очков.
Инструментовка. Годится алгебраический процедурный язык с хорошими управляющими структурами цикла. Возможно, подойдет и APL или другой язык обработки массивов, если только вы сумеете так организовать турниры, чтобы стала выгодной параллельная обработка всех соперников.
Длительность исполнения. Одному исполнителю на 2 недели.
Развитие темы. Большинство расширений включает более подробный анализ и сравнение систем проведения турниров. Во-первых, заметьте, что нижняя часть классификации по итогам турнира с немедленным выбыванием носит довольно произвольный характер. Кроме того, соперникам, попавшим в эту часть классификации, весьма тоскливо, ибо они рано вылетели. Для утешения можно организовать турниры с немедленным выбыванием среди неудачников каждого круга. Результаты этих турниров, а не приведенное выше правило, расставят неудачников по местам. Поскольку и в этих побочных турнирах будут проигравшие, организуйте турниры неудачливых неудачников, и так до посинения. Заметьте, что турнир по-прежнему пройдет в n кругов, но теперь все соперники будут участниками всех кругов. Если во всех встречах побеждают сильнейшие, этот, более тщательно организованный турнир превращается в законченный алгоритм сортировки.
Вообще, турниры — это сортировка участвующих в них соперников, хотя правило сравнения и носит вероятностный характер. На основе любого метода сортировки, не нарушающего двух основных правил турниров, можно организовать состязание. Вот основные правила:
1. Ни один из соперников не должен участвовать более чем в одном матче одного круга, а число кругов должно примерно равняться логарифму числа участников.
2. Никакие два соперника не должны встречаться больше одного раза.
Используя изложенные идеи, вы можете оценить и классические способы проведения турниров, такие, как отложенное выбывание, и способы, придуманные вами.
В голову приходит также несколько статистических вопросов. Как влияет частичное или полное рассеивание на турниры с немедленным выбыванием? Как влияет случайная жеребьевка (т. е. случайное составление начальных пар) на ход турниров по швейцарской системе? Каков будет эффект введения иной функции превосходства? Наконец, поскольку для получения итоговой статистики по нескольким экспериментам, видимо, нельзя просто усреднять две наши статистики, спрашивается: какая статистическая операция должна быть использована?
(хi − yi)2/(N3 − N),
где xi — место соперника i в одной классификации, уi — место в другой классификации, N — общее число соперников (в данном случае 2n). Другая статистика подсчитывает совпадения и определяется как
М = maxi (∀j) (j ≤ i ⊃ хj = уj).
Тем самым М равно максимальному числу мест (считая от сильнейших к слабейшим), в которых обе классификации в точности совпадают. Статистика R характеризует близость двух классификаций в целом, а M — совпадение верхних частей классификаций[11].
Тема. Напишите программу, читающую исходное значение n, проводящую каждый из трех турниров для 2n соперников и вычисляющую статистики R и M для каждой из трех пар классификаций. Проведите эксперимент большое число раз с постоянным значением n и подсчитайте средние значения M и R. Сравните, какая из двух систем — швейцарская или с немедленным выбыванием — лучше повторяет результаты кругового турнира.
Указания исполнителю. Разумеется, нужно досконально разбираться в разных системах проведения турниров, нужно эффективно программировать подбор пар. Но не упустите из виду еще один момент. Размеры кругового турнира заставляют эффективно запрограммировать внутренний цикл и экономно расходовать память для хранения результатов встреч. Разумеется, вам понадобится хороший генератор случайных чисел для определения результатов встреч. Наконец, при швейцарской системе возможны попытки дважды свести одну и ту же пару соперников, поэтому либо докажите, что такого не произойдет, либо измените алгоритм, избегая повторных встреч, но подчиняясь общему правилу: старайтесь сводить в пары соперников, набравших почти равное количество очков.
Инструментовка. Годится алгебраический процедурный язык с хорошими управляющими структурами цикла. Возможно, подойдет и APL или другой язык обработки массивов, если только вы сумеете так организовать турниры, чтобы стала выгодной параллельная обработка всех соперников.
Длительность исполнения. Одному исполнителю на 2 недели.
Развитие темы. Большинство расширений включает более подробный анализ и сравнение систем проведения турниров. Во-первых, заметьте, что нижняя часть классификации по итогам турнира с немедленным выбыванием носит довольно произвольный характер. Кроме того, соперникам, попавшим в эту часть классификации, весьма тоскливо, ибо они рано вылетели. Для утешения можно организовать турниры с немедленным выбыванием среди неудачников каждого круга. Результаты этих турниров, а не приведенное выше правило, расставят неудачников по местам. Поскольку и в этих побочных турнирах будут проигравшие, организуйте турниры неудачливых неудачников, и так до посинения. Заметьте, что турнир по-прежнему пройдет в n кругов, но теперь все соперники будут участниками всех кругов. Если во всех встречах побеждают сильнейшие, этот, более тщательно организованный турнир превращается в законченный алгоритм сортировки.
Вообще, турниры — это сортировка участвующих в них соперников, хотя правило сравнения и носит вероятностный характер. На основе любого метода сортировки, не нарушающего двух основных правил турниров, можно организовать состязание. Вот основные правила:
1. Ни один из соперников не должен участвовать более чем в одном матче одного круга, а число кругов должно примерно равняться логарифму числа участников.
2. Никакие два соперника не должны встречаться больше одного раза.
Используя изложенные идеи, вы можете оценить и классические способы проведения турниров, такие, как отложенное выбывание, и способы, придуманные вами.
В голову приходит также несколько статистических вопросов. Как влияет частичное или полное рассеивание на турниры с немедленным выбыванием? Как влияет случайная жеребьевка (т. е. случайное составление начальных пар) на ход турниров по швейцарской системе? Каков будет эффект введения иной функции превосходства? Наконец, поскольку для получения итоговой статистики по нескольким экспериментам, видимо, нельзя просто усреднять две наши статистики, спрашивается: какая статистическая операция должна быть использована?
Литература
Харкнесс (Harkness К.). Official Chess Handbook. David McKay, New York, NY, 1967. Книга Харкнесса содержит исчерпывающее изложение шахматной юрисдикции. Поскольку швейцарская система сделала возможным проведение в Соединенных Штатах больших открытых турниров, автор чрезвычайно подробно излагает все ее тонкости. В книге содержится много предложений по разрешению неясных ситуаций и упорядочению игроков. Кнут (Knuth D. E.). The Art of Computer Programming/Seminumerical Algorithms. Addison-Wesley, Reading, MA, 1969. [Имеется перевод: Кнут Д. Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы. — М.: Мир, 1977.] Глава 3 этой «библии» посвящена случайным числам, их порождению и использованию. Вы узнаете об опасности трюкачества в этой области. Рекомендуем вам воспользоваться генератором Макларена — Марсальи, который Д. Кнут описывает в алгоритме М. Хоэль (Hoel G.) Introduction to Mathematical Statistics. Wiley, New York, NY, 1971. Для нестатистиков корреляция и прочая статистическая магия кажутся совершенно недоступными человеческому разуму. Автор строго излагает основы статистики, не обманывая читателя. * Кнут Д. Искусство программирования для ЭВМ. Т. 3. Сортировка и поиск», п. 5.3.3. Пер. с англ. — М.: Мир, 1978. * Шахматный кодекс СССР. — М.: Физкультура и спорт, 1977.6 Финансовые воротилы, или Управление предприятиями и машинное моделирование
Моделирование нередко оказывается удобным средством для изучения тех или иных ситуаций, которые характерны для реальной жизни. Процесс моделирования дает нам кроме множества курьезов некоторые знания об изучаемом объекте. В самом деле, многие так увлекаются исследованием модели, что уже не возвращаются к объекту как таковому. Попробуйте, что получится у вас.Деловая игра Менеджмент[12]
Решением совета директоров крупного промышленного концерна вы назначены президентом компании. Компания владеет несколькими фабриками. Каждый месяц компания покупает сырье, обрабатывает его и продает изготовленную продукцию публике, ждущей ее с нетерпением. Вам теперь придется решать, сколько и каких товаров выпускать, стоит ли и когда именно расширять производственные мощности, как финансировать их расширение и как принять скромно-застенчивый вид, отчитываясь о незаконных прибылях. Перед тем как приступить к работе, вы строите модель промышленности в целом, чтобы в частном порядке отработать свою линию поведения. И вот какую игру вы в результате изобрели.Начальная ситуация
Моделирование ведется с шагом по времени в один месяц. В начале игры каждый игрок (президент компании) получает две обычные фабрики, четыре единицы сырья и материалов (сокращенно ЕСМ), две единицы готовой продукции (сокращенно ЕГП) и 10000 долл. наличными. Игроки занумерованы от 1 до N, и в первом круге игрок 1 — старший. С каждым кругом (т. е. ежемесячно) роль старшего переходит к следующему по порядку номеров игроку, после N-го старшим становится опять первый (так что номер старшего в круге Т вычисляется по формуле (Т mod N) + 1). На торгах при прочих равных условиях выигрывает самый старший игрок (тот, кто будет старшим в следующем круге).Ежемесячные операции
Описанные ниже сделки происходят каждый месяц и именно в таком порядке. Если в какой-то момент компания не может выполнить своих финансовых обязательств, она немедленно объявляется банкротом. Ее имущество пропадает, и она выходит из игры (так что лучше иметь наготове запас наличных). Все денежные расчеты происходят между отдельными игроками и одним общим банком. Невозможна передача денег прямо от игрока к игроку, что исключает сговор, направленный против какой-либо компании. Банк, кроме того, контролирует источники сырья и скупает всю готовую продукцию. 1. Постоянные издержки. Каждый игрок (в порядке убывания старшинства, начиная со старшего) платит 300 долл. за каждую имеющуюся у него ЕСМ, 500 долл. за каждую наличную ЕГП, 1000 долл. за владение каждой обычной фабрикой и 1500 долл. — за владение автоматизированной. Это постоянные ежемесячные издержки каждого игрока, даже если он в этом круге не предпринимает никаких других действий. 2. Определение обстановки на рынке. Банк решает и сообщает игрокам, сколько ЕСМ продаст в этот раз и какова их минимальная цена. Объявляется также, сколько ЕГП в общей сложности будет закуплено и какова максимальная цена. В табл. 6.1 приведены пять уровней предложения ЕСМ и спроса на ЕГП (обратите внимание, что с ростом одной из этих величин другая убывает), а также верхние и нижние границы цен для каждого случая. В число игроков Р не включены те, кто обанкротился, и Р может, таким образом, быть меньше N. Произведения 1.5Р и 2.5Р округляются до ближайшего целого с недостатком. В табл. 6.2 приведена матрица вероятностей перехода, в соответствии с которой банк определяет новый месячный уровень спроса и предложения, исходя из прежнего. Предполагается, что в нулевом месяце уровень равен 3.
В табл. 6.1 приведены пять уровней предложения ЕСМ и спроса на ЕГП (обратите внимание, что с ростом одной из этих величин другая убывает), а также верхние и нижние границы цен для каждого случая. В число игроков Р не включены те, кто обанкротился, и Р может, таким образом, быть меньше N. Произведения 1.5Р и 2.5Р округляются до ближайшего целого с недостатком. В табл. 6.2 приведена матрица вероятностей перехода, в соответствии с которой банк определяет новый месячный уровень спроса и предложения, исходя из прежнего. Предполагается, что в нулевом месяце уровень равен 3.
 3. Заявки на сырье и материалы. Каждый игрок тайно от других готовит заявку на ЕСМ на текущий месяц. В заявке указывается требуемое число ЕСМ и предлагается цена не ниже банковской минимальной (запрос нуля ЕСМ или предложение цены ниже минимальной автоматически исключает игрока из торгов в этом месяце). Все заявки раскрываются одновременно, и имеющиеся ЕСМ распределяются между игроками в порядке убывания предложенной цены. Если сырья не хватает на всех, заявки с предложением более низкой цены не удовлетворяются. При прочих равных условиях сырье достается самому старшему игроку. Игроки платят за сырье при его получении. Банк не сохраняет оставшееся после удовлетворения заявок сырье на следующий месяц.
4. Производство продукции. Все игроки по очереди (по убыванию старшинства, начиная со старшего) объявляют, сколько ЕСМ они собираются переработать в ЕГП в текущем месяце и на каких фабриках. Каждый игрок обязан тут же покрыть расходы на производство. Обычная фабрика может за месяц переработать одну ЕСМ при затратах в 2000 долл. Автоматизированная фабрика может либо сделать то же, либо переработать 2 ЕСМ при затратах в 3000 долл. Конечно, чтобы переработать ЕСМ, их надо иметь.
5. Продажа продукции. При покупке банком у игроков ЕГП организуются примерно такие же торги, как и при продаже ЕСМ. Заявленные цены не должны превышать максимальную цену, установленную банком, причем банк покупает ЕГП в первую очередь у тех, кто заявил более низкую цену. При прочих равных условиях предпочтение отдается старшему игроку. Если предложение превышает спрос, наиболее дорогие ЕГП остаются непроданными. Игроки получают деньги за продукцию при ее продаже.
6. Выплата ссудного процента. Каждый игрок платит один процент от общей суммы непогашенных ссуд, в том числе и тех, которые будут погашены в текущем месяце.
7. Погашение ссуд. Каждый игрок, получивший ссуду сроком до текущего месяца, должен ее погасить. Поскольку возвращение ссуд предшествует получению новых, платить надо наличными.
8. Получение ссуд. Теперь каждый игрок может получить ссуду. Ссуды обеспечиваются имеющимися у игрока фабриками; под обычную фабрику дается ссуда 5000 долл., под автоматизированную — 10000 долл. Общая сумма непогашенных ссуд не может превышать половины гарантированного капитала, но в этих пределах можно свободно занимать. Банк немедленно выплачивает ссуду игроку. Срок погашения ссуды истекает через 12 месяцев — например, ссуду, взятую в 3-м месяце, возвращать надо в 15-м. Нельзя погашать ссуды раньше срока.
9. Заявки на строительство. Игроки могут строить новые фабрики. Обычная фабрика стоит 5000 долл. и начинает давать продукцию на 5-й месяц после начала строительства; автоматизированная фабрика стоит 10 000 долл и дает продукцию на 7-й месяц после начала строительства. Обычную фабрику можноавтоматизировать за 7000 долл., реконструкция продолжается 9 месяцев, все это время фабрика может работать как обычная. Половину стоимости фабрики надо платить в начале строительства, вторую половину — за месяц до начала выпуска продукции в этой же фазе цикла. Общее число имеющихся и строящихся фабрик у каждого игрока не должно превышать шести.
3. Заявки на сырье и материалы. Каждый игрок тайно от других готовит заявку на ЕСМ на текущий месяц. В заявке указывается требуемое число ЕСМ и предлагается цена не ниже банковской минимальной (запрос нуля ЕСМ или предложение цены ниже минимальной автоматически исключает игрока из торгов в этом месяце). Все заявки раскрываются одновременно, и имеющиеся ЕСМ распределяются между игроками в порядке убывания предложенной цены. Если сырья не хватает на всех, заявки с предложением более низкой цены не удовлетворяются. При прочих равных условиях сырье достается самому старшему игроку. Игроки платят за сырье при его получении. Банк не сохраняет оставшееся после удовлетворения заявок сырье на следующий месяц.
4. Производство продукции. Все игроки по очереди (по убыванию старшинства, начиная со старшего) объявляют, сколько ЕСМ они собираются переработать в ЕГП в текущем месяце и на каких фабриках. Каждый игрок обязан тут же покрыть расходы на производство. Обычная фабрика может за месяц переработать одну ЕСМ при затратах в 2000 долл. Автоматизированная фабрика может либо сделать то же, либо переработать 2 ЕСМ при затратах в 3000 долл. Конечно, чтобы переработать ЕСМ, их надо иметь.
5. Продажа продукции. При покупке банком у игроков ЕГП организуются примерно такие же торги, как и при продаже ЕСМ. Заявленные цены не должны превышать максимальную цену, установленную банком, причем банк покупает ЕГП в первую очередь у тех, кто заявил более низкую цену. При прочих равных условиях предпочтение отдается старшему игроку. Если предложение превышает спрос, наиболее дорогие ЕГП остаются непроданными. Игроки получают деньги за продукцию при ее продаже.
6. Выплата ссудного процента. Каждый игрок платит один процент от общей суммы непогашенных ссуд, в том числе и тех, которые будут погашены в текущем месяце.
7. Погашение ссуд. Каждый игрок, получивший ссуду сроком до текущего месяца, должен ее погасить. Поскольку возвращение ссуд предшествует получению новых, платить надо наличными.
8. Получение ссуд. Теперь каждый игрок может получить ссуду. Ссуды обеспечиваются имеющимися у игрока фабриками; под обычную фабрику дается ссуда 5000 долл., под автоматизированную — 10000 долл. Общая сумма непогашенных ссуд не может превышать половины гарантированного капитала, но в этих пределах можно свободно занимать. Банк немедленно выплачивает ссуду игроку. Срок погашения ссуды истекает через 12 месяцев — например, ссуду, взятую в 3-м месяце, возвращать надо в 15-м. Нельзя погашать ссуды раньше срока.
9. Заявки на строительство. Игроки могут строить новые фабрики. Обычная фабрика стоит 5000 долл. и начинает давать продукцию на 5-й месяц после начала строительства; автоматизированная фабрика стоит 10 000 долл и дает продукцию на 7-й месяц после начала строительства. Обычную фабрику можноавтоматизировать за 7000 долл., реконструкция продолжается 9 месяцев, все это время фабрика может работать как обычная. Половину стоимости фабрики надо платить в начале строительства, вторую половину — за месяц до начала выпуска продукции в этой же фазе цикла. Общее число имеющихся и строящихся фабрик у каждого игрока не должно превышать шести.
Окончание игры и подсчет результатов
Игра оканчивается после некоторого фиксированного числа кругов (13 или более) или когда обанкротятся все игроки, кроме одного. Чтобы подсчитать общий капитал компании, надо сложить стоимость всех фабрик (по цене, по которой их можно было бы построить заново), стоимость имеющихся у нее ЕСМ (по минимальной банковской цене текущего месяца), стоимость имеющихся ЕГП (по максимальной банковской цене текущего месяца) и имеющиеся у компании наличные. После этого надо вычесть общую сумму ссуд и предстоящих расходов по уже начатому строительству. Если к концу игры приходит несколько игроков, результаты считаются по их капиталам. Любой игрок в любой момент может узнать состояние дел любого другого игрока — его капитал, наличные, взятые ссуды, все, что касается готовой продукции, имеющихся и строящихся фабрик. Во время торгов игроки ничего не знают о заявках, сделанных другими, но, как только банк собрал все заявки, они обнародуются и количество купленных или проданных каждым игроком единиц становится известно всем. Игроки могут сами вести любые записи, но банк не предоставляет им никакой информации, кроме той, которая предусмотрена правилами игры. Тема. Задача состоит из двух частей. Первая заключается в том, чтобы написать программу, которая управляет ходом моделирования — программу-банкир. Эта программа должна полностью контролировать игру: устанавливать цены, закупать продукцию и продавать сырье, проводить торги, вести учет и т. д. Эта программа должна в соответствующие моменты опрашивать игроков и добиваться соблюдения ими всех правил. В частности, банкир защищает от несанкционированного доступа всю информацию, как свою, так и чужую, касающуюся учета и состояния дел отдельных игроков. Программа-банкир периодически (например, ежемесячно) выдает сводный финансовый отчет. Поскольку отчеты эти предстоит читать людям, они должны быть понятны и приемлемы с эстетической точки зрения. Вторая часть задачи — написать программы поведения игроков. Каждая программа-игрок должна быть в состоянии отвечать на любые запросы программы-банкира по ходу игры: она должна уметь предлагать цену на сырье, принимать решения, продавать готовую продукцию и т. п. Если для моделирования используется диалоговая система, реализуйте одну из программ-игроков таким образом, чтобы она просто передавала свои запросы игроку-человеку, находящемуся за терминалом. Такая программа должна уметь отвечать на запросы человека о состоянии игры. После того как будет написано несколько программ-игроков, их надо объединить с программой-банкиром, чтобы получилась полная игровая система. Проведите с этой системой несколько игр и изучите результаты. Заметим, что несколько экземпляров одной и той же программы-игрока вполне могут выступать в качестве противников (т. е. мы считаем людей в соответствующей реальной игре изначально одинаковыми). Но для полной гарантии надо написать хотя бы две нетривиальные программы-игрока. Указания исполнителю. Эта игра — пример последовательного, или пошагового, моделирования, при котором все события (кроме банкротств) происходят в строго определенном, заранее известном порядке. Цикл по месяцам — удобная структура для ведущей программы. Редко можно встретить задачу на программирование, прикладную или научную, столь удобную для хорошо структурированной реализации, как эта. Не премините воспользоваться такой возможностью. В формулировке первой части задачи имеется некий подводный камень. Программа-банкир должна защищать всю существенную информацию от несанкционированного доступа программы-игрока. Иначе говоря, программа-банкир должна сохранять в тайне все счета, как свои, так и игроков, обеспечивать секретность торгов и в то же время предоставлять игрокам информацию в ответ на их запросы. К сожалению, во многих языках обеспечить это бывает трудно, если вообще возможно. В Фортране критические значения не должны помещаться в общих блоках, поскольку доступ к общим блокам программы-игрока не контролируется. В языке с блочной структурой критические значения не могут быть глобальными по отношению к программам-игрокам по той же причине. Даже если предположить, что программа-игрок не допускает таких нарушений правил исходного языка, как, например, выход за границы массива или пользование автокодными вставками, обеспечить полную сохранность трудно. Один из моментов, который должен найти отражение в документации, — средства сохранности и их надежность. Инструментовка. Эта задача прямо-таки просится, чтобы ее реализовали на языке с развитыми управляющими структурами. Потребность в совершенных структурах данных не столь велика. В качестве возможных кандидатов можно рассматривать Кобол и Фортран, но их недостаток — в их бедности. Для решения подобных задач успешно использовался APL, но в этом случае программу трудно хорошо структурировать. Вы вряд ли найдете язык, удовлетворяющий упомянутым выше требованиям к защите данных. Длительность исполнения. Одному исполнителю на 4 недели, двум — на 3 или трем — на 2. Две недели должно уйти на программу-игрока. Развитие темы. Дополнительное удовольствие от программирования игр — возможность поиграть с программой-игроком. Иногда при применении совсем простых эвристических методов может получиться удивительно сложное поведение. В программу, реализующую стратегию игрока, несложно включить элементы самообучения, чтобы ее поведение со временем совершенствовалось. Проведите несколько тренировочных турниров с участием как людей, так и программ (люди тоже обучаемы). Имеется стандартный прием обучения интеллектуальных программ новым стратегиям. Один экземпляр (Альфа) обучается в тренировочной серии игр, второй (Бета) остается на том же уровне знаний, какой он имел перед этой серией. Затем устраивается сравнительная серия игр между ними; если Альфа побеждает, его знания передаются всем копиям программ-игроков, в противном случае Альфа эти знания забывает как бесполезные и с ним проводится новая тренировочная серия. Игру можно сделать интереснее, если добавить новые правила, которые, видимо, приблизят ее к реальной жизни. Ниже перечислены дополнительные правила. Если какое-либо из правил включается, все правила с меньшими номерами также надо включать. 1. Чрезвычайные ссуды. В случае финансовых затруднений каждый игрок может взять чрезвычайную ссуду. Такая ссуда стоит 2% в месяц вместо обычного 1% и предоставляется сроком на 4 месяца (ссудный процент выплачивается в обычном порядке). Общая сумма непогашенных задолженностей по-прежнему не может быть больше половины суммы, обеспечиваемой всеми фабриками данного игрока. Нельзя брать чрезвычайные ссуды для спасения от банкротства в момент, когда банк уже требует платежа по какому-либо обязательству. Брать чрезвычайную ссуду можно не позже начала цикла, в котором подходит срок платежа. 2. Чрезвычайные происшествия. В начале каждого цикла, непосредственно перед выплатой постоянных издержек, банк объявляет обо всех чрезвычайных происшествиях на этот месяц. На рис. 6.1 приведены вероятности различных чрезвычайных происшествий. Эффект приведенных ниже изменений в расценках накапливается на каждом шаге: так, 10%-ный рост с последующим 10%-ным спадом дает в результате 99% исходного уровня. К чрезвычайным происшествиям относятся: Забастовка — игрок, у которого началась забастовка, может прекратить производство на 3 месяца, начиная с текущего, или вплоть до конца игры увеличить на 10% все издержки (как постоянные, так и производственные). Игрок, прекративший производство, может участвовать во всех прочих действиях и должен по-прежнему нести постоянные издержки.
Транспортный кризис — те, кого он затронул, не могут в этом месяце ни покупать сырье, ни продавать продукцию.
Чрезвычайный налог — те, кого это касается, должны немедленно сделать однократный взнос, исходя из расчета 500 долл. за фабрику. Запрещается для выплаты этой суммы прибегать к чрезвычайным ссудам. Возможно банкротство.
Авария — у игрока, которого это касается, одна из фабрик (по возможности обычная) в этом месяце не выпускает продукции.
Внедрение новой техники — у игроков, которых это касается, вплоть до конца игры на 10% снижаются издержки производства.
Неожиданная удача — соответствующий игрок может немедленно продать любое число из имеющихся у него ЕГП по 6500 долл.
3. Закрытие фабрики. В очередной месяц, как раз перед подачей заявки на строительство, игрок может закрыть все или некоторые свои фабрики. Начиная со следующего месяца постоянные издержки по такой фабрике сократятся вдвое, но продукции не будет совсем. Впоследствии закрытую фабрику можно открыть в той же точке очередного месячного цикла. Через два месяца после этого фабрика снова вступает в строй, и надо опять оплачивать издержки в полном размере. Например, вновь открытая в 13-м месяце фабрика вступает в строй действующих в 15-м.
4. Дробление заявок. На любых торгах любой игрок может сделать одну заявку, две или ни одной. Общий объем заявок одного игрока как на покупку, так и на продажу не должен превосходить предложений банка (для продажи — еще и имеющегося у данного игрока объема продукции). Банк рассматривает различные заявки одного игрока точно так же, как заявки разных игроков. Заявки эти конкурируют как друг с другом, так и с заявками других игроков. Удовлетворены могут быть обе, одна или ни одной. При прочих равных условиях по-прежнему побеждает старший игрок.
Забастовка — игрок, у которого началась забастовка, может прекратить производство на 3 месяца, начиная с текущего, или вплоть до конца игры увеличить на 10% все издержки (как постоянные, так и производственные). Игрок, прекративший производство, может участвовать во всех прочих действиях и должен по-прежнему нести постоянные издержки.
Транспортный кризис — те, кого он затронул, не могут в этом месяце ни покупать сырье, ни продавать продукцию.
Чрезвычайный налог — те, кого это касается, должны немедленно сделать однократный взнос, исходя из расчета 500 долл. за фабрику. Запрещается для выплаты этой суммы прибегать к чрезвычайным ссудам. Возможно банкротство.
Авария — у игрока, которого это касается, одна из фабрик (по возможности обычная) в этом месяце не выпускает продукции.
Внедрение новой техники — у игроков, которых это касается, вплоть до конца игры на 10% снижаются издержки производства.
Неожиданная удача — соответствующий игрок может немедленно продать любое число из имеющихся у него ЕГП по 6500 долл.
3. Закрытие фабрики. В очередной месяц, как раз перед подачей заявки на строительство, игрок может закрыть все или некоторые свои фабрики. Начиная со следующего месяца постоянные издержки по такой фабрике сократятся вдвое, но продукции не будет совсем. Впоследствии закрытую фабрику можно открыть в той же точке очередного месячного цикла. Через два месяца после этого фабрика снова вступает в строй, и надо опять оплачивать издержки в полном размере. Например, вновь открытая в 13-м месяце фабрика вступает в строй действующих в 15-м.
4. Дробление заявок. На любых торгах любой игрок может сделать одну заявку, две или ни одной. Общий объем заявок одного игрока как на покупку, так и на продажу не должен превосходить предложений банка (для продажи — еще и имеющегося у данного игрока объема продукции). Банк рассматривает различные заявки одного игрока точно так же, как заявки разных игроков. Заявки эти конкурируют как друг с другом, так и с заявками других игроков. Удовлетворены могут быть обе, одна или ни одной. При прочих равных условиях по-прежнему побеждает старший игрок.
Литература
Management. Avalon Hill Co., Baltimore, MD, 1960. Менеджмент — наиболее близкая к жизни общедоступная деловая игра. Разработан остроумный способ игры вручную, без помощи ЭВМ. Иванс, Уоллес, Сатерлэнд (Evans G. W., H, Wallace G. F., Sutherland G. L). Simulation Using Digital Computers, Prentice-Hall, Englewood Cliffs, NJ, 1967. Весьма простое введение в имитационное моделирование. Чтение этой книги, конечно, подразумевает наличие у читателя некоторых знаний об ЭВМ. Подробно разбирается несколько примеров как антагонистических, так и неантагонистических ситуаций. *Нейлор Т. Машинные имитационные эксперименты с моделями экономических систем. Пер. с англ. — М.: Мир, 1975.7. Крисс-кросс, или Эвристическое составление головоломки
Многие считают кроссворды слишком трудной головоломкой, потому что отгадать слово им не под силу. Но вписывать буквы в клетки нравится. Для подобных людей существует более простая головоломка — крисс-кросс. Каждый крисс-кросс состоит из списка слов, разбитых для удобства на группы в соответствии с длиной и упорядоченных по алфавиту внутри каждой группы, а также из схемы, в которую нужно вписать слова. Схема подчиняется тому же правилу, что и в кроссворде, — в местах пересечения слова имеют общую букву, однако номера отсутствуют, поскольку слова известны заранее, требуется лишь вписать их в нужные места. Обычно в схемах крисс-кросса гораздо меньше пересечений по сравнению с кроссвордами, а незаполняемые клетки не заштриховываются, если это не приводит к путанице. Крисс-кросс всегда имеет единственное решение, в котором используются все перечисленные слова. Пример головоломки, правда очень маленький, приведен на рис. 7.1. Заметьте, что длина слова служит важным ключом к разгадке. Рисунок 7.1. Пример головоломки крисс-кросс.
Тема. Напишите программу, читающую список слов и строящую для этого списка правильную схему крисс-кросса. Представьте заполненную схему как доказательство того, что она правильная. Возможно, хотя и маловероятно, что для данного списка слов не существует решения (как и в кроссворде, схема должна быть связной). Ваша программа должна сообщать о всех неудачах при построении схемы и о всех ситуациях, нарушающих однозначность (таких, например, как наличие повторяющихся слов). Попутно решите еще одну задачу — получите красивый графический вывод.
Указания исполнителю. Качество схем крисс-кросса пропорционально их «связанности», т. е., чем теснее в среднем слова переплетены с соседями, тем интереснее головоломка. Связанность можно измерять по-разному: как отношение площади схемы к площади наименьшего объемлющего прямоугольника; как среднее число пересечений на слово; как среднее число пересечений на букву; как минимальное число пересечений на слово. При генерации головоломок крисс-кросс для массовых изданий использовалась коммерческая программа, но головоломки получались неинтересные — слишком длинные и извилистые. Когда ваша программа заработает, позаботьтесь об увеличении связанности.
Предложенная задача — классическая для метода перебора с возвратами. Начните с вписывания слов в фиксированную схему, пока в списке есть подходящие слова. Когда они кончатся, вернитесь на шаг назад, удалив последнее вписанное слово, и попытайтесь вписать другое слово. Необходимо разработать эвристику для выбора очередного кандидата из списка неиспользованных слов. Контроль однозначности должен включать проверку того, что в схеме нельзя поменять местами никакие два слова равной длины. Достаточна ли такая проверка? Нет ли более изящной? Полное алгоритмическое решение, максимизирующее связанность, несомненно, представит значительный теоретический интерес.
Инструментовка. К решению задачи имеется много подходов, но в любом случае нужны гибкие структуры данных, чтобы отслеживать продвижение программы, и средства для удобной работы с цепочками литер и образцами. Напрашиваются языки Снобол и PL/I. В Паскале есть подходящие структуры данных, но средства для работы с цепочками придется создавать самому.
Длительность исполнения. Одному исполнителю на 4 недели. Еще неделя на графический вывод.
Рисунок 7.1. Пример головоломки крисс-кросс.
Тема. Напишите программу, читающую список слов и строящую для этого списка правильную схему крисс-кросса. Представьте заполненную схему как доказательство того, что она правильная. Возможно, хотя и маловероятно, что для данного списка слов не существует решения (как и в кроссворде, схема должна быть связной). Ваша программа должна сообщать о всех неудачах при построении схемы и о всех ситуациях, нарушающих однозначность (таких, например, как наличие повторяющихся слов). Попутно решите еще одну задачу — получите красивый графический вывод.
Указания исполнителю. Качество схем крисс-кросса пропорционально их «связанности», т. е., чем теснее в среднем слова переплетены с соседями, тем интереснее головоломка. Связанность можно измерять по-разному: как отношение площади схемы к площади наименьшего объемлющего прямоугольника; как среднее число пересечений на слово; как среднее число пересечений на букву; как минимальное число пересечений на слово. При генерации головоломок крисс-кросс для массовых изданий использовалась коммерческая программа, но головоломки получались неинтересные — слишком длинные и извилистые. Когда ваша программа заработает, позаботьтесь об увеличении связанности.
Предложенная задача — классическая для метода перебора с возвратами. Начните с вписывания слов в фиксированную схему, пока в списке есть подходящие слова. Когда они кончатся, вернитесь на шаг назад, удалив последнее вписанное слово, и попытайтесь вписать другое слово. Необходимо разработать эвристику для выбора очередного кандидата из списка неиспользованных слов. Контроль однозначности должен включать проверку того, что в схеме нельзя поменять местами никакие два слова равной длины. Достаточна ли такая проверка? Нет ли более изящной? Полное алгоритмическое решение, максимизирующее связанность, несомненно, представит значительный теоретический интерес.
Инструментовка. К решению задачи имеется много подходов, но в любом случае нужны гибкие структуры данных, чтобы отслеживать продвижение программы, и средства для удобной работы с цепочками литер и образцами. Напрашиваются языки Снобол и PL/I. В Паскале есть подходящие структуры данных, но средства для работы с цепочками придется создавать самому.
Длительность исполнения. Одному исполнителю на 4 недели. Еще неделя на графический вывод.
Литература
Армбрастер (Armbruster F.). Computer Crosswords, Troubadour Press, San Francisco, CA, 1974. Именно эта книга подсказала этюд. Сами по себе головоломки, помещенные в ней, не особенно хороши. Возможно, ваше решение окажется лучше. Мазлак (Mazlack L. J.). Machine Selection of Elements in Crossword Puzzles: An Application of Computational Linguistics. SIAM J. Comput., 5, 1, pp. 51–72, March 1976. Автор описывает программу, пытающуюся заполнить схему кроссворда словами из очень большого словаря. Схема и словарь даны заранее. Предполагается, что заключительные слова придумывает человек. Эта задача аналогична задаче построения схемы крисс-кросса, и, возможно, книга подскажет вам, как подступиться к решению.8 Тезей, или Автоматическое построение лабиринтов
Тезей должен был найти выход из Критского лабиринта или погибнуть от руки Минотавра. Но что поразительно: найти вход в лабиринт — задача не менее трудная. Здесь не представляется возможным описать все мыслимые лабиринты, да это и не требуется. Мы займемся простыми лабиринтами, построенными на прямоугольнике m×n, где m, n — положительные целые числа. Внутри и на границах прямоугольника поставлены стенки по ребрам покрывающей его единичной квадратной сетки. Чтобы построить из прямоугольника лабиринт, выбьем одну единичную стенку на одной из сторон прямоугольника (получится вход в лабиринт); выбьем одну единичную стенку на противоположной стороне (получится выход) и еще удалим какое-то число строго внутренних стенок. Говорят, что лабиринт имеет решение, если между входом и выходом внутри лабиринта есть путь в виде ломаной, не имеющей общих точек со стенками. Решение единственно, если любые два таких пути проходят через одни и те же внутренние ячейки сетки. На рис. 8.1 приведен пример лабиринта 6×6. Рисунок 8.1. Пример лабиринта.
Тема. Напишите программу, которая по исходным данным m и n строит прямоугольный лабиринт m×n (проверьте, допустимы ли заданные m и n). Предусмотрите, чтобы программа при каждом обращении к ней порождала разные лабиринты. Лабиринт должен иметь единственное решение, и, чтобы получившийся лабиринт был интересным, все ячейки должны быть соединены с основным путем, дающим решение. Если в вашем распоряжении имеется хорошее графическое устройство, используйте его для изображения лабиринтов, в противном случае придумайте систему обозначений для записи лабиринтов или выводите лабиринты на АЦПУ.
Указания исполнителю. Теоретически нельзя удовлетворить требованию, чтобы любые два лабиринта (даже при одинаковых m и n) были различны, поскольку существует лишь конечное число лабиринтов любого наперед заданного размера, а программу можно вызвать большее число раз. Однако число лабиринтов какого-нибудь размера очень велико, и поэтому вероятность повторения лабиринта можно сделать очень маленькой. Практически это достигается, если программа будет производить «случайный» выбор различных вариантов, опираясь на какое-либо доступное ей, но неуправляемое значение (обычно берут дату и время вызова программы). Варианты, между которыми выбирает программа, это, например, положение входа и выхода и положение хотя бы нескольких внутренних разрушаемых стенок. При отладке разумно будет отключить механизм случайного выбора, чтобы изменения результата работы вызывались только изменениями самой программы.
Один из возможных подходов к решению таков. Выбираем вход; затем, начав от него, добавляем по одной ячейке к главному пути-решению, пока он не достигнет выходной стороны. После этого удаляем некоторые внутренние стенки так, чтобы все клетки оказались соединенными с главным путем. Чтобы главный путь не получился прямым коридором, следует при его построении предусмотреть случайные повороты. Программа должна также следить за тем, чтобы при построении главного пути или при открытии боковых ячеек не нарушалась единственность решения. Наблюдательный читатель заметит, что определение единственности решения не годится в случае, когда путь заходит в боковой тупик и затем возвращается. Вы можете попробовать разработать в том же духе формально корректное определение.
Инструментовка. Программу можно написать почти на любом из процедурных языков. Используйте эту программу для сравнения языков с точки зрения управляющих структур, встроенных структур данных и эффективности выполнения.
Длительность исполнения. Одному исполнителю на 3 недели.
Рисунок 8.1. Пример лабиринта.
Тема. Напишите программу, которая по исходным данным m и n строит прямоугольный лабиринт m×n (проверьте, допустимы ли заданные m и n). Предусмотрите, чтобы программа при каждом обращении к ней порождала разные лабиринты. Лабиринт должен иметь единственное решение, и, чтобы получившийся лабиринт был интересным, все ячейки должны быть соединены с основным путем, дающим решение. Если в вашем распоряжении имеется хорошее графическое устройство, используйте его для изображения лабиринтов, в противном случае придумайте систему обозначений для записи лабиринтов или выводите лабиринты на АЦПУ.
Указания исполнителю. Теоретически нельзя удовлетворить требованию, чтобы любые два лабиринта (даже при одинаковых m и n) были различны, поскольку существует лишь конечное число лабиринтов любого наперед заданного размера, а программу можно вызвать большее число раз. Однако число лабиринтов какого-нибудь размера очень велико, и поэтому вероятность повторения лабиринта можно сделать очень маленькой. Практически это достигается, если программа будет производить «случайный» выбор различных вариантов, опираясь на какое-либо доступное ей, но неуправляемое значение (обычно берут дату и время вызова программы). Варианты, между которыми выбирает программа, это, например, положение входа и выхода и положение хотя бы нескольких внутренних разрушаемых стенок. При отладке разумно будет отключить механизм случайного выбора, чтобы изменения результата работы вызывались только изменениями самой программы.
Один из возможных подходов к решению таков. Выбираем вход; затем, начав от него, добавляем по одной ячейке к главному пути-решению, пока он не достигнет выходной стороны. После этого удаляем некоторые внутренние стенки так, чтобы все клетки оказались соединенными с главным путем. Чтобы главный путь не получился прямым коридором, следует при его построении предусмотреть случайные повороты. Программа должна также следить за тем, чтобы при построении главного пути или при открытии боковых ячеек не нарушалась единственность решения. Наблюдательный читатель заметит, что определение единственности решения не годится в случае, когда путь заходит в боковой тупик и затем возвращается. Вы можете попробовать разработать в том же духе формально корректное определение.
Инструментовка. Программу можно написать почти на любом из процедурных языков. Используйте эту программу для сравнения языков с точки зрения управляющих структур, встроенных структур данных и эффективности выполнения.
Длительность исполнения. Одному исполнителю на 3 недели.
9. Познай самого себя, или Программа, печатающая собственный исходный текст
В философии интроспекция (или самонаблюдение) считается одним из важных элементов мышления. Все здравомыслящие люди должны внимательно отнестись к названию этюда. Если человек может достичь самопознания, то почему этого не может сделать программа? Ну а чтобы познать себя, лучше всего написать автобиографию. Тема. Напишите программу, печатающую копию собственного исходного текста. Вывод не должен содержать «управляющих» карт или другой информации, зависящей от системы. Печатается только то, что перфорируется для компилятора. Однако ваша программа ничего не должна вводить; ей не следует опираться на системные «штучки», например на знание того, что конкретный компилятор оставляет копию исходной программы в непомеченном COMMON-блоке. Проследите, чтобы программа давала одинаковый результат независимо от места и времени выполнения. Указания исполнителю. Не поддавайтесь отчаянию и страху, даже если тринадцатая попытка оказалась неудачной! Подобные программы называются интроспективными, и существует теорема, в которой утверждается, что интроспективную программу можно написать на любом «достаточно мощном» языке. Все обычные языки программирования — достаточно мощные. Для решения требуется лишь взглянуть на язык под соответствующим углом зрения. Программа, вероятно, займет не более 30–40 строк. Инструментовка. Годится любой язык. Длительность исполнения. Одному исполнителю на 1 неделю.Литература
Брэтли, Милло (Bratley P., Millo J.). Computer Recreations Self-Reproducing Automata. Software — Practice and Experience, 2, pp. 397–400, 1972. Эту статью нужно читать только в крайнем случае, поскольку в ней представлено полное решение задачи. Роджерс (Rogers H., Jr.). Theory of Recursive Functions and Effective Computability. McGraw-Hill, New York, NY, 1972. [Имеется перевод: Роджерс X. Теория рекурсивных функций и эффективная вычислимость. — М.: Мир, 1972.] Чтение этого превосходного введения в теорию рекурсивных функций требует усердия, но вы будете вознаграждены полнотой и ясностью полученной картины. Главы 1–3 образуют достаточный фундамент; результаты об интроспекции содержатся в параграфах 11.1, 11.2 и 11.4.10. Не прячьте ваши денежки, или Расчет дохода от вложенного капитала
Самым разным людям — финансистам, биржевым дельцам, банкирам и даже обыкновенным труженикам, вроде казначея пенсионного фонда Тимстеров[13], — хотелось бы знать, какой доход принесут им вложенные средства. Если деньги лежат на срочном вкладе, то особых сложностей не возникает, ибо банки в каждом рекламном проспекте трубят о своих процентах. Даже если ваши средства вложены в облигации, по которым не только выплачиваются проценты, но которые можно впоследствии еще и с выгодой продать, то, чтобы определить свой доход, достаточно взять разницу курсовой стоимости облигаций, прибавить проценты, и вы получите сумму, которую должен выплатить банк. Результатом этих вычислений, если их выразить в процентах годовых, приносящих при условии непрерывного их начисления известную прибыль, является инвестиционный доход. Ситуация, однако, не столь проста, если инвестиции связаны, скажем, с инвестиционным фондом, счетом капитала или небольшим собственным делом, когда имеют место нерегулярные поступления и платежи и текущие показатели меняются изо дня в день. Хорошим, в этом смысле, примером служит инвестиционный фонд[14]. Действительно, новые акции могут приобретаться по рыночной стоимости в любой момент, а купленные ранее акции точно так же могут сбываться; в процессе функционирования фонда дивиденды все время меняются (и даже исчезают), однако, как правило, вкладываются в дополнительные акции; и наконец, стоимость акций фонда ежедневно меняется по мере того, как меняется курс лежащих в его основе ценных бумаг. Было бы, конечно, здорово сравнить доход, получаемый со срочного вклада, с той радужной перспективой, которую обещают проспекты инвестиционных фондов, не забывая, само собой, о том, что обычно доход пропорционален риску. К счастью, для таких случаев имеется формула расчета дохода. Формула, к сожалению, не в замкнутом виде, а итерационная. Предположим, что А — текущая величина инвестиций, что существует m операций с капиталом, причем i-я операция производилась на сумму Pi (отрицательные значения указывают на изъятие капитала) и имела место Ti лет назад, и пусть первоначальная оценка ожидаемого дохода Y0 полагается равной нулю. Итак, определим при j > 0 величины и
и
 Тогда наилучшая оценка дохода Yj дается формулой
Yj = Yj−1 + Cj/Dj
Как только разность
|Yj − Yj−1|
станет достаточно малой, величина дохода считается найденной[15].
Тогда наилучшая оценка дохода Yj дается формулой
Yj = Yj−1 + Cj/Dj
Как только разность
|Yj − Yj−1|
станет достаточно малой, величина дохода считается найденной[15].
 При изучении табл. 10.1 обратите внимание, что величина А получается суммированием среднего и правого столбцов таблицы. Например, для третьей строки А = 189.82 долл., P1 = 68.26 долл., Р2 = 50.00 долл., Р3 = 75.00 долл., a T1 ≃ 85/365, Т2 ≃ 31/365, Т3 = 0. Заметим также, что для каждой строки таблицы оценка Y0 считается равной нулю и что расчет дохода для любой текущей даты не зависит от величины доходов в предшествующие времена.
Тема. Напишите программу вычисления дохода от вложенного капитала. Исходные данные представляют собой записи о проведенных операциях, в каждой из которых указываются дата, сумма операции и величина инвестиции на день проведения операции без учета последней. Предполагается, что информация упорядочена по времени. Программа должна проверить, не нарушен ли хронологический порядок следования данных и нет ли где-нибудь изъятия средств, превышающего текущий счет. Программа должна отпечатать аккуратную таблицу платежных операций. При этом для каждой операции в выводимой строке должны быть указаны дата ее проведения, сумма инвестиций до операции, объем операции, сумма инвестиций после операции, доход на день проведения и сумма всех поступлений и платежей на текущий день. Каким именно образом обозначить конец вводимой информации — решать самому программисту, а вот равенство нулю суммы операции является удобным способом выяснения величины текущего дохода. Если у вас нет собственных инвестиций и вы не можете раздобыть Wall Street Journal[16], тогда исходными данными для программы, быть может не вполне удачными, зато реальными, может служить табл. 10.1.
Указания исполнителю. В рассматриваемой задаче существует интересный побочный вопрос. Даты проведения банковских операций задаются в обычном виде: месяц/число/год. А для решения задачи требуется иметь отрезки времени Ti, прошедшие после операции, выраженные в годах. У банкиров и юристов имеется несколько способов определения момента времени, когда прекращается начисление процентов на деньги (подозревают, что метод расчета зависит от того, кто кому должен). В программе достаточно вычислять годы в виде вещественных чисел с учетом високосных лет, предполагая, что все даты лежат в диапазоне от 1900 до 1999 включительно. Вообще говоря, перевод дат из одного календаря в другой может оказаться отнюдь не простым делом.
Инструментовка. Годится любой процедурный язык, предусматривающий действия с вещественными числами.
Длительность исполнения. Одному исполнителю на одну неделю.
При изучении табл. 10.1 обратите внимание, что величина А получается суммированием среднего и правого столбцов таблицы. Например, для третьей строки А = 189.82 долл., P1 = 68.26 долл., Р2 = 50.00 долл., Р3 = 75.00 долл., a T1 ≃ 85/365, Т2 ≃ 31/365, Т3 = 0. Заметим также, что для каждой строки таблицы оценка Y0 считается равной нулю и что расчет дохода для любой текущей даты не зависит от величины доходов в предшествующие времена.
Тема. Напишите программу вычисления дохода от вложенного капитала. Исходные данные представляют собой записи о проведенных операциях, в каждой из которых указываются дата, сумма операции и величина инвестиции на день проведения операции без учета последней. Предполагается, что информация упорядочена по времени. Программа должна проверить, не нарушен ли хронологический порядок следования данных и нет ли где-нибудь изъятия средств, превышающего текущий счет. Программа должна отпечатать аккуратную таблицу платежных операций. При этом для каждой операции в выводимой строке должны быть указаны дата ее проведения, сумма инвестиций до операции, объем операции, сумма инвестиций после операции, доход на день проведения и сумма всех поступлений и платежей на текущий день. Каким именно образом обозначить конец вводимой информации — решать самому программисту, а вот равенство нулю суммы операции является удобным способом выяснения величины текущего дохода. Если у вас нет собственных инвестиций и вы не можете раздобыть Wall Street Journal[16], тогда исходными данными для программы, быть может не вполне удачными, зато реальными, может служить табл. 10.1.
Указания исполнителю. В рассматриваемой задаче существует интересный побочный вопрос. Даты проведения банковских операций задаются в обычном виде: месяц/число/год. А для решения задачи требуется иметь отрезки времени Ti, прошедшие после операции, выраженные в годах. У банкиров и юристов имеется несколько способов определения момента времени, когда прекращается начисление процентов на деньги (подозревают, что метод расчета зависит от того, кто кому должен). В программе достаточно вычислять годы в виде вещественных чисел с учетом високосных лет, предполагая, что все даты лежат в диапазоне от 1900 до 1999 включительно. Вообще говоря, перевод дат из одного календаря в другой может оказаться отнюдь не простым делом.
Инструментовка. Годится любой процедурный язык, предусматривающий действия с вещественными числами.
Длительность исполнения. Одному исполнителю на одну неделю.
Литература
* Аникин А. В. Кредитная система современного капитализма. — М.: Наука, 1964. Эту книгу можно рекомендовать читателю, желающему подробнее ознакомиться с деятельностью различных финансовых институтов капиталистических стран, особенно США.11. Меньше copy — меньше и вздору, или Избыточность текста и сжатие файла
Все знают, что большинству людей свойственно излишнее многословие. Гораздо менее широко известно, что даже самые лаконичные высказывания можно было бы значительно сократить. Вообще, естественные языки отличаются чрезвычайной избыточностью. Даж есл нсклко бкв вбрсть, эт прдлжн ещ мжн прчть. Языки, используемые для вычислений, обладают той же особенностью. Для экономии памяти компьютера, объем которой ограничен, имеет смысл ликвидировать избыточность текста. Существует несколько способов уплотнения текста. Самый очевидный из них — поиск различных по длине цепочек из одной повторяющейся литеры. Такая группа может быть заменена тройкой литер mcn, где m обозначает признак повторения, специальную литеру, не используемую нигде в тексте для других целей, с — сама повторяющаяся литера и n — длина цепочки. Один такой триграф[17] экономит n — 3 литер, причем значение n не может превышать максимального числа, представимого в поле одной литеры. Описанный способ обработки весьма неплохо оправдывает себя для текстов, содержащих длинные цепочки повторяющихся литер, например длинные цепочки пробелов, характерных для большинства программ. К сожалению, этот прием не столь хорош для других текстов, поскольку большинство данных не отличается такой же строгой формой записи, как программы. Второй способ основан на том, что в различных системах кодировки литер, применяемых на ЭВМ, большинство литер практически не используется (из 256 литер обычного 8-разрядного кода, как правило, употребляется лишь около 100). Сначала в тексте отыскиваются наиболее распространенные диграфы, и каждому из них ставится в соответствие одна из не используемых в тексте одиночных литер. Уплотнение текста производится при просмотре его слева направо путем последовательной замены выявленных диграфов их однолитерными эквивалентами. При этом может быть достигнута значительная экономия, поскольку, например, 150 наиболее часто встречающихся диграфов уже составляют большу́ю долю текста на естественном языке. И если не ставить целью слишком высокую степень уплотнения текста, можно написать довольно эффективные программы кодирования и декодирования, работающие с машинным представлением литер. Однако существуют все же определенные трудности. Кто сказал, что наиболее часто встречающиеся диграфы в английском тексте должны быть теми же, что и во французском, или в наборе файлов, содержащих почтовые адреса, или в тексте на Алголе? А если даже это и так, то как насчет триграфов, квадриграфов или более длинных групп? Ведь более длинные группы, даже если они и реже встречаются, дают большую экономию, а бывает, что определенный фрагмент появляется в большом куске текста намного чаще, чем можно было бы ожидать. И, возвращаясь назад, как подсчитать частоты появления диграфов? Ответ на все эти вопросы содержится в третьем подходе к решению исходной задачи. Вместо того чтобы употреблять некоторый, заранее заданный набор кодировок, можно на ходу генерировать кодовый словарь, используя непосредственно текст, подлежащий сжатию, или выборку из него. Поскольку при этом каждый элемент текста будет участвовать в создании своего собственного словаря, исчезнут трудности, вызванные неудачными аббревиатурами. Теперь нам надо найти способ построения такого словаря. Опишем наш план действий в общих чертах. Начинаем с пустого словаря. Текст просматриваем слева направо. Ищем в словаре гнездо возможно большей длины, совпадающее с головной частью текста, и увеличиваем счетчик частоты соответствующего гнезда словаря. Если совпадений цепочек нет, образуем новое гнездо словаря и помещаем туда первую букву текста. Вычеркиваем обработанную цепочку из начала текста и начинаем просмотр заново. При обстоятельствах, поясняемых ниже, иногда два гнезда словаря соединяются в одно, образуя цепочку большей длины — процесс укрупнения гнезд. Когда словарь переполняется, производим его чистку, удаляя наиболее редко встречающиеся гнезда, и продолжаем просмотр. После того как частоты встречаемости гнезд словаря стабилизируются, вводим таблицу кодировок и, взяв исходный текст, полностью его кодируем. В предложенной схеме есть два невыясненных момента: каким образом происходит укрупнение гнезд словаря и как осуществляется его чистка? Укрупнение двух гнезд словаря производится в случае, когда одно из них следует в тексте непосредственно за другим и частоты обоих гнезд превышают некоторое пороговое значение. При этом, чтобы новое гнездо словаря не подвергалось ближайшей чистке, ему может быть приписана начальная частота несколько выше обычной. Таким образом, если в словаре уже имеются, например, цепочки КОН и ТАКТ, то при условии, что содержимое их счетчиков достаточно велико, может образоваться новое гнездо словаря, содержащее цепочку КОНТАКТ. Что лее касается чистки словаря, то существует простой способ — удалять все те гнезда, значения счетчиков которых меньше среднего. Можно действовать и иначе — выбрасывать все гнезда, частота которых ниже медианы частот. Годятся и другие, подобные этому способы.Алгоритм построения словаря
В приводимом алгоритме предполагается, что построение словаря производится с помощью некоторой выборки из текста, подлежащего сжатию. Для алгоритма существенны все литеры текста, и если табуляция, концы строк и другие аналогичные элементы имеют значение, то в тексте должны присутствовать соответствующие управляющие литеры. Предполагается, что в начале работы словарь пуст. В начальный момент переменная last match содержит пустую цепочку, а переменная last count имеет значение, равное нулю. 1. Ищем в головной части входного текста возможно более длинную цепочку match, совпадающую с каким-нибудь гнездом словаря. Если переменная match пустая, засылаем в нее первую литеру входного текста, помещаем в свободное гнездо словаря и устанавливаем начальное значение счетчика этого нового гнезда равным единице. Если цепочка match не пустая, увеличиваем на единицу счетчик соответствующего гнезда словаря. Содержимое счетчика этого гнезда записываем в count. 2. Если либо count, либо last count меньше значения порога укрупнения гнезд, то переходим к шагу 4. Порог укрупнения определяется как отношение максимально допустимого объема словаря к числу оставшихся в данный момент свободных гнезд. 3. Образуем новое гнездо словаря путем объединения цепочек last match и match. Поскольку данное гнездо словаря возникло впервые, засылаем в его счетчик единицу. Можно применить и другие стратегии. 4. Если в словаре остались свободными менее двух гнезд, производим чистку, удаляя все гнезда с частотами меньше медианы частот. При этом, если окажется, что исключилось гнездо, содержащее match, устанавливаем count равным нулю. 5. Вычеркиваем match из начала входного текста. Если текст исчерпан, то алгоритм работу заканчивает — выход. В противном случае помещаем last match в match, пересылаем last count в count и возвращаемся к шагу 1.Кодирование и декодирование
Как только построение словаря завершилось, необходимо составить таблицы для кодирования и декодирования. Образуем все возможные диграфы, начинающиеся с литеры, которая нигде в тексте не используется. Исключим из словаря все гнезда, состоящие из одной или двух литер (их уплотнение экономии дать не может). Упорядочим оставшиеся цепочки по частоте встречаемости. Поставим в соответствие гнездам словаря полученные выше кодирующее диграфы, начиная с гнезд, имеющих наибольшую частоту. Формирование таблицы кодировок завершается по исчерпании гнезд словаря или набора диграфов. Процесс кодирования текста подобен процедуре построения словаря. На каждом этапе головная часть входного текста проверяется на совпадение в возможно большем числе позиций с гнездами словаря. Совпавшая цепочка заменяется в тексте соответствующим кодирующим диграфом, и начало просмотра входного текста сдвигается на длину выделенной цепочки. Если же в словаре не найдено нужного гнезда, в выходной текст просто переносится первая литера из головной части входного текста и начало просмотра перемещается вправо на одну позицию. Декодирование осуществляется путем простой замены кодирующих диграфов их эквивалентами из словаря. Тема. Напишите программу, реализующую описанные выше алгоритмы построения словаря, кодирования и декодирования. Проверьте программу на достаточно больших фрагментах текста на естественном языке и языке программирования. Коэффициент сжатия данного куска текста определяется как частное от деления суммы длин сжатого текста и словаря на дайну исходного текста. Проведите небольшое исследование зависимости коэффициента сжатия от какого-нибудь из следующих параметров: языка уплотняемого текста; объема используемой для упражнения выборки из текста; длины словаря при его построении; имеющегося количества кодирующих диграфов или применимости словаря, полученного на основании одного текста, для другого текста на том же языке. Указания исполнителю. Данная задача интересна тем, что для ее эффективного решения требуется употребить некоторые весьма развитые алгоритмы и структуры данных. Однако пусть не столь эффективную, но правильно работающую программу можно написать, используя простые алгоритмы и структуры, которые можно, когда программа заработает, постепенно заменять более изящными конструкциями. Одним из примеров служит вычисление медианы для чистки словаря. В качестве первого варианта можно просто выбрасывать гнезда словаря с частотами, меньшими средней. При этом среднюю частоту легко вычислить за один полный просмотр всех частот словаря. А после того как такая программа в целом заработает, можно уже для нахождения порога исключения строк подключить болте сложную программу расчета медианы. Другим примером является выбор структуры словаря на этапах его создания и кодирования. Если гнезда словаря расположить в случайном порядке, то при проверках на совпадение необходимо проходить весь словарь. Однако при такой структуре появляющиеся новые гнезда добавляются просто в конец словаря. Небольшое усложнение могло бы заключаться в группировке гнезд словаря по их длинам. Тогда поиск мог бы осуществляться в направлении от самых длинных групп к коротким и прекращаться при первом же удачном сравнении. Если каждую группу еще и лексикографически упорядочить, то можно было бы воспользоваться вместо линейного поиска внутри группы двоичным поискам, экономя таким образом время. Но зато добавление в словарь новых гнезд становится в этом случае более сложным, так как для любого нового гнезда потребуется место, скорее всего, где-то в середине группы. Не исключено, что самой выгодной структурой для организации поиска окажется какая-либо разновидность дерева. Разыскиваемую цепочку словаря могла бы тогда составить последовательность букв по пути от корня дерева к его листьям, или, иначе говоря, в узлах некоего подобия двоичного дерева поиска могли бы располагаться соответствующие строки словаря. В то же время при составлении словаря деревья потребуют намного большей обработки, нежели описанные выше более простые структуры. Инструментовка. Вследствие разнообразия структур данных, используемых в готовой программе, исходный язык должен обладать хорошими средствами описания данных. В этом плане можно рекомендовать Паскаль, Алгол-68 и PL/I. Можно было бы предложить сначала написать программу на Сноболе, опираясь на заложенные в этом языке средства сопоставления с образцом, а затем переписать готовую программу на каком-нибудь более эффективном при массовых расчетах языке. При использовании этого пути необходимо быть внимательными и избегать употребления таких средств Снобола, которые трудно воспроизвести на другом языке. Длительность исполнения. Одному исполнителю на 3 недели. Развитие темы. В описанной модели имеются три области свободы: критерий укрупнения гнезд, критерий исключения низкочастотных гнезд словаря и система их кодирования. Рассматривая их по-порядку, начнем с критерия укрупнения гнезд. Для того чтобы могло произойти укрупнение гнезд, в нашем алгоритме требуется, чтобы частоты встречаемости каждого из двух последовательных гнезд превысили один и тот же крайний предел. Можно, однако, для каждого гнезда иметь свой порог. В другом варианте может быть у одного гнезда постоянный порог, а у другого — порог, являющийся функцией средней частоты гнезд. Аналогично может варьироваться начальная частота укрупненного гнезда, причем при любом способе начальная частота задается большой исходя из условия повышения шансов на сохранение данного гнезда при чистке. Точно так же может быть видоизменен образ действий при исключении гнезд словаря во время его чистки. Можно выбрасывать неизменную часть низкочастотных гнезд (используя медиану, устанавливающую эту часть равной половине). Можно исключать все гнезда с частотами, меньшими некоторой, кратной средней частоте. Или же можно вычеркивать все гнезда с частотами, меньшими заданной, и эту процедуру осуществлять до тех пор, пока словарь не будет достаточно вычищен. Сочетание различных способов укрупнения и чистки гнезд характеризуется особым показателем исключаемости. В некоторых вариантах оставляются цепочки, которые часто встречаются в одной части текста и реже в других; в иных случаях предпочтение отдается цепочкам, равномерно разбросанным по тексту. Какому показателю исключаемости отдать предпочтение, зависит от используемых особенностей как словаря, так и текста. В алгоритме кодирования употребляются диграфы, начинающиеся с не используемых во входном тексте литер. Однако, если набор диграфов кончился, а словарь еще не доделан, можно использовать триграфы и т. д. Коль скоро частоты гнезд словаря известны, их можно употребить для организации взвешенного кодирования переменной длины. Этот способ будет дороже при декодировании (почему не при кодировании?), зато обеспечит даже более высокую степень сжатия текста.Литература
Мэйн, Джеймс (Маупе A., James Е. В.). Information Compression by Factorising Common Strings. Comput. J., 18, 2, pp. 157–160, 1975. Этот этюд представляет собой в основном переформулировку работы Мэйна и Джеймса. Надо заметить, что наш алгоритм более прозрачен, а их работа содержит ряд существенных результатов. Кнут (Knuth D. E.). The Art of Computer Programming, Volume 3/Sorting and Searching. Addison-Wesley, Reading, MA, 1973. [Имеется перевод: Кнут Д. Искусство программирования для ЭВМ, Т. 3. Сортировка и поиск. — M.i Мир, 1978.] Хотя чтение любой части книги Кнута доставляет массу удовольствия, представляется, что обсуждаемому вопросу наиболее соответствует материал разд. 6.2 о дереве поиска.12. В духе добрососедства, или Домашняя бухгалтерия
Кооперативы — довольно характерное явление в студенческой жизни. Иногда несколько студентов просто вместе платят за квартиру; порой они связаны друг с другом тесными и официальными общинными узами. Однако в любом случае им нужно вести и оплачивать счета. Немало общин распалось из-за денег, и, хотя более глубоких проблем ЭВМ решить не могут, честно вести расчеты они в состоянии. Как правило, счета присылают в конце месяца, как раз после самой крупной траты — внесения платы за квартиру. В течение месяца каждый член группы платит за все из своего кармана. Пошел в магазин — плати за продукты, открыл дверь — плати разносчику газет, сел за руль — плати за бензин. При удачном стечении обстоятельств большинство членов группы заплатит примерно свою долю, но уж, конечно, точного соответствия не получится никогда. Если расходы распределяются не поровну, расчет не сводится к простому делению. Обычно кто-нибудь не прочь платить побольше, но иметь ещеодну комнату; тот, кто выходные проводит у родителей, платит за еду несколько меньше других и т. п. И разумеется, каждый может потратить деньги по своему усмотрению, например на междугородный телефонный разговор или пиво, что не будет фиксироваться в ежемесячном групповом расчете. Чтобы учесть отмеченные нами и подобные им обстоятельства, нужна устоявшаяся бухгалтерская система. Тема. Напишите программу, обеспечивающую небольшую общину постатейно расписанными счетами. Исходные данные подразделяются на четыре части. Первая часть должна содержать фамилии тех, кто участвует в расходах в текущем месяце. Во второй части перечисляются основные статьи расходов, такие, как питание, квартплата, коммунальные услуги. За каждой статьей должен следовать список членов общины и их доли в общих расходах. Доля может выражаться как в долларах, так и в процентах. Если вся статья распределена явным образом, то остаток делится поровну между остальными членами. Например, если квартплата составляет 200 долл., студент А взялся платить 45 долл., а В — 35%, то на всех остальных членов общины приходятся равные доли от 85 долл. Элементами третьей части исходных данных должны быть записи об общественно полезных расходах. Запись содержит дату, фамилию члена группы, уплаченную сумму, статью расхода и краткое описание. Четвертая часть содержит сходную информацию, но о расходах на личные нужды. Каждая запись в этой части имеет ту же структуру, что и в части 3, с очевидным дополнением — указывается фамилия человека, на нужды которого истрачены деньги. Исходные данные необходимо проверить на непротиворечивость, обращая особое внимание на даты, размеры платежей, фамилии и статьи расходов. Выходная информация также должна подразделяться на несколько частей. Во-первых, каждому члену группы нужно предоставить хронологический список всех платежей и приходов в данном месяце. Во-вторых, каждый должен получить такой же список, упорядоченный по статьям и датам. В этом списке необходимо указать долговые обязательства каждого члена по каждой статье и их разложение на пай и приход. Наконец, все должны узнать свое финансовое положение на конец месяца. Должники пусть знают, кому платить, а те, кому задолжали, пусть знают, с кого требовать деньги. Желательно, чтобы программа по возможности минимизировала число таких балансовых действий. Заключительная часть вывода должна включать хронологический перечень всех расходов на общественные нужды и таблицу (люди/статьи), в которой приведены расходы, приходы, паи и сбалансированные долговые обязательства. Перекрестное суммирование таблицы позволит оценить точность бухгалтерии. Указания исполнителю. Ничего особо сложного в предложенной задаче нет. Конечно, эффективная программа всегда лучше неэффективной, но в данном случае время счета мало по сравнению с временем ввода/вывода. Основного внимания требуют разнообразный формат исходных данных к элегантная организация проверки данных на непротиворечивость. А в общем это прозаическая программа, как и большинство производственных программ. Дайте «профессиональное» решение. Инструментовка. Хотя Кобол — лучшее средство, можно использовать почти любой процедурный язык. Длительность исполнения. Одному исполнителю на 2 недели. Развитие темы. Существенная особенность коммерчески-ориентированных языков — точные вычисления и отредактированный вывод долларовых величин. При вычислениях с вещественными числами ошибки округления местами могут достигать нескольких центов; перекрестные проверки при этом дадут разные результаты. Уместно написать несложные подпрограммы для операций с числами с фиксированной точкой (но не с целыми числами!). Если вы напишите программу на Фортране, вам придется уяснить, как печатать эти надоедливые плавающие знаки доллара, «хвостовые> указатели кредита и левые нули. Если применяется Кобол или PL/I, таких трудностей не возникает.13. Тур по Тьюрингу, или Моделирование машины Тьюринга
Задолго до появления первых универсальных цифровых вычислительных машин вопрос об ограничениях на вычисления, которые могли бы выполнять машины, заинтересовал Алана Тьюринга. Чтобы быть уверенным, что мощь его гипотетической машины не обусловлена каким-либо хитрым механизмом, Тьюринг исключил почти все возможности, которые существенны для реальных компьютеров. Осталась лишь программная память простого вида, не допускающая изменений во время выполнения, только один тип команд и простая лента для ввода и вывода. Тем не менее это устройство — машина Тьюринга, предмет обожания студентов-логиков в последние 40 лет — способно повторить все вычисления любого современного цифрового компьютера. Но какой мерзкой была бы задача промоделировать, скажем, IBM 370/155 на машине Тьюринга! К счастью, перед нами стоит куда более приятная обратная задача. Машина Тьюринга состоит из устройства управления, которое с помощью головки связано с лентой ввода/вывода. Лента — это длинная полоска, разделенная на ячейки, каждая из которых может содержать одну литеру; лента простирается вправо до бесконечности (иными словами, на правом конце ленты находится небольшая фабрика, производящая по мере необходимости дополнительную ленту). Головка указывает на какую-то одну ячейку ленты и может читать содержимое ячейки, записывать и перемещаться вправо или влево. В начале работы исходные данные всегда заполняют левую часть ленты, а головка читает самую левую ячейку ленты. Когда головка, двигаясь вправо, достигает ячейки, которая не является частью исходных данных и никогда ранее не обозревалась головкой, считается, что в этой ячейке записан пробел, обозначаемый ø. Устройство управления выполняет программу, подчиняясь строгим правилам. В любой момент времени устройство управления находится в некотором состоянии, которое записано в регистре текущее состояние. Состояния обозначаются положительными целыми числами. Каждая команда программы представляет собой пятерку, составленную из состояния, литеры, еще одного состояния, еще одной литеры и направления движения ленты. Цикл выполнения команды начинается с того, что устройство управления сравнивает текущее состояние и литеру на ленте под головкой с первыми двумя компонентами всех команд. По правилам программирования для машины Тьюринга в программе может быть не более одной пятерки с какой-либо определенной начальной парой состояние-литера (но может и не быть ни одной). Когда совпадение найдено, устройство управления выполняет три действия: в ячейку ленты под головкой записывается литера, являющаяся четвертой компонентой пятерки; головка передвигается на одну ячейку влево или вправо или остается на месте, как указано в пятой компоненте пятерки; текущее состояние заменяется на третью компоненту. После этого машина готова к следующему циклу. По соглашению, работа начинается в состоянии 1 при описанном выше состоянии ленты. Машина останавливается, если в цикле выполнения не удается найти совпадения с текущей парой состояние-литера или если головка выходит за левый край ленты; при этом результатом работы считается все, что остается на ленте после остановки. Отметим, что программа может содержать лишь конечное число команд, так что для любой программы осмысленно только конечное число состояний и литер. Для пояснения изложения полезно привести пример. Пусть мы хотим написать программу для машины Тьюринга, которая будет строить сумму двух целых чисел. Целое число п будет изображаться на ленте n последовательными значками * (отсутствие звездочек соответствует нулю), два исходных числа будут разделены запятой, и если исходные данные представляют n + m, то результатом должны быть n + m звездочек, расположенных у левого края ленты. Так, чтобы вычислить 7 + 4, следует записать в качестве исходных данных *******,**** результатом должно быть *********** Структура программы проста. Сначала головка движется вправо в поисках запятой (не забывайте, что первоначально головка стоит над крайней левой ячейкой исходных данных). Запятая заменяется звездочкой, и головка продолжает движение, отыскивая пробел, ограничивающий справа исходные данные. Головка возвращается на одну ячейку назад и записывает пробел на место находящейся там звездочки, после чего программа завершается. Легко видеть, что при построении суммы одна звездочка добавляется в середине и одна убирается с правого края. Программа приведена в табл. 13.1. Чтобы изобразить состояние машины Тьюринга, можно напечатать все ячейки ленты, которые когда-либо рассматривались, и среди них — текущее состояние непосредственно слева от ячейки, находящейся под головкой в данный момент; такой способ мы будем считать стандартным. Мы получаем моментальный снимок; следующий пример показывает начало сложения 2 и 3:
1**,***
На рис. 13.1 показана последовательность моментальных снимков для всего вычисления. Отметим, что программа останавливается в состоянии 3, поскольку в ней не предусмотрены действия для пробела. Состояние 4 возникает только, если в исходных данных имеется ошибка; в этом случае машина попадает в бесконечный цикл. Убедитесь, что программа работает, если любое из исходных чисел (или оба) равно нулю.
Чтобы изобразить состояние машины Тьюринга, можно напечатать все ячейки ленты, которые когда-либо рассматривались, и среди них — текущее состояние непосредственно слева от ячейки, находящейся под головкой в данный момент; такой способ мы будем считать стандартным. Мы получаем моментальный снимок; следующий пример показывает начало сложения 2 и 3:
1**,***
На рис. 13.1 показана последовательность моментальных снимков для всего вычисления. Отметим, что программа останавливается в состоянии 3, поскольку в ней не предусмотрены действия для пробела. Состояние 4 возникает только, если в исходных данных имеется ошибка; в этом случае машина попадает в бесконечный цикл. Убедитесь, что программа работает, если любое из исходных чисел (или оба) равно нулю.
 Рисунок 13.1. Последовательность моментальных снимков.
Наш пример программы может показаться слишком простым. Попробуйте изменить программу, чтобы она выполняла не сложение, а умножение. Для машины Тьюринга единичная система счисления более естественна, чем любая другая; программа сложения десятичных чисел будет длиннее и сложнее. В литературе, указанной в библиографии, можно найти гораздо более подробный материал о машине Тьюринга и обоснование того, что машина Тьюринга может выполнить любое вычисление, выполнимое на какой-либо другой машине. Вы обнаружите небольшие отличия в разных описаниях машины Тьюринга и там же — доказательства того, что эти отличия ни на что не влияют.
Тема. Напишите универсальный имитатор машины Тьюринга. Входными данными будут: программа для машины Тьюринга, ее исходные данные и (по причине, которая будет объяснена позже) начальное состояние машины. Результатом должны быть трассировка работы машины и ее окончательное состояние. Поскольку машина Тьюринга вовсе не всегда останавливается, причем заранее нельзя предсказать, остановится она или нет (если вы не понимаете, почему это так, обратите внимание на проблему остановки), необходимо как-то контролировать объем печати имитатора и расходуемое им время. Проверьте имитатор на нескольких программах, аналогичных рассмотренным выше.
Хотя в нашем описании именами состояний были положительные целые числа, ваш имитатор должен допускать в качестве имени состояния произвольный идентификатор. В предыдущем примере мы могли бы назвать состояния Начало, ДвижениеВправо, Конец и Ошибка, тогда одна из команд могла бы иметь вид
ДвижениеВправо ø Конец ø Влево
Теперь у нас нет выделенного первого состояния, поэтому его должен указать пользователь.
Указания исполнителю. При разработке данной программы, как и любого имитатора, перед нами стоит проблема эффективности. Если на протяжении всего выполнения используются имена состояний, то постоянно требуемый поиск займет значительное время. Скорость выполнения будет наибольшей, если представить программу для машины Тьюринга в виде двумерного массива, индексами в котором будут состояния и литеры. Элементы массива содержат команду, которую нужно выполнить; элемент специального вида указывает, что соответствующая пятерка отсутствует. Тут, конечно, определенную трудность представляет незнание необходимого размера этого массива до того, как будут прочитаны исходные данные. Отметим также, что необходимо проверить непротиворечивость исходных данных, т. е, убедиться, что никакие две пятерки не начинаются одной и той же парой состояние-литера.
Трассировочная информация должна печататься после каждого изменения состояния. Она должна включать в себя: содержимое всей ленты до самого правого непробела или до головки, в зависимости от того, что находится правее, положение головки и текущее состояние. Вероятно, содержимое ленты следует напечатать на одной строке, а указатель головки и состояние — на следующей. Руководствуйтесь соображениями красоты и ясности. Алфавит ленты, т. е. множество символов, которые могут появляться на ленте, есть просто набор литер, встречающихся где-либо во второй или четвертой компоненте пятерки. Программа должна позволять использовать любую нормальную литеру, имеющуюся в вашей системе. В алфавит всегда входит пробел. Его непросто изобразить в исходных данных, а появляясь в выходной строке, пробелы могут вносить неразбериху. Проблему с вводом можно обойти, если, например, разделять пять компонент команды запятыми. Работа со значащими пробелами часто вызывает затруднения. В естественных языках пробелы осмысленны, но обычно лишь как разделители слов, а не как полноправные символы. Таким образом не существует какого-либо стандартного соглашения об употреблении пробелов в качестве символов.
Инструментовка. Эта задача представляет собой еще один случай, когда почти любой язык имеет как достоинства, так и недостатки; следует, однако, избегать интерпретативных языков ввиду малого размера внутреннего цикла.
Длительность исполнения. Одному исполнителю на 1 неделю.
Рисунок 13.1. Последовательность моментальных снимков.
Наш пример программы может показаться слишком простым. Попробуйте изменить программу, чтобы она выполняла не сложение, а умножение. Для машины Тьюринга единичная система счисления более естественна, чем любая другая; программа сложения десятичных чисел будет длиннее и сложнее. В литературе, указанной в библиографии, можно найти гораздо более подробный материал о машине Тьюринга и обоснование того, что машина Тьюринга может выполнить любое вычисление, выполнимое на какой-либо другой машине. Вы обнаружите небольшие отличия в разных описаниях машины Тьюринга и там же — доказательства того, что эти отличия ни на что не влияют.
Тема. Напишите универсальный имитатор машины Тьюринга. Входными данными будут: программа для машины Тьюринга, ее исходные данные и (по причине, которая будет объяснена позже) начальное состояние машины. Результатом должны быть трассировка работы машины и ее окончательное состояние. Поскольку машина Тьюринга вовсе не всегда останавливается, причем заранее нельзя предсказать, остановится она или нет (если вы не понимаете, почему это так, обратите внимание на проблему остановки), необходимо как-то контролировать объем печати имитатора и расходуемое им время. Проверьте имитатор на нескольких программах, аналогичных рассмотренным выше.
Хотя в нашем описании именами состояний были положительные целые числа, ваш имитатор должен допускать в качестве имени состояния произвольный идентификатор. В предыдущем примере мы могли бы назвать состояния Начало, ДвижениеВправо, Конец и Ошибка, тогда одна из команд могла бы иметь вид
ДвижениеВправо ø Конец ø Влево
Теперь у нас нет выделенного первого состояния, поэтому его должен указать пользователь.
Указания исполнителю. При разработке данной программы, как и любого имитатора, перед нами стоит проблема эффективности. Если на протяжении всего выполнения используются имена состояний, то постоянно требуемый поиск займет значительное время. Скорость выполнения будет наибольшей, если представить программу для машины Тьюринга в виде двумерного массива, индексами в котором будут состояния и литеры. Элементы массива содержат команду, которую нужно выполнить; элемент специального вида указывает, что соответствующая пятерка отсутствует. Тут, конечно, определенную трудность представляет незнание необходимого размера этого массива до того, как будут прочитаны исходные данные. Отметим также, что необходимо проверить непротиворечивость исходных данных, т. е, убедиться, что никакие две пятерки не начинаются одной и той же парой состояние-литера.
Трассировочная информация должна печататься после каждого изменения состояния. Она должна включать в себя: содержимое всей ленты до самого правого непробела или до головки, в зависимости от того, что находится правее, положение головки и текущее состояние. Вероятно, содержимое ленты следует напечатать на одной строке, а указатель головки и состояние — на следующей. Руководствуйтесь соображениями красоты и ясности. Алфавит ленты, т. е. множество символов, которые могут появляться на ленте, есть просто набор литер, встречающихся где-либо во второй или четвертой компоненте пятерки. Программа должна позволять использовать любую нормальную литеру, имеющуюся в вашей системе. В алфавит всегда входит пробел. Его непросто изобразить в исходных данных, а появляясь в выходной строке, пробелы могут вносить неразбериху. Проблему с вводом можно обойти, если, например, разделять пять компонент команды запятыми. Работа со значащими пробелами часто вызывает затруднения. В естественных языках пробелы осмысленны, но обычно лишь как разделители слов, а не как полноправные символы. Таким образом не существует какого-либо стандартного соглашения об употреблении пробелов в качестве символов.
Инструментовка. Эта задача представляет собой еще один случай, когда почти любой язык имеет как достоинства, так и недостатки; следует, однако, избегать интерпретативных языков ввиду малого размера внутреннего цикла.
Длительность исполнения. Одному исполнителю на 1 неделю.
Литература
Дэвис (Davis M.). Computability and Unsolvability, McGraw-Hill, New York, NY, 1958. Дэвис приводит с изматывающими подробностями все те доказательства, которые другие авторы «оставляют читателю». Прочитав Дэвиса от корки до корки, вы уже никогда не усомнитесь в справедливости любого утверждения о мощи машины Тьюринга. Впрочем, вполне возможно, что у вас навсегда пропадет охота что бы то ни было слышать об этой машине. Хопкрофт, Ульман (Hopcroft J. E., Ullman J. D). Formal Languages and Their Relation to Automata. Addison-Wesley, Reading, MA, 1969. Книга Хопкрофта и Ульмана — наилучший в своей области учебник для аспирантов первого года обучения. В ней содержатся все основные результаты о машинах Тьюринга, причем они излагаются в контексте других классов автоматов Книга полезна также своей обширной библиографией. Минский (Minsky M. L.). Computation: Finite and Infinite Machines. Prentice-Hall, Englewood Cliffs NJ, 1967. Минский дает прекрасное, легко воспринимаемое введение в теорию автоматов. Это, вероятно, наиболее подходящая книга для первого знакомства с предметом. *Трахтенброт Б. А. Алгоритмы и вычислительные автоматы. — М.: Советское радио, 1974.14. Машинные забавы, или Стратегия компьютера при игре в калах
Дискуссии о «разумном» поведении компьютеров начались задолго до появления реальных вычислительных машин. Многие согласятся, что высокое мастерство в какой-либо интеллектуальной игре, не поддающейся полному анализу, должно свидетельствовать о незаурядных умственных способностях игрока. Если компьютер к тому же обучаем, то отрицать его интеллект еще труднее. Говоря о машинной игре, чаще всего имеют в виду шахматы, однако даже самые лучшие программы оказываются на уровне весьма посредственных шахматистов. Но в других играх можно достичь большего успеха. Калах, известный также и под другими названиями (манкала, вари, овари), — это старинная африканская игра. По ее теории написано очень мало, тем не менее в течение столетий в калах играют с помощью камешков представители самых разных культур. Хотя игра эта — чистая борьба умов, не содержащая какого-либо случайного элемента, африканцы режутся в нее постоянно. Благодаря нехитрому инвентарю и простым правилам, калах великолепно подходит и для игры с машиной. Как показывают современные исследования, компьютер с программой наподобие предлагаемой здесь играет в калах лучше любого человека. Игровое поле для калаха схематически изображено на рис. 14.1. Игроки (их двое) садятся друг против друга. Каждому игроку принадлежат шесть малых лунок вдоль длинной стороны поля и одна лунка большего размера по его правую руку, называемая калахом. В начале игры в каждую малую лунку помещается некоторое количество к камней (для k ≤ 3 известно полное решение; африканцы обычно используют k = 6). Ход игрока заключается в том, что он забирает все камни в одной из малых лунок на своей стороне и раскладывает их по одному в остальные лунки, двигаясь против часовой стрелки. Первый камень кладется в лунку справа от той, из которых взяты камни, затем в следующие, включая свой калах и малые лунки противника, но не калах противника. Может случиться (и это допускается правилами), что раскладывая камни, мы обойдем всю доску и вернемся в исходную лунку или даже пройдем дальше. На рис. 14.2а и b, показаны позиции до и после выполнения такого циклического хода. Рисунок 14.1. Игровое поле для калаха. Числа в лунках показывают количество находящихся там камней.
Рисунок 14.1. Игровое поле для калаха. Числа в лунках показывают количество находящихся там камней.
 Рисунок 14.2а. Перед циклическим ходом Макса. Макс ходит из лунки 6.
Рисунок 14.2а. Перед циклическим ходом Макса. Макс ходит из лунки 6.
 Рисунок 14.2b. После циклического хода Макса. Калах Макса пополнялся дважды.
Есть два дополнения к правилу выполнения хода. Если последний камень попал в одну из непустых малых лунок игрока, делавшего ход, причем камни клались и в лунки противника, то делается повторный ход из лунки, в которую попал последний камень, по тем же правилам, что и первый. Игрок может сделать сколь угодно длинную серию повторных ходов. Если последний камень попал в одну из малых лунок противника, и в этой лунке стало два или три камня, то эти камни берутся в плен и помещаются в калах игрока, сделавшего ход. Если при пленении в предыдущей лунке также оказалось два или три камня, то и они забираются в плен. Теоретически игрок может за один ход полностью очистить сторону противника. Игра оканчивается, как только в калахе одного из игроков окажется больше половины всех камней (заметим, что если камень попал в калах, то он уже никогда его не покинет). Если у игрока, получившего очередь хода, не осталось ни одного камня в малых лунках, то игра немедленно прекращается и все камни противника попадают в калах противника. На рис. с 14.3 по 14.5 показаны некоторые типичные ходы.
Рисунок 14.2b. После циклического хода Макса. Калах Макса пополнялся дважды.
Есть два дополнения к правилу выполнения хода. Если последний камень попал в одну из непустых малых лунок игрока, делавшего ход, причем камни клались и в лунки противника, то делается повторный ход из лунки, в которую попал последний камень, по тем же правилам, что и первый. Игрок может сделать сколь угодно длинную серию повторных ходов. Если последний камень попал в одну из малых лунок противника, и в этой лунке стало два или три камня, то эти камни берутся в плен и помещаются в калах игрока, сделавшего ход. Если при пленении в предыдущей лунке также оказалось два или три камня, то и они забираются в плен. Теоретически игрок может за один ход полностью очистить сторону противника. Игра оканчивается, как только в калахе одного из игроков окажется больше половины всех камней (заметим, что если камень попал в калах, то он уже никогда его не покинет). Если у игрока, получившего очередь хода, не осталось ни одного камня в малых лунках, то игра немедленно прекращается и все камни противника попадают в калах противника. На рис. с 14.3 по 14.5 показаны некоторые типичные ходы.
 Рисунок 14.3a. Серия ходов из лунки 6 Макса. Последний камень попадает в лунку 3 Макса, и из этой лунки делается повторный ход.
Рисунок 14.3a. Серия ходов из лунки 6 Макса. Последний камень попадает в лунку 3 Макса, и из этой лунки делается повторный ход.
 Рисунок 14.3b. После серии ходов. Камни из лунки 3 разложены в следующие лунки.
Рисунок 14.3b. После серии ходов. Камни из лунки 3 разложены в следующие лунки.
 Рисунок 14.4а. Перед взятием в плен камней Мима. Ходом из лунки 3 Макс попадает в лунку 4 Мина.
Рисунок 14.4а. Перед взятием в плен камней Мима. Ходом из лунки 3 Макс попадает в лунку 4 Мина.
 Рисунок 14.4b. После взятия в плен камней из лунки 4 Мина. В калах Макса один камень попадает при раскладывании камней и еще три — при пленении.
Рисунок 14.4b. После взятия в плен камней из лунки 4 Мина. В калах Макса один камень попадает при раскладывании камней и еще три — при пленении.
 Рисунок 14.5а. Многократный захват пленных Максом. Камни из лунок Мина 2, 3 и 4 берутся в плен одним ходом из лунки 6.
Рисунок 14.5а. Многократный захват пленных Максом. Камни из лунок Мина 2, 3 и 4 берутся в плен одним ходом из лунки 6.
 Рисунок 14.5b. Макс почти опустошил лунки Мина. Отметим, что Макс мог бы сделать ход с пленением из лунки 5 вместо лунки 6.
Программа для проверки правильности хода весьма проста. Выбор игрока ограничен максимум шестью возможностями для хода. После того как начальная лунка выбрана, легко находятся повторные ходы и взятия в плен. Для проверки окончания игры после хода надо лишь сравнить калах игрока, делавшего ход, с половиной общего числа камней. Конечно, отсюда никоим образом не следует, как находить наилучший в данной позиции ход.
Основная идея выбора хода состоит в построении дерева всех возможных продолжений из заданной позиции. Затем мы выбираем такую ветвь дерева, которая обеспечивает в конце концов победу. Для простоты изложения и еще по одной причине, которая вскоре станет понятной, мы будем называть компьютер Максом, а его противника — Мином. Предположим, что где-то в середине игры настала очередь хода компьютера. Макс может попытаться оценить положение, испробовав поочередно каждый из шести возможных ходов. Если один из них сразу же приводит к выигрышу, то Максу, очевидно, следует делать именно этот ход. Но что делать Максу, если ни один ход не ведет к немедленной победе? Как выбрать ход?
Максу следует проанализировать каждый ответ Мина на свои ходы. Допустим, один из этих ответов приводит к выигрышу Мина. Со стороны Макса было бы глупо делать ход, дающий Мину шанс на немедленную победу (хотя иногда Максу не избежать этого). В таком случае Макс узнает, какие ходы не делать. Однако, чтобы выбрать, какой ход делать, Максу придется построить еще один уровень ответов на ответы Мина к исходным ходам Макса. Если можно найти выигрышный ответ для некоторого множества ответов Мина, то Максу следует выбрать тот первоначальный ход, при котором Мину остаются только ответы, для которых есть выигрышный ответ Макса (помните дом, который построил Джек?). Если все это непонятно, попробуйте найти ходы, ответы и ответы на ответы для позиции с рис. 14.6.
Рисунок 14.5b. Макс почти опустошил лунки Мина. Отметим, что Макс мог бы сделать ход с пленением из лунки 5 вместо лунки 6.
Программа для проверки правильности хода весьма проста. Выбор игрока ограничен максимум шестью возможностями для хода. После того как начальная лунка выбрана, легко находятся повторные ходы и взятия в плен. Для проверки окончания игры после хода надо лишь сравнить калах игрока, делавшего ход, с половиной общего числа камней. Конечно, отсюда никоим образом не следует, как находить наилучший в данной позиции ход.
Основная идея выбора хода состоит в построении дерева всех возможных продолжений из заданной позиции. Затем мы выбираем такую ветвь дерева, которая обеспечивает в конце концов победу. Для простоты изложения и еще по одной причине, которая вскоре станет понятной, мы будем называть компьютер Максом, а его противника — Мином. Предположим, что где-то в середине игры настала очередь хода компьютера. Макс может попытаться оценить положение, испробовав поочередно каждый из шести возможных ходов. Если один из них сразу же приводит к выигрышу, то Максу, очевидно, следует делать именно этот ход. Но что делать Максу, если ни один ход не ведет к немедленной победе? Как выбрать ход?
Максу следует проанализировать каждый ответ Мина на свои ходы. Допустим, один из этих ответов приводит к выигрышу Мина. Со стороны Макса было бы глупо делать ход, дающий Мину шанс на немедленную победу (хотя иногда Максу не избежать этого). В таком случае Макс узнает, какие ходы не делать. Однако, чтобы выбрать, какой ход делать, Максу придется построить еще один уровень ответов на ответы Мина к исходным ходам Макса. Если можно найти выигрышный ответ для некоторого множества ответов Мина, то Максу следует выбрать тот первоначальный ход, при котором Мину остаются только ответы, для которых есть выигрышный ответ Макса (помните дом, который построил Джек?). Если все это непонятно, попробуйте найти ходы, ответы и ответы на ответы для позиции с рис. 14.6.
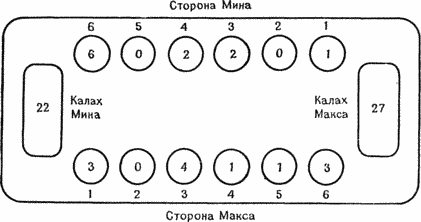 Рисунок 14.6а. Ход Макса. Макс ходит из лунки 1.
Рисунок 14.6а. Ход Макса. Макс ходит из лунки 1.
 Рисунок 14.6b. Результат хода Макса. Мин отвечает ходом из лунки 6.
Рисунок 14.6b. Результат хода Макса. Мин отвечает ходом из лунки 6.
 Рисунок 14.6с. Позиция после ответа Мина. Макс отвечает ходом из лунки 2.
Рисунок 14.6с. Позиция после ответа Мина. Макс отвечает ходом из лунки 2.
 Рисунок 14.6d. Позиция после ответа Макса. Это всего лишь одна из примерно б3 подобных цепочек ходов.
Однако может оказаться недостаточным заглядывать вперед на два уровня. Несмотря на то что игра в калах обязательно кончается[18], предсказать, насколько далеко нужно заглянуть вперед, чтобы найти конец, оказывается весьма трудно. Каждый следующий уровень требует примерно в шесть раз больше времени и памяти, чем предыдущий. Надо что-то предпринять, чтобы остановить этот рост.
Этой цели служит статическая оценочная функция, дающая оценку позиции без построения дерева. В калахе мы воспользуемся разницей очков, получаемой как разность числа камней в калахах Макса и Мина. Если слегка изменить правила, потребовав, чтобы в калах победившего игрока сразу же перекладывались все камни, то разница очков всегда будет положительной, когда Макс имеет преимущество, а когда Макс выиграет, разница очков станет максимально возможной. Теперь Макс может выбирать тот из шести ходов, который максимизирует (не зря его зовут Макс) статическую оценочную функцию. Если два хода одинаковы с этой точки зрения, Макс может выбрать любой из них случайным образом.
Ну вот мы и ответили на вопрос о стратегии Макса. Так ли это? Если бы этим исчерпывалась стратегия калаха, то такая игра немногого бы стоила. Ведь Мин может ставить Максу ловушки, и, чтобы их избежать, Максу нужно смотреть вперед. Статическую опенку можно применять к позициям, лежащим глубоко в дереве и не являющимся заведомо выигрышными или проигрышными.
Пусть Макс хочет заглянуть вперед на d уровней. Будем считать, что начальная позиция лежит на уровне 0. Постройте все шесть мыслимых ходов, приводящих нас на уровень 1. Применяя в каждой позиции уровня 1 ходы Мина, получите все позиции уровня 2.
Продолжайте в том же духе, пока не построите все дерево вплоть до уровня d. Иногда может оказаться, что не все шесть ходов возможны, поскольку одна или несколько лунок пусты. Кроме того, некоторая ветвь может окончиться из-за хода, завершающего игру. Заметим, что все ходы на четных уровнях делает Макс, а на нечетных — Мин.
Теперь, чтобы перенести оценку с уровня d на уровень 0, выполните следующие действия на всех уровнях, начиная с уровня d и кончая нулевым. Примените статическую оценочную функцию ко всем листьям на рассматриваемом уровне. Это дает разницу очков в листьях. Для нелистовых узлов постройте оценку разницы очков, найдя максимум оценок по всем непосредственным преемникам данного узла, если он находится на четном уровне, и минимум, если узел — на нечетном уровне. Такой способ действий отвечает стремлению Макса максимизировать разрыв и стремлению Мина минимизировать его (или сделать более отрицательным). После того как пройден весь путь до нулевого уровня и найдена разница очков в исходном узле, выберите любой из шести ходов, позволяющий получить эту разницу очков. Отметим, что, как правило, все листья будут находиться на уровне d. Кроме того, при построении дерева можно всегда проходить каждую ветвь сначала вглубь,т.е. строить дерево в порядке перебора в глубину, а не в порядке перебора в ширину, как описано[19]. На рис. 14.7 показана часть возможного дерева игры. До листьев доведена лишь одна ветвь. Изображены правильные значения, вычисленные исходя из показанной на рисунке информации. Максу следует выбрать ход из лунки 1.
Рисунок 14.6d. Позиция после ответа Макса. Это всего лишь одна из примерно б3 подобных цепочек ходов.
Однако может оказаться недостаточным заглядывать вперед на два уровня. Несмотря на то что игра в калах обязательно кончается[18], предсказать, насколько далеко нужно заглянуть вперед, чтобы найти конец, оказывается весьма трудно. Каждый следующий уровень требует примерно в шесть раз больше времени и памяти, чем предыдущий. Надо что-то предпринять, чтобы остановить этот рост.
Этой цели служит статическая оценочная функция, дающая оценку позиции без построения дерева. В калахе мы воспользуемся разницей очков, получаемой как разность числа камней в калахах Макса и Мина. Если слегка изменить правила, потребовав, чтобы в калах победившего игрока сразу же перекладывались все камни, то разница очков всегда будет положительной, когда Макс имеет преимущество, а когда Макс выиграет, разница очков станет максимально возможной. Теперь Макс может выбирать тот из шести ходов, который максимизирует (не зря его зовут Макс) статическую оценочную функцию. Если два хода одинаковы с этой точки зрения, Макс может выбрать любой из них случайным образом.
Ну вот мы и ответили на вопрос о стратегии Макса. Так ли это? Если бы этим исчерпывалась стратегия калаха, то такая игра немногого бы стоила. Ведь Мин может ставить Максу ловушки, и, чтобы их избежать, Максу нужно смотреть вперед. Статическую опенку можно применять к позициям, лежащим глубоко в дереве и не являющимся заведомо выигрышными или проигрышными.
Пусть Макс хочет заглянуть вперед на d уровней. Будем считать, что начальная позиция лежит на уровне 0. Постройте все шесть мыслимых ходов, приводящих нас на уровень 1. Применяя в каждой позиции уровня 1 ходы Мина, получите все позиции уровня 2.
Продолжайте в том же духе, пока не построите все дерево вплоть до уровня d. Иногда может оказаться, что не все шесть ходов возможны, поскольку одна или несколько лунок пусты. Кроме того, некоторая ветвь может окончиться из-за хода, завершающего игру. Заметим, что все ходы на четных уровнях делает Макс, а на нечетных — Мин.
Теперь, чтобы перенести оценку с уровня d на уровень 0, выполните следующие действия на всех уровнях, начиная с уровня d и кончая нулевым. Примените статическую оценочную функцию ко всем листьям на рассматриваемом уровне. Это дает разницу очков в листьях. Для нелистовых узлов постройте оценку разницы очков, найдя максимум оценок по всем непосредственным преемникам данного узла, если он находится на четном уровне, и минимум, если узел — на нечетном уровне. Такой способ действий отвечает стремлению Макса максимизировать разрыв и стремлению Мина минимизировать его (или сделать более отрицательным). После того как пройден весь путь до нулевого уровня и найдена разница очков в исходном узле, выберите любой из шести ходов, позволяющий получить эту разницу очков. Отметим, что, как правило, все листья будут находиться на уровне d. Кроме того, при построении дерева можно всегда проходить каждую ветвь сначала вглубь,т.е. строить дерево в порядке перебора в глубину, а не в порядке перебора в ширину, как описано[19]. На рис. 14.7 показана часть возможного дерева игры. До листьев доведена лишь одна ветвь. Изображены правильные значения, вычисленные исходя из показанной на рисунке информации. Максу следует выбрать ход из лунки 1.
 Рисунок 14.7. Возможное дерево игры. Полностью показан только один путь до низа дерева. Предполагается, что значения в кружках получены из анализа нижних уровней.
По сути дела, мы сейчас описали минимаксную процедуру для игры двух лиц. Как нетрудно видеть, для анализа на d уровней вперед необходимо построить около
Рисунок 14.7. Возможное дерево игры. Полностью показан только один путь до низа дерева. Предполагается, что значения в кружках получены из анализа нижних уровней.
По сути дела, мы сейчас описали минимаксную процедуру для игры двух лиц. Как нетрудно видеть, для анализа на d уровней вперед необходимо построить около
 позиций. Ввиду очень быстрого роста этой функции желательно иметь какое-либо средство, экономящее усилия. Альфа-бета-процедура при том же объеме работы позволяет иногда провести анализ на вдвое большую глубину.
Идея этой процедуры обобщает рассмотренный пример. Допустим, что в некотором внутреннем узле А дерева ход должен сделать Макс и что он с помощью перебора в глубину уже построил полное дерево В для хода из лунки 1 и дерево С для хода из лунки 2. Предположим далее, что оценка, вычисленная при анализе дерева, равна 1 для узла В и 2 — для С. Тогда можно приписать узлу А предварительную оценку (ПО), равную 2. Что бы ни случилось, Макс может отвергнуть любой ход из А с оценкой меньше 2. Допустим теперь, что Макс начинает строить дерево для хода из лунки 3 в узел D. В узле D ход Мина. Как только D получит ПО, равную или меньшую 2, дальнейшее построение дерева ниже D окажется уже ненужным. Действительно, Мин заведомо не выберет ход с оценкой больше 2, если доступно значение 2 или меньше. Но тогда узел D не будет интересовать Макса, коль скоро он уже имеет возможность получить 2. Итак, можно прекратить раскрытие узла D. Обсуждавшееся дерево показано на рис. 14.8.
позиций. Ввиду очень быстрого роста этой функции желательно иметь какое-либо средство, экономящее усилия. Альфа-бета-процедура при том же объеме работы позволяет иногда провести анализ на вдвое большую глубину.
Идея этой процедуры обобщает рассмотренный пример. Допустим, что в некотором внутреннем узле А дерева ход должен сделать Макс и что он с помощью перебора в глубину уже построил полное дерево В для хода из лунки 1 и дерево С для хода из лунки 2. Предположим далее, что оценка, вычисленная при анализе дерева, равна 1 для узла В и 2 — для С. Тогда можно приписать узлу А предварительную оценку (ПО), равную 2. Что бы ни случилось, Макс может отвергнуть любой ход из А с оценкой меньше 2. Допустим теперь, что Макс начинает строить дерево для хода из лунки 3 в узел D. В узле D ход Мина. Как только D получит ПО, равную или меньшую 2, дальнейшее построение дерева ниже D окажется уже ненужным. Действительно, Мин заведомо не выберет ход с оценкой больше 2, если доступно значение 2 или меньше. Но тогда узел D не будет интересовать Макса, коль скоро он уже имеет возможность получить 2. Итак, можно прекратить раскрытие узла D. Обсуждавшееся дерево показано на рис. 14.8.
 Рисунок 14.8. Часть дерева для альфа-бета-процедуры, описанного в тексте. Как только ПО в узле D опустится ниже 3, можно прекращать раскрытие узла D и его преемников.
Рисунок 14.8. Часть дерева для альфа-бета-процедуры, описанного в тексте. Как только ПО в узле D опустится ниже 3, можно прекращать раскрытие узла D и его преемников.
Альфа-бета-процедура
Для выполнения альфа-бета-процедуры поиска минимакса начните с перебора дерева игры в глубину. Каждому узлу приписывается предварительная оценка (ПО) и окончательная оценка (ОО). Для листьев как ПО, так и ОО равна статической оценке. ПО во внутренних узлах Макса равна максимуму из ОО преемников этого узла, в узлах Мина — минимуму. Всякий раз, когда ПО меняется, мы проверяем, не следует ли прекратить раскрытие этого узла. (Первоначально ПО равна −∞ во внутренних узлах Макса и +∞ во внутренних узлах Мина). В узле Макса происходит отсечение всякий раз, как только ПО этого узла становится не меньше ПО какого-либо предшественника этого узла, принадлежащего Мину[20]. Аналогично в узле Мина отсечение происходит, когда его ПО становится не больше ПО какого-либо из предшественников, принадлежащего Максу. При отсечении узла его ПО становится его ОО. Вам следует убедиться, что альфа-бета-процедура всегда выбирает тот же ход, что и обычная минимаксная процедура. Тема. Напишите программу для игры в калах, использующую альфа-бета-процедуру. Ваша программа должна уметь играть как против человека за терминалом, так и против самой себя. Следует предусмотреть возможность изменения глубины d просмотра, числа к камней в каждой лунке, а также замены игрока, делающего первый ход. Вывод позиций и ввод ходов следует представить в наиболее удобной форме. По требованию программа должна выдавать на печать дерево ходов. Чтобы с программой было интересно играть, она должна случайным образом выбирать ход из нескольких равноправных (как обычно, эту возможность следует отключать на время отладки). Указания исполнителю. Несмотря на многословное описание, сама программа для игры в калах довольно проста. Основную трудность составляет построение структуры данных для представления игровых деревьев и обеспечение должного порядка создания и уничтожения этих деревьев. Вам, вероятно, придется написать свои собственные программы, которые будут выделять пространство для деревьев и собирать освобождающуюся память. Требование эффективности по времени работы накладывает ограничение на глубину просмотра; учитывайте это в программах порождения дерева. Вероятно, имеет смысл обеспечить относительную независимость минимаксной процедуры от остальной части программы, с тем чтобы изменения минимаксной процедуры не влияли на всю программу. Инструментовка. Здесь мы еще раз встречаемся с задачей, для решения которой требуются, по-видимому, противоречивые свойства языка: мощные структуры данных, удобные управляющие структуры и эффективность выполнения. В этом смысле наиболее удачным языком представляется Паскаль, в особенности если избегать широкого использования его возможностей по выделению и освобождению памяти для данных. Для реализации поиска по дереву сами собой напрашиваются рекурсивные процедуры, но они дороги. Попробуйте применить вместо них средства языка, позволяющие преобразовать рекурсию в итеративный обход структур данных. Длительность исполнения. Одному исполнителю на 4 недели. Развитие темы. Хотя в литературе, указанной в библиографии, содержится большое число модификаций альфа-бета-процедуры, мы обсудим здесь только две из них. В первой делается попытка повысить эффективность отсечения. Работа альфа-бета-процедуры основана на том, что хорошие ходы (за обоих игроков) прекращают анализ худших ходов. Поэтому, чем раньше мы будем находить хорошие ходы, тем чаще будут отсекаться плохие. Итак, следует попытаться в первую очередь раскрывать хорошие ходы. В методе с фиксированным упорядочением непосредственные преемники узла упорядочиваются с помощью статической оценочной функций до их анализа. Первым раскрывается узел с наилучшей оценкой. Статическая оценочная функция, как мы надеемся, хорошо предсказывает окончательный результат, получаемый с помощью просмотра, следовательно, эта процедура повышает вероятность того, что сначала будут рассматриваться хорошие ходы. В узлах Мина в первую очередь следует рассматривать преемники с минимальной оценкой. Еще одно обобщение состоит в изменении статической оценочной функции. Часто используют оценку, равную разности числа всех камней на стороне Макса (в калахе и лунках) и числа камней на стороне Мина. Можно применить любую простую линейную функцию от 14 значений для всех лунок. Наилучшую такую функцию можно выбрать при помощи турнира {это было рассмотрено в гл. 5). Не забывайте, однако, что главным фактором, определяющим силу игрока, является, до всей видимости, глубина просмотра.Литература
Алеф0 (Aleph0). Computer Recreations. Software — Practice and Experience, 1, pp. 297–300, 1971. В этой статье описывается с внешней стороны программа игры в калах и дается некоторый исторический обзор подобных программ. Имеется полезная библиография. Белл (Bell R, С). Board and Table Games from Many Civilizations. Oxford University Press, London, 1969. В гл. 4 Белл описывает несколько вариантов игры манкала. Книга представляет интерес для широкого круга читателей благодаря обширным сведениям об играх и об истории культуры. Нильсон (Nilsson N. J.). Problem-Solving Methods in Artificial Intelligence. McGraw-Hill, New York, NY, 1971. [Имеется перевод: Нильсон H. Искусственный интеллект. Методы поиска решений. — М.: Мир, 1973.] Книга Нильсона, вероятно, наилучшее введение в эту дисциплину. В гл. 6 очень понятно разобраны минимаксные методы. Даются ценные рекомендации по дальнейшему чтению. Слэйгл (Slagle J.R.). Artificial Intelligence: The Heuristic Programming Approach. McGraw-Hill, New York, NY, 1971. [Имеется перевод: Слэйгл Дж. Искусственный интеллект. Подход на основе эвристического программирования. — М.: Мир, 1973.] Слэйгл также дает хороший обзор области искусственного интеллекта. Он экспериментировал с калахом, и поэтому в книге приводится ряд подробностей об этой игре. * «Наука и жизнь», № 12, 1971. Описывается программа игры в калах, разработанная в ВЦ Ленинградского университета. Правила игры, используемые этой программой, сильно отличаются от описанных в настоящей книге.15. Проще простого, или Поиск узоров из простых чисел
Всякий, кто изучает простые числа, бывает очарован ими и одновременно ощущает собственное бессилие. Определение простых чисел так просто и очевидно; найти очередное простое число так легко; разложение на простые сомножители — такое естественное действие. Почему же тогда простые числа столь упорно сопротивляются нашим попыткам постичь порядок и закономерности их расположения? Может быть, в них вообще нет порядка, или же мы так слепы, что не видим его? Какой-то порядок в простых числах, несомненно, есть. Простые числа можно отсеять от составных решетом Эратосфена. Начнем с того, что 2 — простое число. Теперь выбросим все большие четные числа (делящиеся на 2). Первое из уцелевших за двойкой чисел, 3, также должно быть простым. Удалим все его кратные; останется 5. После удаления кратных пяти останется 7. Будем продолжать в том же духе; все числа, прошедшие через решето, будут простыми. Эта регулярная, хотя и медленная процедура находит все простые числа. Мы знаем, кроме того, что при n, стремящемся к бесконечности, отношение количества простых чисел к составным среди первых целых чисел приближается к ln n/n[21]. К сожалению, этот предел чисто статистический и не помогает при нахождении простых чисел. Оказывается, что все известные методы построения таблицы простых чисел — не что иное, как вариации унылого метода решета. Эйлер придумал формулу x2 + x + 41; для всех x от нуля до 39 эта формула дает простые числа. Однако никакая полиномиальная формула не может давать подряд бесконечный ряд простых чисел, и функция Эйлера терпит фиаско при х = 40. Другие известные функции дают длинные ряды простых чисел, но ни одна не дает сплошь простые. Исследователи проанализировали множество целочисленных функций, однако до сих пор не удалось увидеть закономерность. Рисунок 15.1. Числа расположены по спирали против часовой стрелки.
Закономерности проявляются, когда целые числа отображаются на плоскость (или в пространство). Одно из возможных отображений показано на рис. 15.1, где числа располагаются вокруг начальной точки по спирали против часовой стрелки. На рис. 15.2 целые числа заполняют треугольник положительного квадранта. Если достаточно далеко расширить рамки этих рисунков, то станет видно, что простые числа располагаются преимущественно вдоль отдельных прямых (в основном по диагоналям) и совершенно игнорируют другие прямые. Частично этот эффект легко объясним. В обоих расположениях целые числа, попадающие на любую диагональ, даются некоторым квадратичным многочленом. Если многочлен, соответствующий какой-либо прямой, разлагается на рациональные линейные множители, то эта прямая будет содержать одни составные числа. Таким образом, простым числам волей-неволей пришлось облюбовать неприводимые прямые. Однако некоторые неприводимые многочлены изобилуют простыми числами, и изобилие это не оскудевает, несмотря на то что плотность простых чисел среди всех целых медленно стремится к нулю. Иными словами, хотя разложение многочленов объясняет в некоторой степени скученность простых чисел, все же существуют многочлены, более богатые простыми числами, чем предсказывает обычный статистический анализ.
Рисунок 15.1. Числа расположены по спирали против часовой стрелки.
Закономерности проявляются, когда целые числа отображаются на плоскость (или в пространство). Одно из возможных отображений показано на рис. 15.1, где числа располагаются вокруг начальной точки по спирали против часовой стрелки. На рис. 15.2 целые числа заполняют треугольник положительного квадранта. Если достаточно далеко расширить рамки этих рисунков, то станет видно, что простые числа располагаются преимущественно вдоль отдельных прямых (в основном по диагоналям) и совершенно игнорируют другие прямые. Частично этот эффект легко объясним. В обоих расположениях целые числа, попадающие на любую диагональ, даются некоторым квадратичным многочленом. Если многочлен, соответствующий какой-либо прямой, разлагается на рациональные линейные множители, то эта прямая будет содержать одни составные числа. Таким образом, простым числам волей-неволей пришлось облюбовать неприводимые прямые. Однако некоторые неприводимые многочлены изобилуют простыми числами, и изобилие это не оскудевает, несмотря на то что плотность простых чисел среди всех целых медленно стремится к нулю. Иными словами, хотя разложение многочленов объясняет в некоторой степени скученность простых чисел, все же существуют многочлены, более богатые простыми числами, чем предсказывает обычный статистический анализ.
 Рисунок 15.2. Числа в треугольнике.
Тема. Напишите программу, которая отображает целые числа на плоскость некоторым регулярным образом и отмечает на рисунке места, где находятся простые числа. Выведите формулы, описывающие прямые линии на вашем рисунке, и напечатайте те из них, которые особенно изобилуют простыми числами; печатайте также долю простых чисел на этих прямых. Обеспечьте высокую эффективность ваших программ проверки целых чисел на простоту, так чтобы вам хватило времени для анализа весьма отдаленных отрезков натурального ряда.
Инструментовка. Для решения этой задачи больше всего подходит алгебраический язык. У вас должна быть возможность управлять эффективностью проверки на простоту.
Длительность исполнения. Одному исполнителю на 2 недели.
Рисунок 15.2. Числа в треугольнике.
Тема. Напишите программу, которая отображает целые числа на плоскость некоторым регулярным образом и отмечает на рисунке места, где находятся простые числа. Выведите формулы, описывающие прямые линии на вашем рисунке, и напечатайте те из них, которые особенно изобилуют простыми числами; печатайте также долю простых чисел на этих прямых. Обеспечьте высокую эффективность ваших программ проверки целых чисел на простоту, так чтобы вам хватило времени для анализа весьма отдаленных отрезков натурального ряда.
Инструментовка. Для решения этой задачи больше всего подходит алгебраический язык. У вас должна быть возможность управлять эффективностью проверки на простоту.
Длительность исполнения. Одному исполнителю на 2 недели.
Литература
Гарднер (Gardner M). Mathematical Games. Scientific American, pp. 120-126, March 1964. [Имеется перевод: Гарднер М. Математические досуги. — М.: Мир, 1972, с. 410.] Гаусс (Gauss С. F.). Disquisitiones Arithmeticae. Yale University Press, New Haven, CT, 1965. По теории чисел написаны сотни книг. Но, как это ни странно, одна из первых книг по-прежнему остается одной из лучших. Помимо прочих достоинств она вышла в дешевом издании. Так почему бы не посоветоваться с классиком? Штейн, Улам, Уэллс (Stein M. L, Ulam S. M., Wells M. В.). A Visual Display of Some Properties of the Distribution of Primes, American Mathematical Monthly, pp. 516–520, May 1964. Гарднер излагает результаты Штейна, Улама и Уэллса более популярно, тем не менее обе работы легки для чтения. На эту тему почти ничего больше не написано, так что это, вероятно, увлечение Улама. Идея получать с помощью простых чисел красивые картинки позволяет убить лишнее машинное время, и, не исключено, что в этом все же что-то есть.16. Горючие слезы, или Учет расхода бензина
Тридцать центов за галлон — дело прошлое. Сорок центов за галлон — дело прошлое. Пятьдесят центов за галлон — дело прошлое. Сейчас[22] галлон бензина стоит шестьдесят центов, и, возможно, вскоре мы останемся вообще без горючего. Так что на повестке дня — анализ индивидуального расходования бензина. Многие ведут журнал покупок бензина. Обычно туда записывают дату, показания счетчика пройденного пути, марку бензина, цену одного галлона, сколько галлонов куплено и общую стоимость. Три последние величины зависят друг от друга; эта зависимость не совсем точная из-за ошибок округления, но ее все же можно использовать для проверки правильности исходных данных. С помощью ЭВМ вы можете получить разнообразную статистическую информацию. Интересно вычислить такие производные величины, как средняя стоимость одного галлона, средний пробег на галлон, средний пробег за день, средняя стоимость пробега в одну милю, среднее время расходования одного галлона. Кроме того, хорошо было бы получить такую же информацию по каждой марке бензина и посмотреть, есть ли разница между марками. Таблица 16.1 — фрагмент реального журнала покупок бензина[23].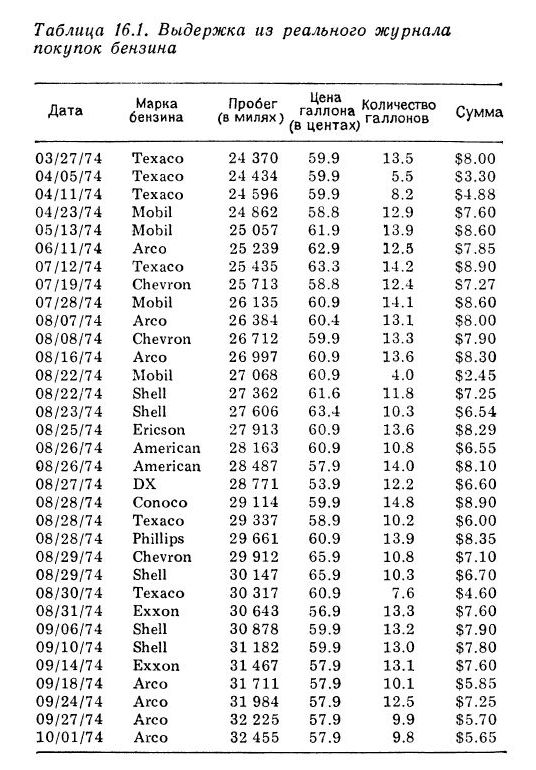 Будем считать в данной задаче, что каждой новой записи в журнале соответствует новая полная заправка автомобиля. Первая запись в журнале устанавливает точки отсчета дат и пройденного пути; никак иначе она не используется. Следующие записи фиксируют пробег и расходы на очередную заправку, показывая объем сожженного горючего и количество пройденных миль после предыдущей заправки. Было бы также любопытно печатать текущие средние значения за самое последнее время, чтобы заметить краткосрочные изменения.
Тема. По данным, имеющимся в журнале покупок бензина, напечатайте разнообразную контрольную статистику, показывающую водителю, во что обходится эксплуатация автомобиля. Исходные данные о каждой покупке — это дата, марка бензина, показание счетчика пройденного пути, цена одного галлона, сколько галлонов куплено и общая стоимость. Выводимая информация должна повторять исходную и, кроме того, включать в себя такие показатели, как пробег между заправками, пробег на один галлон, стоимость пробега в одну милю, стоимость одного галлона, стоимость одного дня, время расходования одного галлона. Все указанные показатели следует получать для каждой заправки и усреднять двумя способами: за небольшой срок и за все время наблюдений. Кроме того, соберите данные по каждой марке бензина и напечатайте соответствующие средние значения. Не ограничивайте число различных марок.
Указания исполнителю. Предлагаемая программа не особенно трудна. Для печати долларовых величин, как и в некоторых других задачах, нужна некоторая изобретательность. Требование неограниченности числа марок означает, что их нельзя задать заранее, поэтому нужна простая расширяемая таблица марок и связанной с ними информации.
Инструментовка. И снова очевидный кандидат — Кобол, созданный как раз для решения подобных задач. Если вам удастся найти достаточно мощный язык для генерации отчетов, уместно научиться им пользоваться. Можно использовать и любой процедурный алгебраический язык.
Длительность исполнения. Одному исполнителю на 1 неделю.
Будем считать в данной задаче, что каждой новой записи в журнале соответствует новая полная заправка автомобиля. Первая запись в журнале устанавливает точки отсчета дат и пройденного пути; никак иначе она не используется. Следующие записи фиксируют пробег и расходы на очередную заправку, показывая объем сожженного горючего и количество пройденных миль после предыдущей заправки. Было бы также любопытно печатать текущие средние значения за самое последнее время, чтобы заметить краткосрочные изменения.
Тема. По данным, имеющимся в журнале покупок бензина, напечатайте разнообразную контрольную статистику, показывающую водителю, во что обходится эксплуатация автомобиля. Исходные данные о каждой покупке — это дата, марка бензина, показание счетчика пройденного пути, цена одного галлона, сколько галлонов куплено и общая стоимость. Выводимая информация должна повторять исходную и, кроме того, включать в себя такие показатели, как пробег между заправками, пробег на один галлон, стоимость пробега в одну милю, стоимость одного галлона, стоимость одного дня, время расходования одного галлона. Все указанные показатели следует получать для каждой заправки и усреднять двумя способами: за небольшой срок и за все время наблюдений. Кроме того, соберите данные по каждой марке бензина и напечатайте соответствующие средние значения. Не ограничивайте число различных марок.
Указания исполнителю. Предлагаемая программа не особенно трудна. Для печати долларовых величин, как и в некоторых других задачах, нужна некоторая изобретательность. Требование неограниченности числа марок означает, что их нельзя задать заранее, поэтому нужна простая расширяемая таблица марок и связанной с ними информации.
Инструментовка. И снова очевидный кандидат — Кобол, созданный как раз для решения подобных задач. Если вам удастся найти достаточно мощный язык для генерации отчетов, уместно научиться им пользоваться. Можно использовать и любой процедурный алгебраический язык.
Длительность исполнения. Одному исполнителю на 1 неделю.
17. Тише едешь — дальше будешь, или Моделирование движения на автостраде
Энергетический кризис уже в своем начале привел к снижению допустимой скорости движения на автодорогах в масштабах всей страны. Большинство автомобилистов в длительных поездках не устают проклинать это ограничение. Разумеется, теперь мы знаем, что снижение скорости ежегодно сберегает тысячи жизней и миллионы долларов. Но мало кто из водителей понимает, что в условиях перегруженности автострад вблизи больших городов снижение скорости на самом деле ведет к экономии времени. Более точно парадокс формулируется так: если все тише едут, они скорее приедут. Вспомните, как вы однажды «с ветерком» катили по шоссе, миль на 5 превышая допустимую скорость, хотя машин было много. Внезапно все стали еле ползти, и вам тоже пришлось нажать на тормоза. Затем последовала четверть, половина, а то и целая миля конвульсивного чередования остановок и движения. Наконец затор остался позади, и вы смогли вновьприбавить скорость. Но все это происходило без всякой видимой причины! Что же нарушило плавность движения? Для объяснения причины задержки необходимо привлечь гидродинамику. Движущиеся по шоссе автомобили ведут себя во многом аналогично частицам протекающей в трубе жидкости. Если плотность и скорость частиц достаточно велики, любая кратковременная задержка потока приведет к возникновению ударной волны. Ударная волна — это область очень высокой плотности; автомобили (или частицы) резко замедляются, попадая в эту область, и затем ускоряются, когда, преодолев довольно четко очерченный ударный фронт, оказываются в области с гораздо более низкой плотностью. Ударная волна продолжает существовать длительное время, медленно двигаясь навстречу потоку и медленно рассеиваясь. Отметим, что рассеяние объясняется уменьшением плотности в ударной области и может быть ускорено, если водители заранее слегка притормозят, увидев впереди затор. Было бы любопытно провести эксперимент на автостраде в часы пик, но, несомненно, пришлось бы привлечь не одну сотню машин. Не лучше ли обойтись одной вычислительной машиной? Рассмотрим прямой однорядный участок автострады длиной 5 миль, без перекрестков. Автомобили появляются на одном конце дороги, проезжают по ней и бесследно исчезают на другом конце. Машины стремятся двигаться по дороге с постоянными скоростями (возможно, разными для разных машин). Чтобы изучать ударные волны, будем вводить в эту транспортную благодать случайные замедления. Для проведения эксперимента нужны генератор автомобилей и генератор возмущений. В начале каждого эксперимента автострада пуста. Запустите генератор автомобилей, который поместит машину на дорогу, придаст ей скорость и выберет интервал до порождения следующего автомобиля. Начальные скорости автомобилен подчиняются равномерному случайному распределению на отрезке от 50 до 60 миль в час, а интервалы между порождениями также равномерно распределены на отрезке от 4 до 6 с. Минимальное допустимое сближение составляет одну длину автомобиля (10 футов) на каждые 10 миль в час скорости передней машины. Когда автомобиль приближается к идущей впереди машине на утроенное допустимое расстояние, он начинает притормаживать, пока скорости не сравняются, теряя по одной миле в час за секунду. Если передний автомобиль начинает резко замедляться, идущий сзади выжидает 0,2 с и затем тормозит, снижая каждую секунду свою скорость на 15 миль в час. В результате может произойти авария, которой и закончится эксперимент. Собственно эксперимент состоит в заполнении дороги машинами, введении искусственного замедления и наблюдении результата. Начните запускать машины на пустую дорогу; продолжайте делать это, пока не пройдет 2 минуты (модельного времени) с момента прохождения заданного участка дороги первым автомобилем. Затем, не прекращая запускать машины, выберите автомобиль, который раньше всех пересечет отметку в 4 мили, сбросьте с его скорости как можно резче 0, 10, 20, 30, 40 или 50 миль в час, удержите на новой скорости 100 ярдов, после чего придайте ему ускорение 5 миль в час за секунду, пока автомобиль не наберет свою первоначальную скорость (машины всегда стремятся сохранить первоначальную скорость). Продолжайте эксперимент еще 5 минут после того, как виновник затора начал замедляться, и подсчитайте количество машин, прошедших участок дороги за это время. Полученная величина и есть наблюдаемый результат эксперимента. Машины, следующие за виновником, также могут ускоряться на 5 миль в час за секунду, если дорога перед ними освобождается. Проведите эксперимент несколько раз для каждого значения замедления. Если произойдет авария, все машины, находящиеся позади, автоматически остановятся и не смогут пройти заданный участок дороги. В аварию может попасть не сам виновник, а машины, идущие сзади. Тема. Напишите программу, позволяющую провести эксперимент с ударной волной на автостраде. Все исходные данные представлены одним числом — сколько раз повторять эксперимент для каждого уменьшения скорости. Обязательная часть выводимой информации — среднее количество машин, прошедших участок дороги после каждого искусственного замедления. Но для отладки и лучшего понимания физического поведения системы полезно вывести дополнительную информацию. В частности, несколько «моментальных снимков» дороги, вероятно, позволят почувствовать ситуацию лучше, чем любое количество статистики. Если в вашем распоряжении имеется хорошее графическое устройство — интерактивное или микрофильмовое — то серия моментальных снимков составит фильм о дороге. Указания исполнителю. Наиболее трудным в предлагаемой задаче является отслеживание всех автомобилей на дороге[24]. Можно организовать цикл и примерно через одну сотую — одну десятую секунды модельного времени должным образом подправлять положение каждого автомобиля. Если интервал достаточно мал, заметного накопления ошибок не произойдет, а выглядеть программа будет красиво — как семейство вложенных циклов. Однако при использовании метода пошаговой фиксации цикл может выполняться слишком большое число раз. В нашем случае эксперимент продлится примерно 12 минут модельного времени, в каждый момент на дороге будет около 90 машин, и, даже если выбрать большой интервал в одну десятую секунды, потребуется примерно 1200 циклов, или около 650 000 операций с отдельными автомобилями. Если программа тратит много времени на продвижение одного автомобиля, эксперимент слишком затянется. Положение можно подправить, варьируя интервал в зависимости от дорожной обстановки. Другой подход состоит в том, чтобы подправлять положение автомобилей только в моменты критических событий. При таком подходе заводится список всех событий, ожидаемых в недалеком будущем; например, запускается или исчезает автомобиль, одна машина догоняет другую, прошло две минуты с момента исчезновения первого автомобиля, пора вновь ускорять автомобиль-виновник. Головным элементом списка событий всегда должно быть ближайшее событие; список в целом не обязан быть упорядоченным — его можно представить и как очередь с приоритетами, и как кучу. В основном цикле от списка отделяется головной элемент, описывающий очередное событие, все автомобили устанавливаются в позиции, соответствующие новому времени, запоминаются все события, которые следует планировать, эти события вставляются в список и список переупорядочивается, чтобы ближайшее событие оказалось в голове. Достоинство моделирования методом критических событий в том, что порой довольно долго, 4–5 секунд, ничего не происходит. Сэкономленное время можно употребить на более сложную обработку списка событий. Инструментовка. Для решения этой задачи естественно воспользоваться языками моделирования, такими, как Симскрипт или Симула. Если они недоступны, подойдет любой процедурный язык. Независимо от метода моделирования существенным подспорьем будут хорошие структуры данных для представления информации об автомобилях и для реализации очереди событий. Длительность исполнения. Одному исполнителю на 3 недели; еще неделя на изготовление фильма. Развитие темы. Строго говоря, в предложенной задаче не изучается ситуация, описанная в нескольких первых абзацах. Вместо выяснения того, что происходит с ударной волной при различных средних скоростях движения на автостраде, в эксперименте рассматривались удары различной силы. Проделайте все еще раз, взяв диапазон начальных скоростей от 40 до 50 или от 60 до 70 миль в час. Попробуйте для некоторых переменных нормальное распределение вместо равномерного. Поварьируйте законы торможения и ускорения. Иными словами, изучите влияние всех параметров, а не только одного, выбранного нами.Литература
Герман, Гардел (Herman R., Gardels К). Vehicular Traffic Flow. Scientific American, pp. 35–43, December 1963. Авторы описывают проведение нескольких физических экспериментов над движением транспорта и развитие математической теории. Конечно, использовавшийся ими Голландский туннель в Нью-Йорке для большинства из нас недоступен Если вам интересно проследить за работами по этой тематике после 1963 г., научитесь пользоваться Science Citation Index или другими библиографическими средствами, помогающими довести старую информацию до наших дней.18. Читаем, пишем, считаем, или Конструирование интерпретатора форматов
Вам, вероятно, пришлось написать по крайней мере одну программу, которая исторгала из машины бумажный поток, несущий искусно оформленные данные. Строка за строкой сомкнутыми рядами выступали из печатающего устройства целые батальоны чисел под предводительством четких заголовков. Интересовали вас только лишь два или три числа, но не напечатать всего было как-то неловко — ведь это так просто! А вдруг кому-то и в самом деле захочется узнать точную сумму налога для служащего 1793 на рабочем месте 907, выплаченную им в сентябре пять лет назад. Выдать на печать такую уйму информации и не свалиться при этом от изнеможения вам удалось благодаря существованию таких вещей, как фортранные инструкции формата, которые помогли преобразовать эти неудобоваримые двоичные числа в радующие глаз цепочки из цифр, букв и знаков. По существу, то же самое происходит и при вводе. Вводные данные аккуратно пробиваются на перфокартах, и вы даже не задумываетесь о том, каким преобразованиям должны они подвергнуться для того, чтобы центральный процессор мог проделывать над ними свои несложные арифметические фокусы. А пожалуй, о вводе и выводе стоит поразмышлять чуть серьезнее. Программа, обрабатывающая большое количество данных, вполне может тратить от четверти до половины своего счетного времени на служебные подпрограммы ввода и вывода, а большая часть этого времени в свою очередь может уходить на интерпретирование форматов и преобразование данных. Вероятно, вы уже не будете так легкомысленно относиться к преобразованиям данных при вводе и выводе, если попытаетесь решить предлагаемую задачу, превратившись на время в системного программиста. Для изучения были выбраны форматы языка Фортран, поскольку они просты, эффективны и были, в сущности, праотцами большинства других схем форматов. Всякий раз, когда в операции ввода/вывода участвует устройство, предназначенное для взаимодействия машины с человеком, связующим звеном между ними оказывается инструкция формата. Основные элементы, участвующие в операции ввода/вывода, — это список переменных, формат и файл. Элементы данных пересылаются из файла в переменные списка или в обратном направлении, в зависимости от того, какая операция — ввода или вывода — выполняется. При пересылке каждого элемента интерпретируется некоторая часть формата, достаточная для того, чтобы определить текстовое представление этого элемента в файле. Формат определяет лишь характер пересылки того или иного элемента данных, но объем перемещаемых данных от него не зависит.Что такое формат?
Формат — это цепочка литер, описывающая преобразования данных, которые нужно выполнить. Поскольку формат всякий раз при использовании интерпретируется, то его можно рассматривать как маленькую программу. Формат общего вида имеет структуру (yf1s1f2s2…fnsnz), где n может быть нулем, у и z — последовательности наклонных черточек, возможно пустые, fi — либо одиночный код формата, либо формат общего вида, перед которым может стоять натуральное число[25], si — разделитель, т. е. последовательность из запятых и наклонных черточек, которая в некоторых случаях может быть пустой. Пробелы в формате игнорируются везде, кроме одного случая, специально оговоренного ниже, а числа записываются в виде цепочек из десятичных цифр. Предположим, произошло обращение к операции ввода/вывода. Указатель текущей позиции в файле устанавливается на начало следующей записи[26]. Курсор в формате устанавливается на начальную открывающую скобку и движется вправо либо до первого кода, которому должна соответствовать переменная в списке переменных, либо до правого края формата. Такой процесс позволяет при помощи инструкции вывода напечатать строку данных, не пересылая никаких данных из переменных. Интерпретатор форматов будет иметь некоторую внутреннюю память (организованную, как правило, в виде стека), которая будет освобождаться и на которую мы будем время от времени ссылаться, говоря, что интерпретатор что-либо «запомнил». Основной цикл просмотра формата прост. Интерпретатор получает очередную переменную из списка переменных. Курсор начинает двигаться вправо по формату в поисках такого кода, который соответствует передаче элемента данных из переменной в файл или обратно. При движении курсора вправо могут встречаться такие коды, которые влияют на содержимое файла или устанавливают новые значения параметров, управляющих работой интерпретатора. Действия, предписываемые этими кодами, выполняются непосредственно в процессе сканирования. Перед некоторыми кодами допускаются коэффициенты повторения — такой код используется соответствующее число раз. То есть один и тот же код может использоваться с несколькими переменными списка, значит, интерпретатор должен помнить убывающее от цикла к циклу значение счетчика повторений кода. Если курсор дошел до крайней правой закрывающей скобки, то он возвращается к последней открывающей скобке первого уровня без коэффициента повторения, а если таковая отсутствует, то к начальной открывающей скобке формата. Вот три типичные ошибки, которые могут встречаться при форматном вводе/выводе: при вводе встретился конец файла; интерпретатор дважды подряд вышел на правую закрывающую скобку формата, не переслав при этом ни одного элемента данных; нет соответствия между типом кода формата, типом переменной в списке ввода/вывода и типом элемента данных, фактически находящегося в файле (последнее относится только к вводу). При завершении операции вывода последняя частично сформированная запись пишется в файл. Теперь о самих кодах формата. Пожалуй, единственная полезная классификация, которую здесь можно провести, — это различение кодов самозавершающихся и несамозавершающихся, которые требуют после себя запятую, наклонную черту или скобку. Интерпретатор всегда помнит текущее значение масштабирующего множителя, которое вначале устанавливается равным нулю и может быть изменено при помощи спецификации масштабирующего множителя. Перечислим коды формата: r( Открывающая скобка, возможно с коэффициентом повторения, обозначает начало групповой спецификации формата, которая заканчивается соответствующей закрывающей скобкой (число открывающих и закрывающих скобок в формате должно быть одинаковым). Вся групповая спецификация будет повторена столько раз, сколько указывает коэффициент повторения. Если коэффициент отсутствует, то считается, что он равен единице. , Запятая служит признаком конца для таких кодов, которые должны обязательно отделяться от последующих кодов. Никаких других функций запятая не выполняет, допускаются избыточные запятые. / Наклонная черта служит признаком конца для несамозавершающихся кодов, а также означает конец обработки текущей записи файла и переход к следующей записи. Если последним обработанным кодом формата была наклонная черта, то при завершении операции ввода/вывода перехода к следующей записи уже не происходит. Несколько подряд стоящих наклонных черточек Приводят к пропуску нескольких записей при вводе и к созданию пустых записей при выводе. nX При вводе пропускается n литер файла, при выводе в файл записывается n пробелов. Код самозавершающийся, передачи данных не происходит. nHh1···hn При вводе очередные n литер файла помещаются на место литер h1···hn формата. При выводе n литер h1···hn записываются в файл. Любая из литер hi может быть пробелом, это единственный случай, когда пробел является значащей литерой в формате. Код самозавершающийся. Обмена данными между файлом и переменными не происходит. rAw Пусть g — число литер, помещающихся в переменной, которая участвует в данном цикле интерпретации формата. Если при вводе w ≥ g, то крайние правые g из очередных w литер файла передаются в переменную, иначе в переменную попадут очередные w литер файла, дополненные справа g − w пробелами. Если при выводе w ≥ g, то в файл выводятся w — g пробелов и затем g литер переменной, в противном случае в файл попадут w крайних левых литер переменной. Коэффициент повторения r необязателен, код несамозавершающийся. rLw При вводе очередное поле из w литер файла должно представлять собой последовательность пробелов, за которой следует одна из букв Т или F, а далее произвольная последовательность литер, что воспринимается соответственно как значение истина или ложь. При выводе в файл помещаются w − 1 пробелов и одна из букв Т или F. Коэффициент повторения r может отсутствовать; код несамозавершающийся. rIw При вводе цепочка литер, состоящая из нескольких старших пробелов, знака, который может и отсутствовать, и последовательности цифр и пробелов, преобразуется в машинное представление целого числа. Поле ввода состоит из w литер; пробелы после знака воспринимаются как нули. При выводе формируется поле длины w литер, состоящее из нескольких пробелов, знака минус, если он нужен, и прижатой к правому краю цепочки цифр, представляющей данное целое число. Коэффициент повторения r может отсутствовать, код несамозавершающийся. sPrFw.d При вводе число с плавающей точкой читается из поля длины w литер. Если поле ввода состоит только из цифр и пробелов или если левее (w − d + 1) -й литеры (начиная счет с 1) встретился только знак, то мы получим вводимое вещественное значение лишь после того, как будет вставлена десятичная точка между (w − d)-й и (w − d + 1)-й позициями поля ввода. Если вводимая цепочка литер содержит точку, то подразумеваемая позиция точки игнорируется. Если вводимая цепочка литер имеет вид вещественного или целого числа, за которым следует либо еще одно целое число со знаком, либо буква «Е» и целое число со знаком или без него, то это второе число воспринимается как порядок и значение вещественного числа умножается на десять в степени, равной порядку числа. Если присутствует только порядок числа с буквой «Е» вначале, то считается, что перед ним стоит вещественное число, равное единице Если показательная часть числа отсутствует, то прочитанное вещественное число, прежде чем оно будет присвоено переменной из списка ввода, умножается на степень десяти с показателем, равным текущему значению масштабирующего множителя. При выводе число с плавающей точкой записывается в виде x1···xn.y1···yd. Число округлено до d знаков после точки, и, если это необходимо, снабжается знаком минус. В поле вывода обязательно присутствует точка, так что при выводе по коду F всегда выполняется неравенство w ≥ d+1. И в этом случае тоже выводимое значение прижимается к правому краю поля вывода. Спецификация масштабирующего множителя sP, как и коэффициент повторения r, не обязательна. Новое значение s (s — любое целое число со знаком) действует до тех пор, пока не встретится еще одна спецификация масштабирующего множителя. Код F несамозавершающийся. sPrEw.d Ввод осуществляется так же, как для кола F. Основная форма поля вывода имеет вид 0.y1···ydEz1···zm где перед первым нулем и после буквы Е может стоять знак минус, если он нужен, а значение m достаточно для размещения максимального порядка, даже если для данного числа это не нужно. Если текущее значение масштабирующего множителя равно q, то вещественная часть основной формы умножается на 10q, а порядок уменьшается ка q единиц. При q > 0 будет q цифр слева от точки и max(d − q + 1, 0) цифр справа от нее: при q ≤ 0 слева от точки будет стоять нуль, а справа d + q цифр[27]. Так же как и код F, код Е — несамозавершающийся, а спецификация масштабирующего множителя sP и коэффициент повторения r могут отсутствовать. sPrGw.d Ввод, а также интерпретация спецификаций sP и r осуществляется так же, как для кода F. Для вывода по коду G в зависимости от величины выводимого числа выбирается один из кодов F и Е. Пусть М — выводимое значение, причем 10k−1 ≤ М < 10k, где 0 ≤ k ≤ d, тогда вывод производится как для кода F(w − 4).(d − k), 4X; в противном случае используется код Ew.d. Отметим, что масштабирующий множитель игнорируется в случае, когда для вывода выбирается код F. Код G несамозавершающийся. Тема. Создайте пакет программ форматного ввода/вывода для вашей ЭВМ. В общем случае он будет иметь ряд входных точек, доступных для пользователя (в роли которого, как правило, выступает сгенерированная компилятором объектная программа), а также ряд внутренних подпрограмм, которые должны быть защищены от доступа со стороны пользователя. Среди пользовательских входов должны быть: вход для инициализации с параметрами, определяющими операцию ввода или вывода, канал ввода/вывода и формат; входы для каждого типа переменных (вещественной, целой, логической и еще любой из них, используемой для представления текстовых данных), а также вход для терминирования ввода/вывода. Внутреннее представление данных может иметь вид, принятый на вашей ЭВМ, или вид, описанный в гл. 25 для ЭВМ УМ-1. Проведите основательное тестирование своих программ и убедитесь, что округление и обработка особых случаев выполняется правильно, а в случае ошибок выдаются соответствующие сообщения. Указания исполнителю. Наиболее трудная часть задачи — составить ясное представление о поведении вещественных чисел на вашей ЭВМ. Преобразование данных текстового, целого и логического типов выполняется легко, а для сканирования формата и поддержания буферов годятся весьма простые методы. Однако вы, вероятно, обнаружите, что для реализации вполне правильного округления придется серьезно поразмыслить, а, быть может, и немного поэкспериментировать. Обязательно включите в свои тесты значения чуть больше и чуть меньше степеней 10, чуть меньше 10−d и т. д. Не поддавайтесь соблазну выделять все увеличивающееся количество частных случаев с целью исправить допущенные ранее в работе промахи, попытайтесь вместо этого найти какой-то другой подход. Одной из наших досаднейших программистских неудач был пакет форматного ввода/вывода, разросшийся наподобие Топси до свыше 3000 строк на языке ассемблера. Как непросто теперь заменить его более ясной и эффективной программой примерно в 1000 строк, написанной еще кем-нибудь! С какой радостью мы бы навсегда избавились от этого монстра! Инструментовка. Это одна из тех задач, для которых можно порекомендовать язык ассемблера. Пакеты форматного ввода/вывода должны быть достаточно эффективными, и к тому же они принадлежат к числу программ, время выполнения которых не концентрируется в нескольких компактных циклах, а сильно размазано (для большинства программ на 10% текста приходится 90% времени выполнения). Кроме того, языки более высокого уровня скрывают от программиста тонкости специфической работы с данными, необходимые для реализации форматного ввода/вывода. Если в вашем распоряжении имеется такой язык, как BLISS или PL/360 (или, быть может, XPL), то это самые лучшие кандидаты, поскольку они допускают достаточно хороший контроль над машиной и свободны от недостатков языка ассемблера. Длительность исполнения. Одному исполнителю на 5 недель. Развитие темы. Имеется масса возможностей расширить форматы. Можно добавлять новые коды. Например: 'x···x' То же самое, что nHX···x. Апостроф представляется парой подряд стоящих кавычек. Bw, Ow, Zw Ввод и вывод соответственно в двоичном, восьмеричном и шестнадцатеричном коде. В этом случае внутреннее представление элемента данных воспринимается как цепочка битов, прижатая к правому краю. Tn Переместиться в n-ю позицию текущей записи. Такое передвижение может привести к повторному чтению или записи части вводного или выводного файла. Можно также ослабить слишком строгие требования для ширины поля ввода/вывода. Так, формат E.d может означать при выводе, что система сама подберет ширину w поля, а одиночный код I при вводе может означать, что следующее целое число будет ограничено пробелом, запятой или концом записи, а не шириной поля. Почти в каждой системе ввода/вывода для Фортрана есть подобные расширения, которые вы также можете добавить.Литература
USA Standart FORTRAN. United States ot America Standards Institute, New York, 1966. Описанные нами коды формата несколько отличаются от тех, которые приняты в указанном стандарте. Нам кажется, что стандарт в этой области не вполне отражает потребности практического программирования, хотя, если вместо описанных здесь кодов будут реализованы спецификации, приведенные в стандарте, мы будем только рады (объем работы примерно одинаковый). Чтение стандарта уже само по себе есть некое испытание, которому надо подвергнуть каждого преданного пользователя Фортрана. Остается только удивляться: для какого же языка написаны существующие трансляторы, поскольку ясно, что они — не для стандартного Фортрана!? *Катцан Г. Язык Фортран-77. Пер. с англ. — М.: Мир, 1982. В книге описывается новый стандарт для языка Фортран. Основные расширения, касающиеся форматного ввода/вывода, — это ввод/вывод в свободном формате и ввод/вывод текстовых цепочек произвольной длины (в связи с введением текстового типа данных).19. Пиковое положение, или Статистика пасьянсов
У каждого программиста рано или поздно наступает момент, когда работа не идет. Без каких-либо видимых причин программа прямо-таки сопротивляется всем вашим усилиям написать ее. Каждая новая попытка тут же оборачивается грудой макулатуры, и корзина снова полна испорченными бланками. Выход один — забросить на время эту задачу. Если ваш начальник станет выражать свое неудовольствие, объясните ему, что для повышения продуктивности вам необходимо снять умственное напряжение. И пойдите в кино. Или гоняйте мяч до изнеможения. Пообсуждайте Критику чистого разума с какой-нибудь симпатичной вам особой противоположного пола. Просадите небольшую сумму на скачках. Или возьмите колоду карт и приготовьтесь убить часа три, раскладывая свой любимый пасьянс. (В Англии бы сказали: приготовьтесь потерять терпение[28].) Есть две разновидности пасьянсов. В пасьянсах первого рода есть правила раскладки карт, а также правила перекладывания карт. Раскладывание такого пасьянса — это некий механический ритуал, где человек выступает в роли автомата. Такая игра, хоть она и лишена творческого элемента, поможет вам в полной мере вкусить и понять эмоциональное состояние компьютера, выполняющего одну из ваших программ. В пасьянсах второго рода игроку предоставляется некоторая свобода выбора. Человек уже не пассивный наблюдатель, он вступает в борьбу против слепого Случая, олицетворенного перетасованной колодой игральных карт. В таких играх обычно имеются некоторые искусственные условия выигрыша, однако почти ничего не известно о том, каких результатов можно достичь, играя наилучшим образом. Прибегнув к помощи компьютера, можно найти тот эталон, с которым игрок мог бы сравнивать свои результаты. Итак, не раскладывание пасьянса, а программирование игры поможет вам снять умственное напряжение.Правила раскладывания одного пасьянса
Возьмите обычную колоду карт и тщательно ее перетасуйте. Затем разложите карты так, как показано на рис. 19.1. В середине выложите слева направо ряд из семи стопок, содержащих соответственно ноль, одну, две, …, шесть карт рубашкой вверх и еще по одной карте сверху рубашкой вниз. На это уйдет 28 карт. Остальные 24 карты разложите в шесть столбиков из четырех перекрывающихся карт под шестью правыми стопками. Все карты в столбиках лежат рубашкой вниз, они перекрывают друг друга таким образом, что самая нижняя, последняя карта столбика лежит поверх предыдущей, которая в свою очередь лежит поверх предыдущей, и т. д. до карты, которая лежит поверх соответствующей стопки и служит начальной картой для этого столбика. Выкладывать карты следует так, чтобы старшинство и масть карты, лежащей рубашкой вниз, были хорошо видны. Наконец, в верхней части стола нужно предусмотреть место для четырех счетных стопок, по одной для каждой масти. На рис. 19.1 изображен общий вид первоначальной раскладки. Рисунок 19.1. Сдача карт для пасьянса. Карты в стопках под первыми картами столбиков со второго по седьмой лежат рубашкой вверх, остальные карты лежат рубашкой вниз.
Один ход состоит в том, что выбирается произвольная карта, лежащая рубашкой вниз, вместе со всеми накрывающими ее картами, т. е. со всеми картами, лежащими ниже ее в том же столбике, и эта часть столбика пристраивается в низ какого-либо другого столбика. Перемещение возможно лишь в том случае, если выбранная карта имеет ту же масть и на единицу младше той карты, на которую она накладывается (в этой игре тузы имеют наименьшее старшинство, т. е. соответствуют единице, а наибольшее старшинство имеют короли). На рис. 19.2 изображен пример возможного хода. Если в результате такого перемещения освобождается верхняя, лежащая рубашкой вверх карта стопки, то ход завершается переворачиванием этой карты. В результате хода может также полностью опустошиться один из столбиков; тогда на любом из последующих ходов на освободившееся место можно перенести любого лежащего рубашкой вниз короля вместе со всеми накрывающими его картами. Если какой-то из тузов оказывается последней картой в одном из столбиков, то он перекладывается в верхнюю часть стола и дает начало счетной стопке для своей масти. После того как начата счетная стопка для какой-либо масти, в нее можно добавлять другие карты той же масти по мере того, как они оказываются последними в каком-нибудь столбике, но так, чтобы карты в счетной стопке шли в строго возрастающем порядке по старшинству. Заметим, что если последнюю карту столбика можно положить в счетную стопку, то медлить с этим не стоит, поскольку рано или поздно ее все равно придется туда положить, а до тех пор эта карта может лишь блокировать дальнейшие ходы с участием своего столбика.
Рисунок 19.1. Сдача карт для пасьянса. Карты в стопках под первыми картами столбиков со второго по седьмой лежат рубашкой вверх, остальные карты лежат рубашкой вниз.
Один ход состоит в том, что выбирается произвольная карта, лежащая рубашкой вниз, вместе со всеми накрывающими ее картами, т. е. со всеми картами, лежащими ниже ее в том же столбике, и эта часть столбика пристраивается в низ какого-либо другого столбика. Перемещение возможно лишь в том случае, если выбранная карта имеет ту же масть и на единицу младше той карты, на которую она накладывается (в этой игре тузы имеют наименьшее старшинство, т. е. соответствуют единице, а наибольшее старшинство имеют короли). На рис. 19.2 изображен пример возможного хода. Если в результате такого перемещения освобождается верхняя, лежащая рубашкой вверх карта стопки, то ход завершается переворачиванием этой карты. В результате хода может также полностью опустошиться один из столбиков; тогда на любом из последующих ходов на освободившееся место можно перенести любого лежащего рубашкой вниз короля вместе со всеми накрывающими его картами. Если какой-то из тузов оказывается последней картой в одном из столбиков, то он перекладывается в верхнюю часть стола и дает начало счетной стопке для своей масти. После того как начата счетная стопка для какой-либо масти, в нее можно добавлять другие карты той же масти по мере того, как они оказываются последними в каком-нибудь столбике, но так, чтобы карты в счетной стопке шли в строго возрастающем порядке по старшинству. Заметим, что если последнюю карту столбика можно положить в счетную стопку, то медлить с этим не стоит, поскольку рано или поздно ее все равно придется туда положить, а до тех пор эта карта может лишь блокировать дальнейшие ходы с участием своего столбика.
 Рисунок 19.2. Пример возможного хода с перемещением карт из одного столбика в другой. Карты, начиная с тройки треф и ниже в том же порядке, накладываются поверх четверки треф. Остальные столбики не показаны.
Игра кончается, когда не остается ни одного допустимого хода и ни одну карту нельзя положить в счетную стопку. Счет игры равен суммарному числу карт в счетных стопках. Как выяснилось, эта игра весьма популярна в Лас Вегасе (известном также под названием Город Просаженных Получек[29]). Колоду карт в казино можно получить по цене 1 долл. за карту (плюс 3 долл. за право начать игру), игрок же получает 5 долл. за каждую карту, вошедшую в счет. Таким образом, при счете 11 карт (за что причитается 55 долл.) игрок остается при своих, а каждая карта сверх того — его чистый выигрыш. Сомнительно, чтобы в казино действительно предлагались такие условия, но если это так, то мы вправе Подозревать, что владельцы должны иметь чудовищные прибыли. Каково в действительности ожидаемое число карт в счетных стопках? Насколько нечестными были бы при данных условиях доходы владельцев казино?
Рисунок 19.2. Пример возможного хода с перемещением карт из одного столбика в другой. Карты, начиная с тройки треф и ниже в том же порядке, накладываются поверх четверки треф. Остальные столбики не показаны.
Игра кончается, когда не остается ни одного допустимого хода и ни одну карту нельзя положить в счетную стопку. Счет игры равен суммарному числу карт в счетных стопках. Как выяснилось, эта игра весьма популярна в Лас Вегасе (известном также под названием Город Просаженных Получек[29]). Колоду карт в казино можно получить по цене 1 долл. за карту (плюс 3 долл. за право начать игру), игрок же получает 5 долл. за каждую карту, вошедшую в счет. Таким образом, при счете 11 карт (за что причитается 55 долл.) игрок остается при своих, а каждая карта сверх того — его чистый выигрыш. Сомнительно, чтобы в казино действительно предлагались такие условия, но если это так, то мы вправе Подозревать, что владельцы должны иметь чудовищные прибыли. Каково в действительности ожидаемое число карт в счетных стопках? Насколько нечестными были бы при данных условиях доходы владельцев казино?
Анализ пасьянса
Каждой первоначальной раскладке соответствует в точности один оптимальный результат, хотя достичь его можно при различных последовательностях ходов. По-видимому, существует некоторая очень сложная вероятностная функция для вычисления ожидаемого значения оптимального результата. Но даже если бы удалось явно выписать эту функцию, она, несомненно, содержала бы столь большое количество членов, что вычислить ее было бы делом крайне затруднительным. Нельзя ли вместо этого попытаться сыграть достаточно много партий и извлечь интересующую статистику из полученных таким образом результатов? Эта идея применения моделирования для получения результата, который теоретически может быть непосредственно вычислен, уже встречалась в других главах книги именно потому, что, как и в данном случае, превращение компьютера в модель интересующего нас реального процесса оказывается весьма плодотворным. Какова необходимая последовательность действий при моделировании пасьянса? Во-первых, нужны подпрограммы для получения первоначальной раскладки, для проверки существования возможных ходов в данной позиции, для перемещения карт, для переворачивания верхней карты стопки, для перекладывания карты в счетную стопку — словом, процедуры, реализующие явный процесс раскладывания пасьянса. При помощи этих процедур можно вычислить результат любой заданной последовательности ходов. Для того чтобы найти оптимальный результат, реализуем на базе этих процедур стратегию поиска. После сдачи карт получаем некоторую начальную позицию. Стратегия поиска состоит в выполнении для каждой позиции, получающейся в ходе игры, следующих действий: Подсчитать, сколько возможных ходов имеется для данной позиции. Их всегда не более семи. Если возможных ходов нет, то данная последовательность ходов закончена, и можно записать ее счет. Установить новую текущую позицию, взяв верхний элемент со стека позиций, и возвратиться к началу цикла. Если стек позиций пуст, то закончить поиск. Если есть только один ход, то выполнить его и вернуться к началу цикла. Если ходов несколько, то упорядочить их (способ упорядочения не играет роли), записать в стек позиций текущую позицию, упорядоченный список возможных ходов, а также тот факт, что первый ход уже сделан. Выполнить первый ход и возвратиться к началу цикла. Заметим, что в шаге один, если позиция была взята со стека, неявно предполагается, что при подсчете числа возможных ходов вначале всегда ищется частично завершенный список возможных ходов. Эта стратегия осуществляет поиск «сначала в глубину» по всем возможным последовательностям ходов с запоминанием еще не исследованных позиций в стеке. Поскольку проверяются все возможные последовательности ходов, то данная стратегия гарантирует нахождение некоторой, быть может не единственной, оптимальной последовательности. Одна из неприятных для игрока особенностей этого пасьянса состоит в том, что довольно часто сразу после первоначальной раскладки не оказывается вообще ни одного возможного хода. Раскладка карт — это лишь некоторый сложный способ тасования. Несмотря на значительную вероятность быстрого окончания игры, следует ожидать все же, что дерево позиций может вырасти до очень больших размеров. Но дерево это на деле является графом, поскольку к одной и той же позиции вполне можно прийти после различных последовательностей ходов. Если некоторая позиция уже была однажды исследована, нет нужды рассматривать ее снова. Оптимальный результат игры не зависит от порядка ходов или от конкретной последовательности ходов, ведущей к нему. Если все уже исследованные позиции запоминать, то каждую вновь возникшую позицию можно во избежание повторной обработки сравнивать с этими старыми позициями. Сохранять нужно только сами позиции, без списка возможных ходов. Естественно, при этом возникает проблема поиска в множестве старых позиций. Тема. Напишите программу для нахождения среднего значения и стандартного отклонения оптимального счета в данном пасьянсе. Покажите, что число рассмотренных игр обеспечивает достоверность полученных статистических результатов. Подсчитайте также, если сумеете, среднее число ходов и среднее число точек принятия решения на пути к оптимальному результату. Единственный входной параметр программы — число пасьянсов, которые нужно разложить. Вывод обязательно должен содержать требуемую статистику, но иногда оказываются полезными и другие данные. В частности, можно выдать информацию о распределении памяти для хранения старых позиций. Указания исполнителю. Организация карт в представлении позиции, а также способ хранения старых позиций решающим образом определяют уровень эффективности программы. Если позиция является текущей или находится в стеке, то для нее должно быть известно состояние всех стопок и соответствующих им столбиков, а также счетных стопок. Позиция в стеке должна содержать, кроме того, список еще не проверенных ходов. Для ускорения поиска возможных ходов нужно иметь вектор состояния для всех карт, в котором должны быть такие признаки карты: лежит ли она рубашкой вверх, находится ли уже в счете, лежит ли рубашкой вниз внутри столбика (какого именно?), лежит ли рубашкой вниз в низу столбика (какого именно?). Быть может, вы сумеете придумать другую структуру данных, обеспечивающую быстрое нахождение возможных ходов. В любом случае при запоминании старой позиции часть информации, как уже использованную, можно отбросить, экономя таким образом память. Здесь потребуется два специальных алгоритма. Во-первых, как реализовать тасование карт в ЭВМ? Вот процедура, предложенная Кнутом. Пусть rand52 — функция, генерирующая случайные целые числа, равномерно распределенные в отрезке от 1 до 52. Поместите все карты в массив карта длины 52; как в нем расположены карты вначале — не имеет значения. После этого для i от 1 до 52 поменяйте местами элементы карта[i] и карта[rand52], каждый раз заново обращаясь к функции rand52. Одного такого тасования будет достаточно. Во-вторых, как находить старые позиции? Это классическая задача поиска в растущей базе данных. Очевидным решением тут представляется хеш-таблица, где ключом поиска служит вся позиция. Поскольку полное сравнение двух позиций на равенство, скорее всего, обойдется слишком дорого, то разумно, по-видимому, будет применить виртуальный хеш-код. Пространство, отведенное для хранения старых позиций, может переполняться, поэтому вы должны уметь время от времени освобождать его. Наилучший способ освобождения памяти состоит, пожалуй, в том, чтобы иметь при каждой позиции счетчик, показывающий, сколько раз к ней обращались, и отбрасывать каждый раз те позиции, которые участвовали реже всего. Другой способ, который можно использовать и в сочетании с первым, — хранить список всех старых позиций и всякий раз, когда ищется какая-либо позиция, перемещать ее в голову списка. Когда придет время отбросить часть позиций, то кандидатами на уничтожение будут позиции в хвосте списка, поскольку к ним дольше всего не было обращений. Принятый вами способ отбрасывания старых позиций окажет влияние на выбор стратегии поиска, и наоборот. Заметим, что, хотя алгоритм отбрасывания старых позиций и не влияет на правильность программы анализа пасьянсов, тем не менее он может существенно ее замедлить. Инструментовка. Эта задача требует средств для удобной работы со структурами данных умеренной сложности. В интересах эффективности выделение и освобождение памяти не следует доверять системе, так что Снобол, видимо, не подойдет. Претендентами могут быть языки Алгол W, Паскаль, PL/I, Лисп и даже Кобол. Вы сможете оценить достоинства структур данных, определяемых программистом, если попытаетесь решить эту задачу сначала на одном из упомянутых выше языков, а потом еще раз на языке типа Фортран или XPL, в которых сложные структуры данных приходится представлять при помощи параллельных массивов. Длительность исполнения. Одному исполнителю на 3 недели. Развитие темы. Наиболее очевидное расширение задачи — применить этот метод анализа к другим пасьянсам. Осуществление этой идеи не связано с какими-либо трудностями, если только во время игры не происходит тасования карт. На свете существуют сотни пасьянсов, и ни один из них, насколько нам известно, не подвергался мало-мальски серьезному анализу. На этой задаче можно также изучать зависимости общего числа исследуемых позиций от объема памяти и критерия отбрасывания старых позиций. Иначе говоря, чем исследовать пасьянс при помощи методов поиска, используем задачу о пасьянсе для изучения методов поиска.Литература
Гибсон (Gibson W. В.). How to Play Winning Solitaire. Frederick Fell, New York, NY, 1964. Это единственная из известных автору книг о данном пасьянсе. Кнут (Knuth D. E.). The Art of Computer Programming, Volume 3/Sorting and Searching. Addison-Wesley, Reading, MA, 1973. [Имеется перевод: Кнут Д. Искусство программирования. Т. 3. Сортировка и поиск.— М.: Мир, 1978.] Снова ссылка на книгу Кнута. На этот раз в гл. 6 вы сможете прочитать все о методах поиска, в частности о поиске по хеш-таблице. Разумеется, если вы внимательно изучите всю главу, то, возможно, обнаружите и лучший метод поиска. * «Наука и жизнь», № 12, 1968; № 2, 1978. * Гарднер М. Математические новеллы. — М.: Мир, 1974, с. 336. В двух последних источниках приводится описание простых пасьянсов, которые также можно использовать для упражнения в программировании.20. Квадратный трехчлен, или Пакет Для Алгебраических Вычислений
Основная трудность, с которой сталкивается программист в большинстве языков программирования, — необходимость при записи вычислений разбивать свои уравнения на мелкие части. Так, если требуется производная, то программист должен записать исходную функцию, снять с полки учебник по математическому анализу, применить изложенные там правила и затем записать получившуюся производную. Однако многие операции можно выполнить на символьном уровне, по крайней мере в случае многочленов, если представлять их подходящим образом. Некоторые программы оказались бы совсем ненужными, если бы ЭВМ могла оперировать с многочленами. Объекты, с которыми мы будем работать, — это рациональные функции. Их можно определить рекурсивно. Пусть c — любая вещественная константа. Тогда c — рациональная функция. Пусть x — любая переменная. Тогда x — рациональная функция. Пусть р и q — любые рациональные функции. Тогда p + q, p − q, −p, pq, p/q и (p) все суть рациональные функции. При делении рациональных функций производится упрощение, так чтобы остался только один знак деления. Правила этого упрощения хорошо знакомы школьникам, изучающим алгебру. Пусть p — любая рациональная функция, а c — целочисленная константа. Тогдаpc — рациональная функция. Если с отрицательна, образуйте рациональную функцию 1/p|c| и упростите деление как выше. Рациональными функциями являются только те объекты, которые получаются путем применения конечного числа приведенных выше правил. Кроме определения рациональных функций мы должны описать, как будет выглядеть их запись в качестве исходных данных и на выходе и как вызывать операции. Рациональные функции в качестве исходных данных будут похожи на выражения в стандартном языке программирования. Константы могут изображаться любой последовательностью десятичных цифр с десятичной точкой; если десятичная точка отсутствует, то константа автоматически будет целочисленной. В силу правил образования рациональных функций константы не имеют знака, за исключением констант в показателе степени. Переменная выглядит как идентификатор и может быть любой цепочкой из больших и малых литер алфавита. Из-за ограничений на выбор литер в ЭВМ умножение будет изображаться знаком *, а возведение в степень — знаком ↑. Так, рациональную функцию 2xy + (х² + у²)³ можно записать как 2 * X * Y + (X ↑ 2 + Y ↑ 2) ↑ 3 Некоторые другие имена, в частности имена функций, также будут идентификаторами. Для манипуляций с рациональными функциями нам нужны некоторые команды, чтобы пользователь мог получать ответы на вопросы, на которые не удается ответить с помощью традиционных языков программирования. Для этого нам понадобится обозначать рациональные функции идентификаторами. Самое фундаментальное действие такое: Установить f равным р; Эта команда приводит к тому, что имя рациональной функции f (мы будем писать сокращенно — имя функции) получает в качестве значения рациональную функцию р. Эта операция — символьная; она не вызывает вычисления р. Если некоторый идентификатор f использован как имя функции, то его нельзя употреблять в последующих командах в качестве переменной; надо иметь в виду, что во время интерпретации потребуется таблица имен, значений и использований. Вместо рациональной функции р может стоять имя функции; в этом случае f получает значение, которое в данный момент имеет р. Все команды заканчиваются точкой с запятой. Примеры описываемой команды: Установить Р равным z*x↑2 + 3.5; Установить fpt равным Р; Бо́льшая часть остальных команд выполняет некоторую операцию над своими операндами и помещает результат в качестве значения некоторого имени функции. Установить f равным сумме р и q; Образовать алгебраическую сумму р и q и записать полученное значение под именем f. Во всех командах исходные данные записываются в свободном формате — границы строк (или перфокарт) несущественны; единственным разделителем команд служит точка с запятой. Операндами могут быть имена функций; в таком случае в операциях используются значения, приписанные этим именам. Установить f равным разности р минус q; Образовать алгебраическую разность р и q и записать полученное значение под именем f. Установить f равным произведению р и q; Образовать алгебраическое произведение р и q и записать результат под именем f. Установить f равным частному при делении р на q; Образовать алгебраическое частное р и q и записать результат под именем f. Для выполнения этой операции не нужно привлекать алгоритм деления многочленов, так как рациональная функция может включать один знак деления. Последующие знаки деления могут быть устранены при помощи школьной алгебры. Установить f равным р в степени с; Рациональная функция р возводится в степень с, и результат записывается под именем f. Показатель степени с должен быть целым числом или именем функции с постоянным значением; если с отрицательно, результатом будет 1/р|с|. Установить f равным р с заменой х на q; Заменить каждое вхождение переменной х в р на q и записать полученное значение под именем f. Отметим, что в результате подстановки переменная х может снова возникнуть в f, но ее не следует вновь заменять на q. Установить f равным производной р по х; Вычислить производную dp/dx и записать полученное значение в f. Конечно, идентификатор х должен быть переменной или именем функции, состоящей из одной переменной. Напечатать р; Напечатать рациональную функцию р в удобном для чтения виде. Конец; Завершение последовательности команд. При реализации команды печати мы сталкиваемся с трудностью, присущей всем программам алгебраических преобразований. При вычислениях функции, как правило, становятся очень сложными. Вместе с тем человек хотел бы получить результаты в достаточно простом виде. Рациональные функции записывают обычно в виде дроби, числитель и знаменатель которой представляют собой сумму членов, включающих только операции умножения и возведения в степень. В каждом таком одночлене все константы перемножены и образуют числовой коэффициент (первый сомножитель), переменные упорядочены (часто по алфавиту) и все степени одной переменной объединены так, чтобы каждая переменная встречалась лишь один раз. Если числовой коэффициент оказывается отрицательным, то такой одночлен должен вычитаться из предыдущих, а не прибавляться к ним. Если коэффициент окажется равным нулю или единице, то весь одночлен или коэффициент должен быть опущен. Если показатель степени отрицателен, то одночлен фактически есть дробь; в этом случае нужно освободиться от знаменателя с помощью стандартных алгебраических правил суммирования дробей. И наконец, следует приводить подобные члены, т. е. объединять одночлены, имеющие одинаковые наборы переменных и степеней, с соответствующим изменением коэффициентов. Все эти преобразования можно выполнять путем приведения функции к некоторому каноническому внутреннему представлению. В нашем случае можно выбрать такое представление, чтобы рациональные функции были почти готовы для печати; результат каждой операции должен преобразовываться к стандартному виду. Можно и по-другому выбрать внутреннее представление, так, чтобы операция печати преобразовывала представление функции, когда это необходимо. Однако требуемый для такого преобразования объем работы может быть сколь угодно большим. Независимо от выбранного метода для целей упрощения нужно различать целые и вещественные константы, с тем чтобы погрешность машинной арифметики не помешала распознаванию нулевых и единичных значений. Заметьте также, что возведение в первую степень обычно опускают. На рис. 20.1 показаны простая программа и ее результат. Тема. Напишите программу для работы с рациональными функциями, реализующую описанные выше возможности. Исходными данными должен быть список команд в свободном формате, а результатом — рациональные функции в формате, удобном для чтения. Переменные, константы и слова, входящие в запись команды, не должны переходить с одной строки на другую, но для самих команд и рациональных функций это вполне допустимо. Определение «удобного» формата печати довольно туманно, зато здесь вы можете продемонстрировать свое искусство в удовлетворении тех потребностей пользователей, которые они сами не могут сформулировать. Не забывайте про доказательство правильности результатов, выдаваемых программами. Одна из важных черт программ работы с рациональными функциями — это способность точно выполнять арифметические действия над целыми числами; позаботьтесь об этом в вашей программе.
Рекомендации исполнителю. Чтение программой команд и рациональных функций требует привлечения некоторых простых методов компиляции, в частности лексического анализа для распознавания символов и синтаксического анализа для построения внутреннего представления. Необходимые сведения содержатся в литературе, указанной в других главах. В процессе выполнения программы вам придется поддерживать расширяющуюся таблицу имен и значений; для этого также имеется простой метод. Самая трудная часть реализации — это выбор внутреннего представления для рациональных функций. Они, несомненно, должны представляться с помощью некоторого варианта списочной или древовидной структуры, но какого именно?
Одним из возможных представлений является стандартное арифметическое дерево, содержащее переменные и константы в листьях, а операции — во внутренних узлах. Такая форма представления особенно подходит для подстановки и алгебраических операций, но для печати она слишком беспорядочна. Другая возможность — дерево, содержащее на верхнем уровне числитель и знаменатель, на следующем уровне — одночлены и на еще более низком уровне — сомножители. Такое дерево будет легко напечатать, но с ним трудно работать. Что бы вы ни выбрали, не забывайте копировать структуры данных при выполнении подстановки, иначе более позднее изменение в подставляемой функции повлияет также и на функцию, в которую она подставлялась.
Инструментовка. Это еще одна задача, требующая списков или деревьев и рекурсивных процедур для их обработки. Для таких задач был создан Лисп, но наравне с ним подойдут и многие другие языки для работы со списками. Снобол несколько слабее по части внутренней обработки данных, но чрезвычайно мощные возможности по анализу вводимой и подготовке выводимой информации делают Снобол конкурентоспособным кандидатом. На самом деле здесь подойдет любой язык типа Паскаля или PL/I, так или иначе приспособленный для работы с текстами, имеющий определяемые структуры данных и рекурсивные процедуры.
Длительность исполнения. Одному исполнителю на 3 недели.
Развитие темы. В настоящее время широко используются многие системы алгебраических преобразований. Как правило, в их основе лежат функции, подобные описанным выше. Дальнейшее развитие происходит по трем направлениям: введение новых типов данных, новых операций и эвристических процедур, предназначенных для выполнения действий с нечетко определенным результатом. Новые типы данных взаимосвязаны с новыми операциями. Можно, например, добавить к рациональным функциям тригонометрические, показательные функции и логарифмы. В таком случае надо будет изменить операцию возведения в степень, чтобы она допускала любой операнд в качестве показателя степени, кроме того, понадобится операция логарифмирования, в которой будет указываться основание логарифмов и логарифмируемая функция. Отметим, что при введении новых типов данных и операций следует убедиться в замкнутости пространства функций, которые могут быть порождены произвольной последовательностью операций. Замкнутость означает, что всякую функцию, которую можно породить, можно также в принципе записать в команде Установить.
Для многих важных математических операций не существует методов, которые позволяли бы всегда вычислять результат в символьном виде. Важное место среди них занимает интегрирование. Хотя любая рациональная функция имеет неопределенный интеграл, простой пример функции 1/х (неопределенный интеграл от нее — ln x) показывает, что нам не надо далеко ходить за функциями, нарушающими границы замкнутого пространства рациональных функций. Расширение пространства функций путем добавления показательных функций и логарифмов, как предложено выше, лишь обостряет проблему. Не решает проблемы даже использование определенного интеграла, поскольку результат определенного интегрирования может и не быть константой, если подинтегральное выражение содержит переменные, отличные от переменной интегрирования, или если пределы интегрирования не константы. Символьные интеграторы были одними из первых программ, написанных для демонстрации «интеллектуального» поведения ЭВМ. Если вы будете работать над предлагаемой задачей в два или три раза дольше, то сможете создать примитивный интегратор.
Введение новых функций создает еще одну проблему. Для более сложных функций, которые теперь можно построить, не существует стандартного формата вызова. Кроме того, выбор применяемых законов упрощения становится нелегким делом. Поскольку теперь применимо гораздо больше алгебраических законов — тригонометрические тождества, законы, связывающие показательные и логарифмические функции, законы о константах, — может случиться, что программа будет тратить большую часть времени на упрощение внутреннего представления выражений. Упрощение с целью облегчить человеку понимание результатов — очень важная и сложная тема; от программиста требуется немалое искусство, чтобы успешно реализовать упрощение.
Тема. Напишите программу для работы с рациональными функциями, реализующую описанные выше возможности. Исходными данными должен быть список команд в свободном формате, а результатом — рациональные функции в формате, удобном для чтения. Переменные, константы и слова, входящие в запись команды, не должны переходить с одной строки на другую, но для самих команд и рациональных функций это вполне допустимо. Определение «удобного» формата печати довольно туманно, зато здесь вы можете продемонстрировать свое искусство в удовлетворении тех потребностей пользователей, которые они сами не могут сформулировать. Не забывайте про доказательство правильности результатов, выдаваемых программами. Одна из важных черт программ работы с рациональными функциями — это способность точно выполнять арифметические действия над целыми числами; позаботьтесь об этом в вашей программе.
Рекомендации исполнителю. Чтение программой команд и рациональных функций требует привлечения некоторых простых методов компиляции, в частности лексического анализа для распознавания символов и синтаксического анализа для построения внутреннего представления. Необходимые сведения содержатся в литературе, указанной в других главах. В процессе выполнения программы вам придется поддерживать расширяющуюся таблицу имен и значений; для этого также имеется простой метод. Самая трудная часть реализации — это выбор внутреннего представления для рациональных функций. Они, несомненно, должны представляться с помощью некоторого варианта списочной или древовидной структуры, но какого именно?
Одним из возможных представлений является стандартное арифметическое дерево, содержащее переменные и константы в листьях, а операции — во внутренних узлах. Такая форма представления особенно подходит для подстановки и алгебраических операций, но для печати она слишком беспорядочна. Другая возможность — дерево, содержащее на верхнем уровне числитель и знаменатель, на следующем уровне — одночлены и на еще более низком уровне — сомножители. Такое дерево будет легко напечатать, но с ним трудно работать. Что бы вы ни выбрали, не забывайте копировать структуры данных при выполнении подстановки, иначе более позднее изменение в подставляемой функции повлияет также и на функцию, в которую она подставлялась.
Инструментовка. Это еще одна задача, требующая списков или деревьев и рекурсивных процедур для их обработки. Для таких задач был создан Лисп, но наравне с ним подойдут и многие другие языки для работы со списками. Снобол несколько слабее по части внутренней обработки данных, но чрезвычайно мощные возможности по анализу вводимой и подготовке выводимой информации делают Снобол конкурентоспособным кандидатом. На самом деле здесь подойдет любой язык типа Паскаля или PL/I, так или иначе приспособленный для работы с текстами, имеющий определяемые структуры данных и рекурсивные процедуры.
Длительность исполнения. Одному исполнителю на 3 недели.
Развитие темы. В настоящее время широко используются многие системы алгебраических преобразований. Как правило, в их основе лежат функции, подобные описанным выше. Дальнейшее развитие происходит по трем направлениям: введение новых типов данных, новых операций и эвристических процедур, предназначенных для выполнения действий с нечетко определенным результатом. Новые типы данных взаимосвязаны с новыми операциями. Можно, например, добавить к рациональным функциям тригонометрические, показательные функции и логарифмы. В таком случае надо будет изменить операцию возведения в степень, чтобы она допускала любой операнд в качестве показателя степени, кроме того, понадобится операция логарифмирования, в которой будет указываться основание логарифмов и логарифмируемая функция. Отметим, что при введении новых типов данных и операций следует убедиться в замкнутости пространства функций, которые могут быть порождены произвольной последовательностью операций. Замкнутость означает, что всякую функцию, которую можно породить, можно также в принципе записать в команде Установить.
Для многих важных математических операций не существует методов, которые позволяли бы всегда вычислять результат в символьном виде. Важное место среди них занимает интегрирование. Хотя любая рациональная функция имеет неопределенный интеграл, простой пример функции 1/х (неопределенный интеграл от нее — ln x) показывает, что нам не надо далеко ходить за функциями, нарушающими границы замкнутого пространства рациональных функций. Расширение пространства функций путем добавления показательных функций и логарифмов, как предложено выше, лишь обостряет проблему. Не решает проблемы даже использование определенного интеграла, поскольку результат определенного интегрирования может и не быть константой, если подинтегральное выражение содержит переменные, отличные от переменной интегрирования, или если пределы интегрирования не константы. Символьные интеграторы были одними из первых программ, написанных для демонстрации «интеллектуального» поведения ЭВМ. Если вы будете работать над предлагаемой задачей в два или три раза дольше, то сможете создать примитивный интегратор.
Введение новых функций создает еще одну проблему. Для более сложных функций, которые теперь можно построить, не существует стандартного формата вызова. Кроме того, выбор применяемых законов упрощения становится нелегким делом. Поскольку теперь применимо гораздо больше алгебраических законов — тригонометрические тождества, законы, связывающие показательные и логарифмические функции, законы о константах, — может случиться, что программа будет тратить большую часть времени на упрощение внутреннего представления выражений. Упрощение с целью облегчить человеку понимание результатов — очень важная и сложная тема; от программиста требуется немалое искусство, чтобы успешно реализовать упрощение.
Литература
Мозес (Moses J.). Algebraic Simplification: A Guide for the Perplexed, CACM, 14, 8, pp. 527–537, 1971. Мозес (Moses J.). Symbolic Integration: The Stormy Decade, CACM, 14, 8, pp. 548–560, 1971. Этот выпуск САСМ целиком посвящен символьной алгебре и ее приложениям. Две статьи Мозеса — хорошие обзоры, но остальные статьи тоже интересны. Библиография в этих статьях должна помочь в исследовании любой темы во всей этой области.21. Превратное обратное, или Ошибки при работе с плавающей точкой
Многие из методов, которые сейчас изучаются в средней школе, создавались величайшими математиками в течение столетий. Среди них — методы решения системы линейных уравнений, которые неявно включают методы обращения квадратных матриц. Начинающий алгебраист, изучая эти алгоритмы, может усомниться в том, что они всегда будут работать; но, испробовав метод на двух-трех примерах* наш скептик отбросит всякие сомнения. Он даже себе не представляет, какой его ждет удар: программа, написанная им в соответствии с простым и обоснованным алгоритмом, дает совершенно неверные результаты. Разве можно заподозрить, чтобы метод обращения матриц, придуманный королем математиков Гауссом, оказался несостоятельным? Прежде всего освежим в памяти основные положения. Матрица — это квадратный массив вещественных чисел, в котором по горизонтали и вертикали располагается по n ≥ 1 элементов. Произведение С матрицы А справа на матрицу В записывается в виде С = АВ и задается формулой Здесь подразумевается, что А, В и С — матрицы размера n × n. Умножение некоммутативно; можно найти такие матрицы А и В, что АВ ≠ ВА. Обратной матрицей к матрице А будет такая матрица А−1, что
AА−1 = А−1A = I
где I — единичная матрица, определяемая формулами Iii = 1 и Iij = 0 для i ≠ j. Большинство матриц имеет обратные, но не все. К сожалению, простейший способ обнаружить такие вырожденные матрицы состоит в том, чтобы попытаться вычислить обратную матрицу и потерпеть неудачу.
Как вычислить обратную матрицу? Следующий алгоритм принадлежит Гауссу.
Во-первых, положите матрицу X равной матрице I. В процессе вычислений матрица А будет в конце концов преобразована в I, матрица X, которая изначально была единичной матрицей, станет обратной к матрице А.
Для каждого столбца А, начиная со столбца 1 слева и кончая столбцом n справа, выполните следующее: Обозначим столбец, который будет обрабатываться на каждом этапе, символом j.
Пусть
Здесь подразумевается, что А, В и С — матрицы размера n × n. Умножение некоммутативно; можно найти такие матрицы А и В, что АВ ≠ ВА. Обратной матрицей к матрице А будет такая матрица А−1, что
AА−1 = А−1A = I
где I — единичная матрица, определяемая формулами Iii = 1 и Iij = 0 для i ≠ j. Большинство матриц имеет обратные, но не все. К сожалению, простейший способ обнаружить такие вырожденные матрицы состоит в том, чтобы попытаться вычислить обратную матрицу и потерпеть неудачу.
Как вычислить обратную матрицу? Следующий алгоритм принадлежит Гауссу.
Во-первых, положите матрицу X равной матрице I. В процессе вычислений матрица А будет в конце концов преобразована в I, матрица X, которая изначально была единичной матрицей, станет обратной к матрице А.
Для каждого столбца А, начиная со столбца 1 слева и кончая столбцом n справа, выполните следующее: Обозначим столбец, который будет обрабатываться на каждом этапе, символом j.
Пусть  есть наибольший по абсолютной величине элемент в столбце j ниже строки j − 1. Если М равно нулю, то А — вырожденная матрица и продолжать обращение не имеет смысла. В противном случае поменяйте местами в обеих матрицах А и X строку j и строку, в которой находится М. И наконец, разделите каждый элемент в строке j матриц А и X на новое значение Ajj.
Теперь для всех строк i, i ≠ j, выполните все вычитания:
Aik = Aik − AijAjk, j ≤ k ≤ n,
Xik = Xik − AijXjk, 1 ≤ k ≤ n.
Результатом всех этих поэлементных вычитаний будет вычитание из строки i строки j с коэффициентом Ajj в обеих матрицах А и X. После выполнения этого шага для всех j все элементы сверху и снизу от Ajj станут нулевыми, а сам элемент Ajj будет равен единице. В матрице А не нужно выполнять вычитания слева от столбца j, поскольку все элементы строки j слева от Ajj равны нулю.
Для любого алгебраиста будет одно удовольствие доказать, что этот алгоритм всегда работает правильно и после его остановки X = А−1, если матрица А невырожденна. Вы едва ли найдете алгоритм, более приспособленный для структурной реализации. Почему бы нам, исключительно ради забавы, не провести небольшую проверку? Матрица Гильберта Hn порядка n определяется формулой
есть наибольший по абсолютной величине элемент в столбце j ниже строки j − 1. Если М равно нулю, то А — вырожденная матрица и продолжать обращение не имеет смысла. В противном случае поменяйте местами в обеих матрицах А и X строку j и строку, в которой находится М. И наконец, разделите каждый элемент в строке j матриц А и X на новое значение Ajj.
Теперь для всех строк i, i ≠ j, выполните все вычитания:
Aik = Aik − AijAjk, j ≤ k ≤ n,
Xik = Xik − AijXjk, 1 ≤ k ≤ n.
Результатом всех этих поэлементных вычитаний будет вычитание из строки i строки j с коэффициентом Ajj в обеих матрицах А и X. После выполнения этого шага для всех j все элементы сверху и снизу от Ajj станут нулевыми, а сам элемент Ajj будет равен единице. В матрице А не нужно выполнять вычитания слева от столбца j, поскольку все элементы строки j слева от Ajj равны нулю.
Для любого алгебраиста будет одно удовольствие доказать, что этот алгоритм всегда работает правильно и после его остановки X = А−1, если матрица А невырожденна. Вы едва ли найдете алгоритм, более приспособленный для структурной реализации. Почему бы нам, исключительно ради забавы, не провести небольшую проверку? Матрица Гильберта Hn порядка n определяется формулой
 Вычислите обратную к Hn матрицу для n = 1, 2, …, 20, 25, 30, 35, 40, 45, 50. Вы, несомненно, понимаете, что результат получится не вполне точным из-за небольших погрешностей машинной арифметики, но он должен быть очень близок к точной обратной матрице. Мерой погрешности служит левая остаточная матрица L = (Hn)−1Hn − I и правая остаточная матрица R = Hn(Hn)−1 − I; обе эти матрицы должны быть нулевыми, но, вероятно, не будут.
Конечно, если бы все элементы матриц L и R были порядка, скажем, 10−20, то мы бы не имели забот. Для всех практических целей 10−20 есть нуль, если элементы исходной матрицы равны в среднем 1/50 или больше. Существует, однако, точный способ оценки величины остаточных матриц L и R. Определим норму по строкам матрицы А как
Вычислите обратную к Hn матрицу для n = 1, 2, …, 20, 25, 30, 35, 40, 45, 50. Вы, несомненно, понимаете, что результат получится не вполне точным из-за небольших погрешностей машинной арифметики, но он должен быть очень близок к точной обратной матрице. Мерой погрешности служит левая остаточная матрица L = (Hn)−1Hn − I и правая остаточная матрица R = Hn(Hn)−1 − I; обе эти матрицы должны быть нулевыми, но, вероятно, не будут.
Конечно, если бы все элементы матриц L и R были порядка, скажем, 10−20, то мы бы не имели забот. Для всех практических целей 10−20 есть нуль, если элементы исходной матрицы равны в среднем 1/50 или больше. Существует, однако, точный способ оценки величины остаточных матриц L и R. Определим норму по строкам матрицы А как
 Добавьте к своей программе, которая вычисляет обратную к матрице Гильберта, подпрограмму, печатающую таблицу |L|r и |R|r для каждой обратной матрицы. Проверьте вашу программу на отсутствие ошибок. Не сможете ли вы теперь объяснить, почему остаточные матрицы столь велики. Уверены ли вы в правильности программы?
Ваша программа правильна; причина неполадок — погрешность машинной арифметики. Матрицы Гильберта внешне выглядят вполне безобидно, однако они специально предназначены для демонстрации накопления ошибок в длинном ряду взаимосвязанных вычислений. Вы, быть может, считаете источником бед то, что ваш компьютер хранит недостаточное число цифр вещественных чисел. На многих ЭВМ имеется арифметика двойной точности. Предусмотрев в своем алгоритме двойную точность, вы сможете улучшить ситуацию, но заведомо не сможете полностью решить проблему. Весь этот этюд посвящен изучению влияния арифметики ограниченной точности на алгоритмы, которые являются абсолютно точными для «действительных» чисел (как их понимают математики). Прикладные математики и специалисты по численным методам в программистских лабораториях тратят большую часть времени на изменение теоретических алгоритмов, чтобы они могли работать на реальных ЭВМ[30].
Тема. Запрограммируйте алгоритм обращения матриц и проверьте его на матрицах Гильберта указанных выше порядков. Напечатайте таблицу или начертите график зависимости |L|r и |R|r от порядка n матрицы Hn. Если используемый вами язык допускает выбор точности чисел, то повторите вычисление обратных матриц с большей точностью, чтобы увидеть, улучшится ли в результате таблица или график ошибок. (Мудрый программист так составит программу, чтобы изменение точности достигалось путем замены небольшого числа деклараций.) Следите также за числом фактических перестановок строк при выборе ведущего элемента; оно будет показывать, насколько плохо алгоритм согласуется с теорией.
Указания исполнителю. В этом этюде требуется прямая реализация алгоритма. Единственная трудность — это проверка соответствия программы теоретическим определениям и алгоритму. Не делайте над алгоритмом никаких оптимизирующих преобразований; вы изучаете, до чего можно дойти, если слепо следовать советам математиков, забыв о важнейшем положении — о точности вычислений.
Инструментовка. Подойдет любой алгебраический язык. Фортран был создан для решения матричных задач. Сравните его с каким-нибудь более современным языком, запрограммировав этот этюд на обоих языках.
Длительность исполнения. Одному исполнителю на 1 неделю.
Развитие темы. Если в достаточной степени расширить задачу, то она послужит основой семестрового курса методов вычислений. Тем не менее вы можете получить дополнительную информацию о поведении ошибок, если вычислите |L| и |R| с использованием других норм, отличных от нормы по строкам, например нормы по столбцам:
Добавьте к своей программе, которая вычисляет обратную к матрице Гильберта, подпрограмму, печатающую таблицу |L|r и |R|r для каждой обратной матрицы. Проверьте вашу программу на отсутствие ошибок. Не сможете ли вы теперь объяснить, почему остаточные матрицы столь велики. Уверены ли вы в правильности программы?
Ваша программа правильна; причина неполадок — погрешность машинной арифметики. Матрицы Гильберта внешне выглядят вполне безобидно, однако они специально предназначены для демонстрации накопления ошибок в длинном ряду взаимосвязанных вычислений. Вы, быть может, считаете источником бед то, что ваш компьютер хранит недостаточное число цифр вещественных чисел. На многих ЭВМ имеется арифметика двойной точности. Предусмотрев в своем алгоритме двойную точность, вы сможете улучшить ситуацию, но заведомо не сможете полностью решить проблему. Весь этот этюд посвящен изучению влияния арифметики ограниченной точности на алгоритмы, которые являются абсолютно точными для «действительных» чисел (как их понимают математики). Прикладные математики и специалисты по численным методам в программистских лабораториях тратят большую часть времени на изменение теоретических алгоритмов, чтобы они могли работать на реальных ЭВМ[30].
Тема. Запрограммируйте алгоритм обращения матриц и проверьте его на матрицах Гильберта указанных выше порядков. Напечатайте таблицу или начертите график зависимости |L|r и |R|r от порядка n матрицы Hn. Если используемый вами язык допускает выбор точности чисел, то повторите вычисление обратных матриц с большей точностью, чтобы увидеть, улучшится ли в результате таблица или график ошибок. (Мудрый программист так составит программу, чтобы изменение точности достигалось путем замены небольшого числа деклараций.) Следите также за числом фактических перестановок строк при выборе ведущего элемента; оно будет показывать, насколько плохо алгоритм согласуется с теорией.
Указания исполнителю. В этом этюде требуется прямая реализация алгоритма. Единственная трудность — это проверка соответствия программы теоретическим определениям и алгоритму. Не делайте над алгоритмом никаких оптимизирующих преобразований; вы изучаете, до чего можно дойти, если слепо следовать советам математиков, забыв о важнейшем положении — о точности вычислений.
Инструментовка. Подойдет любой алгебраический язык. Фортран был создан для решения матричных задач. Сравните его с каким-нибудь более современным языком, запрограммировав этот этюд на обоих языках.
Длительность исполнения. Одному исполнителю на 1 неделю.
Развитие темы. Если в достаточной степени расширить задачу, то она послужит основой семестрового курса методов вычислений. Тем не менее вы можете получить дополнительную информацию о поведении ошибок, если вычислите |L| и |R| с использованием других норм, отличных от нормы по строкам, например нормы по столбцам:
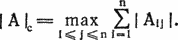 Ниже определены нормы L1, L2 и L∞:
Ниже определены нормы L1, L2 и L∞:
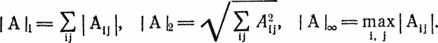 Дополните значениями этих норм вашу таблицу анализа ошибок. Наблюдаются ли какие-либо существенные отличия одной нормы от остальных по форме или приблизительному положению кривой ошибок?
Дополните значениями этих норм вашу таблицу анализа ошибок. Наблюдаются ли какие-либо существенные отличия одной нормы от остальных по форме или приблизительному положению кривой ошибок?
Литература
Конт, де Боор (Conte S. D., de Boor С). Elementary Numerical Analysis, 2nd ed. McGraw-Hill, New York, NY, 1972. Стьюарт (Stewart G. W.). Introduction to Matrix Computations. Academic Press, New York, NY, 1973. Конт и де Боор написали превосходный учебник по основам методов вычислений, используемый во многих учебных заведениях. Он содержит куда больше информации по методам вычислений, чем могло бы понадобиться любому нормальному человеку. Если вы все же хотите узнать еще больше о задаче с матрицами, обратитесь к книге Стьюарта. Там описаны теория и практика линейной алгебры. * Кнут Д. Искусство программирования для ЭВМ. Т. 1. Основные алгоритмы. Пер. с англ. — М.: Мир, 1976, упр. 1.2.3.45. В этом упражнении точно вычисляются матрицы, обратные к матрицам Гильберта, и обсуждается, как их использовать для проверки точности алгоритма обращения.22. π эр Квадрат, или Арифметические вычисления с высокой точностью
Математику часто считают сухой наукой, однако и математику творили люди. Одной из самых печальных была судьба Уильямса Шенкса, жившего в девятнадцатом веке и посвятившего себя вычислению числа π с высокой точностью. Закончив многолетний труд, Шенкс в 1837 г. опубликовал значение π до 707-го десятичного знака, впоследствии исправив некоторые знаки. Может быть, надо счесть за благо, что Шенкс умер в 1882 г., поскольку в 1946 г. было показано, что его вычисления ошибочны начиная с 528-го десятичного знака. Фактически Шенкс не продвинулся дальше своих предшественников. Полученное Шенксом значение было проверено, вероятно, с помощью механических устройств, а компьютер был впервые использован для вычисления π только в 1949 г.; это была машина ENIAC. Даже тогда проект был монументальным. Джордж У. Рейтуиснер писал: «Поскольку получить машину в рабочее время было практически невозможно, мы воспользовались разрешением выполнить эту работу за 4 выходных дня в период летних отпусков, когда ENIAC стоял без дела». Собственно вычисления (не программирование!) заняли 70 часов: было получено несколько больше 2 000 цифр. Все это время приходилось постоянно обслуживать компьютер, поскольку из-за ограниченности его возможностей требовались постоянная перфорация и ввод промежуточных результатов. Те первые программисты так же далеки от нынешних, как Шенкс далек от них. Как бы мы стали вычислять π? Во-первых, необходимо выражение, которое можно вычислять. Ряд π/4 = 1 − 1/3 + 1/5 − 1/7 + 1/9 − … довольно прост для понимания, но он ужасно медленно сходится. Гораздо лучше ряд для арктангенса arctg x = x − х3/3 + х5/5 − х7/7 + …, |x| ≤ 1 Объединим его с формулой сложения для тангенса tg (a + b) = (tg a + tg b)/(1 − tg a · tg b) и выберем а и b так, чтобы tg (a + b) = 1 = tg π/4. (Учитывая, что tg (arctg x) = х для −π/2 < х < π/2, можно взять, например, а = arctg (1/2), b = arctg (1/3).) Тогда arctg (tg (a + b)) = a + b = arctg 1 = π/4, и теперь можно использовать приведенный выше ряд для нахождения a и b. На практике чаще всего используются следующие суммы: π/4 = 4 arctg (1/5) − arctg (1/239), π/4 = 8 arctg (1/10) − 4 arctg (1/515) − arctg (1/239), π/4 = 3 arctg (1/4) + arctg (1/20) + arctg (1/1985). Теперь мы собираемся просуммировать эти ряды на ЭВМ. Как известно, все, что нужно для суммирования, — это простой итерационный цикл, но тут возникает одна проблема. Точность вычислений на ЭВМ ограничена, а весь смысл этого упражнения в том, чтобы найти много-много цифр числа π, значительно превзойдя обычную точность. Первое, что приходит в голову, — промоделировать ручные методы выполнения арифметических действий. Будем представлять числа очень большими целочисленными массивами (по одной десятичной цифре в каждом элементе), тогда ясно, как составить программы сложения, вычитания и умножения. Запрограммировать ручной метод деления несколько сложнее, но все же возможно. Неприемлемым, однако, оказывается время выполнения алгоритмов. Хотя на это редко обращают внимание, но при ручных методах для умножения или деления n-значных чисел требуется время, пропорциональное n². Если речь идет об операциях над числами из тысяч цифр, то такие расходы будут нам не по карману. К счастью, имеются лучшие алгоритмы.Как можно быстро умножать?
Алгоритм быстрого умножения Тоома—Кука, описываемый Кнутом, зиждется на четырех основных идеях[31]. Вот первая из них. Пусть нам известен способ выполнения некоторой операции над исходными данными размера n за время T(n). Если эту операцию удастся разбить на r частей, выполнение каждой из которых займет менее чем T(n)/r шагов, то такое разбиение позволит улучшить общее время, если, конечно, считать, что вспомогательные организационные расходы не сведут экономию на нет. Пусть, далее, каждая из r частей есть применение того же алгоритма к исходным данным длины n/r и каждая часть может быть разбита аналогичным образом. Тогда можно продолжать это разбиение, пока мы не получим столь короткие исходные данные, что вычисления для них станут тривиальными и займут лишь небольшой фиксированный отрезок времени. Этот принцип разделяй и властвуй обычно дает выигрыш во времени работы алгоритма по крайней мере в log n раз; так, классический метод умножения требует времени n², и его можно свести к , что существенно лучше при больших n (не забывайте, что у обеих функций стоимости имеются постоянные множители).
Остальные три идеи касаются чисел и действий над многочленами. Во-первых, заметим, что, если число U имеет длину n битов и записывается в двоичном виде как
un−1un−2…u2u1u0,
причем n делится на r + 1, то U можно также записать в виде
Ur2rn/(r+1) + Ur−12(r−1)n/(r+1) + … + U12n/(r+1) + U0,
где каждое Ui есть блок из n/(r + 1) битов исходного представления U. Фактически U = U(2n/(r + 1)), где многочлен U(x) есть
Urxr + Ur−1xr−1 + … + U1x + U0.
Во-вторых, мы видим, что если U и V — два n-разрядных числа, записанных в виде такого многочлена, то их произведение W дается формулой
W = UV = U(2n/(r + 1))V(2n/(r + 1)) = W(2n/(r + 1))
и если бы мы смогли найти хотя бы коэффициенты W(х), то вычислить W по W было бы сравнительно просто; для этого понадобились бы только сдвиги, сложения и умножения чисел из n/r битов. В-третьих, к счастью, W(х) — многочлен степени 2r и его можно найти с помощью интерполяции его значений в точках 0, 1, 2, …, 2r−1, 2r. Эти значения равны просто U(0), V(0), U(1), V(1), …, U(2r), V(2r). Более того, для вычисления всех этих многочленов и интерполяции требуется умножать числа только из n/r битов. Представляется, что эти действия подпадают под принцип «разделяй и властвуй».
Алгоритм Тоома—Кука весьма сложен, поэтому мы не будем подробно объяснять его; за этим можно обратиться к книге Кнута. Все же необходимо сообщить основные идеи и обозначения. Длинные числа должны быть как-то представлены; будем писать [p, u] для обозначения числа u из p битов. Вероятно, внутреннее представление [p, u] будет некоторой разновидностью списка или цепочки. Кроме основного алгоритма нам понадобятся подпрограммы для сложения и вычитания длинных чисел (используйте стандартный ручной метод сложения слева направо), умножения длинного числа на короткое (небольшое) число, деления длинного числа на короткое, сдвига длинного числа путем приписывания нулей справа и для разбиения длинного числа [p, u] на более короткие длинные числа [p/(r + 1), ur], [p/(r + 1), ur−1], …, [p/(r + 1), u0], как описано выше. Кроме подпрограмм, работающих непосредственно с числами, алгоритм использует четыре стека для хранения промежуточных частичных результатов и несколько временных переменных, поэтому требуются подпрограммы для выполнения некоторых действий над стеком, а также подпрограммы для выделения и освобождения памяти под длинные числа. При написании всяческих вспомогательных подпрограмм черновой работы может оказаться предостаточно.
, что существенно лучше при больших n (не забывайте, что у обеих функций стоимости имеются постоянные множители).
Остальные три идеи касаются чисел и действий над многочленами. Во-первых, заметим, что, если число U имеет длину n битов и записывается в двоичном виде как
un−1un−2…u2u1u0,
причем n делится на r + 1, то U можно также записать в виде
Ur2rn/(r+1) + Ur−12(r−1)n/(r+1) + … + U12n/(r+1) + U0,
где каждое Ui есть блок из n/(r + 1) битов исходного представления U. Фактически U = U(2n/(r + 1)), где многочлен U(x) есть
Urxr + Ur−1xr−1 + … + U1x + U0.
Во-вторых, мы видим, что если U и V — два n-разрядных числа, записанных в виде такого многочлена, то их произведение W дается формулой
W = UV = U(2n/(r + 1))V(2n/(r + 1)) = W(2n/(r + 1))
и если бы мы смогли найти хотя бы коэффициенты W(х), то вычислить W по W было бы сравнительно просто; для этого понадобились бы только сдвиги, сложения и умножения чисел из n/r битов. В-третьих, к счастью, W(х) — многочлен степени 2r и его можно найти с помощью интерполяции его значений в точках 0, 1, 2, …, 2r−1, 2r. Эти значения равны просто U(0), V(0), U(1), V(1), …, U(2r), V(2r). Более того, для вычисления всех этих многочленов и интерполяции требуется умножать числа только из n/r битов. Представляется, что эти действия подпадают под принцип «разделяй и властвуй».
Алгоритм Тоома—Кука весьма сложен, поэтому мы не будем подробно объяснять его; за этим можно обратиться к книге Кнута. Все же необходимо сообщить основные идеи и обозначения. Длинные числа должны быть как-то представлены; будем писать [p, u] для обозначения числа u из p битов. Вероятно, внутреннее представление [p, u] будет некоторой разновидностью списка или цепочки. Кроме основного алгоритма нам понадобятся подпрограммы для сложения и вычитания длинных чисел (используйте стандартный ручной метод сложения слева направо), умножения длинного числа на короткое (небольшое) число, деления длинного числа на короткое, сдвига длинного числа путем приписывания нулей справа и для разбиения длинного числа [p, u] на более короткие длинные числа [p/(r + 1), ur], [p/(r + 1), ur−1], …, [p/(r + 1), u0], как описано выше. Кроме подпрограмм, работающих непосредственно с числами, алгоритм использует четыре стека для хранения промежуточных частичных результатов и несколько временных переменных, поэтому требуются подпрограммы для выполнения некоторых действий над стеком, а также подпрограммы для выделения и освобождения памяти под длинные числа. При написании всяческих вспомогательных подпрограмм черновой работы может оказаться предостаточно.
Алгоритм быстрого умножения Тоома—Кука
Исходными данными служат два положительных длинных числа [n, u] и [n, v]; результатом — их произведение [2n, uv]. Используются четыре стека U, V, W и С, в которых при выполнении алгоритма будут храниться длинные числа, и пятый стек, содержащий коды временно приостановленных операций (имеется всего три кода, и для их представления можно воспользоваться малыми целыми числами). Массивы q и r целых чисел имеют индексы от 0 до 10; необходимо выделить память для этих двух массивов и для еще нескольких временных переменных, упомянутых в алгоритме. 1. (Начальная установка.) Сделать все стеки пустыми. Присвоить К значение 1, q0 и q1 — значение 16, r0 и r1 — значение 4, Q — значение 4 и R — значение 2. 2. (Построение таблицы размеров). Пока К < 10 и qK−1 + qK ≥ n, выполнять следующие вычисления. Изменить К на К + 1, Q — на Q + R; если (R + 1)² ≤ Q, то изменить R на R + 1; установить qK равным 2Q и rK равным 2R. Если цикл оканчивается из-за К = 10, то остановиться, выдав сообщение об ошибке — число битов n слишком велико, массивы q и r переполнились. В противном случае присвоить k значение K. Поместить [qK + qK−1, v] и за ним [qK−1 + qK, u] в стек С (вероятно, потребуется добавить к [n, u] и [n, v] слева нули). Поместить в управляющий стек код стоп. 3. (Главный внешний цикл.) Пока управляющий стек не пуст, выполнять шаги с 4-го по 18-й. Если на этом шаге управляющий стек окажется пустым, то остановиться с сообщением об ошибке; в управляющем стеке должен быть по крайней мере один элемент. 4. (Внутренний цикл разбиения и и v.) Пока к > 1, выполнять шаги с 5-го по 8-й. 5. (Установка параметров разбиения.) Установить k равным k − 1, s равным qk, t равным rk и р равным qk−1 + qk. 6. (Разбиение верхнего элемента стека С.) Длинное число [qk + qk+1, u] на вершине С следует рассматривать как t + 1 чисел длиной s битов каждое. Разбить [qk + qk+1, u] на длинные числа [s, Ut], [s, Ut−1], …, [s, U1], [s, U0]. Эти t + 1 чисел являются коэффициентами многочлена степени t, который следует вычислить в точках 0,1, …, 2t − 1, 2t no правилу Горнера. Для i = 0, 1, …, 2t − 1, 2t вычислить [р, Xi] по формуле (…([s, Ut]i + [s, Ut−1])i+ … + [s, U1])i + [s, U0] и сразу поместить [р, Xi] в стек U. Для выполнения умножений можно использовать подпрограмму умножения длинных чисел на короткие; никакой промежуточный или окончательный результат не потребует более p битов. Удалить [qk + qk+1, u] из стека С. 7. (Продолжение разбиения.) Выполнить над числом [m, v], находящимся сейчас на вершине стека С, ту же последовательность действий, что на шаге 6; полученные числа [p, Y0], …, [p, Y2t] поместить в стек V в порядке получения. Не забудьте удалить вершину стека С. 8. (Заполнение заново стека С.) Попеременно удалять (2t раз) вершины стеков V и U и помещать эти значения в стек С. В результате значения, вычисленные на шагах 6 и 7, будут помещены, чередуясь, в стек С в обратном порядке. После выполнения этого перемешивания верхняя часть стека С, рассматриваемая снизу вверх, будет иметь вид [р, Y2t], [p, X2t], …, [р, Y0], [p, Х0], на вершине будет [р, Х0]. Поместить в управляющий стек один код операции интерполировать и 2t кодов операции сохранять и вернуться к шагу 4. 9. (Подготовка к интерполяции.) Присвоить к значение 0. Выбрать два верхних элемента стека С и поместить их в обычные переменные и и v. Оба числа и и v будут состоять из 32 битов. Используя некоторую другую подпрограмму умножения, вычислить [64, w] = [64, uv]. Это умножение можно выполнить аппаратно или с помощью подпрограммы, как вы найдете нужным. 10. (Интерполяция при необходимости.) Выбрать вершину управляющего стека в переменную А. Если значение А есть интерполировать, то выполнить шаги с 11-го по 16-й, в противном случае перейти к шагу 17, 11. (Организация интерполяции.) Поместить [m, w] в стек W (это может быть значение, полученное на шаге 9 или 16). Присвоить s значение qk, t — значение rk, р — значение qk−1 + qk. Обозначим верхнюю часть стека W, рассматриваемую снизу вверх, как [2р, Z0], [2p, Z1], …, [2р, Z2t−1], [2p, Z2t], последнее из этих значений — на вершине стека. 12. (Внешний цикл деления Z.) Выполнять шаг 13 для i = 1, 2, …, 2t. 13. (Внутренний цикл деления Z.) Присвоить [2p, Zj] значение ([2р, Zj] − [2р, Zj−1])/i для j=2t, 2t − 1, …, i + 1, i. Все разности будут положительными, а все деления выполняются нацело, т. е. без остатка. 14. (Внешний цикл умножения Z.) Выполнять шаг 15 для i = 2t − 1, 2t − 2, …, 2, 1. 15. (Внутренний цикл умножения Z.) Заменить [2р, Zj] на [2p, Zj] − i[2p, Zj+1] для j = i, i + 1, …, 2t − 2, 2t − 1. Все разности будут положительными, и все результаты поместятся в 2р битов. 16. (Образование нового w и начало нового цикла.) Присвоить значение многочлена (… ([2р, Z2t]2s + [2p, Z2t−1]2s + … + [2p, Zi]2s + [2p, Z0] переменной [2(qk + qk+1), w]. Этот шаг можно выполнять, используя только сдвиги и сложения длинных чисел. Заметьте, что используется та же переменная [m, w], что и на шаге 9. Удалить [2р, Z2t], …, [2p, Z0] из стека W. Присвоить k значение k + 1 и вернуться к шагу 10. 17. (Проверка окончания.) Если А имеет значение стоп, то в переменной [m, w], уже вычисленной на шаге 9 или 16, находится результат алгоритма. В этом случае окончить работу. 18. (Сохранение значения.) Значением А должен быть код сохранить (если это не так, завершить алгоритм по ошибке). Присвоить k значение k + 1 и поместить [qk + qk−1, w] в стек W. Это значение w, только что вычисленное на шаге 9 или 16. Теперь вернуться к шагу 3.Комментарии к алгоритму Тоома—Кука
Мы почти не обосновывали и не объясняли алгоритм; вам придется кое в чем поверить на слово. Причина отсутствия объяснений кроется в том, что они крайне длинны и математичны, и у нас просто не хватило бы места. Изложение алгоритма в большой степени опирается на монографию Кнута; если вы хотите ознакомиться с алгоритмом подробнее, обратитесь к этой книге. Мы все же дадим некоторые комментарии, возможно способствующие лучшему пониманию. 1. (Структура алгоритма.) Наша версия алгоритма отличается от описанной у Кнута в основном структурой циклов. На рис. 22.1 представлена общая схема верхнего уровня алгоритма Тоома—Кука[32]. Рисунок 22.1. Управляющая схема алгоритма Тоома—Кука.
2. (Таблицы размеров.) Значения массивов, вычисленные на шаге 2, показаны в табл. 22.1; число в колонке nk равно наибольшему числу битов, которое может быть обработано алгоритмом при K = k. Очевидно, что предельное значение 10 для K не является очень серьезным ограничением. При желании этот предел можно повысить.
Рисунок 22.1. Управляющая схема алгоритма Тоома—Кука.
2. (Таблицы размеров.) Значения массивов, вычисленные на шаге 2, показаны в табл. 22.1; число в колонке nk равно наибольшему числу битов, которое может быть обработано алгоритмом при K = k. Очевидно, что предельное значение 10 для K не является очень серьезным ограничением. При желании этот предел можно повысить.
 3. (Глубина стеков в первом цикле.) Максимальная глубина стеков U и V на шагах с 5-го по 8-й равна 2(rK−1 + 1). Глубина стека С может возрастать до
3. (Глубина стеков в первом цикле.) Максимальная глубина стеков U и V на шагах с 5-го по 8-й равна 2(rK−1 + 1). Глубина стека С может возрастать до  .
4. (Глубина стеков во втором цикле.) Общая глубина стека W может достигать
.
4. (Глубина стеков во втором цикле.) Общая глубина стека W может достигать 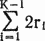 . Управляющий стек может достигать глубины
. Управляющий стек может достигать глубины  . На шагах 14, 15 и 16 верхняя часть стека W используется как массив. Этот массив может содержать максимум 2rk−1 + 2 элементов.
5. (Размер исходных данных.) Для любого числа битов n в диапазоне ni−1 + 1 ≤ n ≤ ni алгоритм Тоома—Кука требует одинакового времени вычислений. Таким образом, сложность вычислений весьма негладко зависит от размера исходных данных. Поэтому при выполнении длинных вычислений имеет смысл подбирать число битов вблизи верхнего конца одного из диапазонов для n. Учитывайте, что для представления одной десятичной цифры требуется примерно 3⅓ бита.
6. (Как умножить два 32-разрядных числа?) На шаге 9 требуется умножить два 32-разрядных числа, получив 64-разрядное произведение, причем оба сомножителя обязательно положительны. На многих ЭВМ имеется аппаратная возможность такого умножения, но результат нельзя получить, пользуясь языками высокого уровня. Ну и, конечно, некоторые ЭВМ не имеют подобней аппаратуры. Поэтому для выполнения этого умножения нужно написать подпрограмму, причем она должна быть эффективной, поскольку время работы алгоритма определяется главным образом временем умножения 32-разрядных чисел. Вероятно, достаточно хорошим методом будет разбиение чисел на части и моделирование ручного способа умножения. Тем не менее если нужно получить произведение uv и число и записано в виде u1·216 + u0, a v — в виде v1·216 + v0, то произведением будет
(232 + 216)u1v1 + 216(u1 − u0)(v0 − v1) + (216 + 1)u0v0.
Вычисление по этой формуле выполняется при помощи только 16-битовых вычитаний и умножений, а также некоторых сдвигов и сложений. Обратите внимание, что одно умножение сэкономлено.
. На шагах 14, 15 и 16 верхняя часть стека W используется как массив. Этот массив может содержать максимум 2rk−1 + 2 элементов.
5. (Размер исходных данных.) Для любого числа битов n в диапазоне ni−1 + 1 ≤ n ≤ ni алгоритм Тоома—Кука требует одинакового времени вычислений. Таким образом, сложность вычислений весьма негладко зависит от размера исходных данных. Поэтому при выполнении длинных вычислений имеет смысл подбирать число битов вблизи верхнего конца одного из диапазонов для n. Учитывайте, что для представления одной десятичной цифры требуется примерно 3⅓ бита.
6. (Как умножить два 32-разрядных числа?) На шаге 9 требуется умножить два 32-разрядных числа, получив 64-разрядное произведение, причем оба сомножителя обязательно положительны. На многих ЭВМ имеется аппаратная возможность такого умножения, но результат нельзя получить, пользуясь языками высокого уровня. Ну и, конечно, некоторые ЭВМ не имеют подобней аппаратуры. Поэтому для выполнения этого умножения нужно написать подпрограмму, причем она должна быть эффективной, поскольку время работы алгоритма определяется главным образом временем умножения 32-разрядных чисел. Вероятно, достаточно хорошим методом будет разбиение чисел на части и моделирование ручного способа умножения. Тем не менее если нужно получить произведение uv и число и записано в виде u1·216 + u0, a v — в виде v1·216 + v0, то произведением будет
(232 + 216)u1v1 + 216(u1 − u0)(v0 − v1) + (216 + 1)u0v0.
Вычисление по этой формуле выполняется при помощи только 16-битовых вычитаний и умножений, а также некоторых сдвигов и сложений. Обратите внимание, что одно умножение сэкономлено.
Что можно сказать относительно деления?
При вычислении предложенных рядов наряду с умножением используется деление чисел высокой точности. К счастью, при помощи алгоритма умножения удается выполнять деление почти так же быстро, как умножение. Для нахождения частного нужно приблизительно угадать число, обратное к делителю, скорректировать его, чтобы обратное стало точным, и затем умножить на делимое. Уточнение обратного осуществляется по методу Ньютона. Даны два числа [m, u] и [n, v]; мы считаем, что u ≥ v (хотя это предположение несущественно) и что n-й бит v равен 1 (т. е. у v нет старших нулей). Чем больше разница размеров и и v, тем более точным будет частное; разницу можно увеличить, умножая и на степень двойки. Отметим, что алгоритм деления будет неоднократно вызывать алгоритм умножения. Для нескольких первых из этих умножений можно воспользоваться обычной операцией умножения коротких чисел. Кроме того, все умножения и деления на степень двойки суть фактически сдвиги влево и вправо. 1. (Выбор размера обратного.) Найти наименьшее j, такое, что 2j ≥ max (m, 2n). Присвоить к значение 2j−1. 2. (Нормализация v.) Присвоить [k, v] значение 2k−n [n, v]. На этом шаге мы сдвигаем v влево, чтобы оно заняло k битов, причем левый бит был бы равен 1. Присвоить [2, а] значение [2, 2]. 3. (Вычисление последовательных приближений к 1/v.) Выполнить шаг 4 для i = 1, 2, …, j − 1. 4. (Вычисление приближения из 2i битов.) Присвоить [2i+1, d] значение 23·2i [2i−1 + 1, a] − [2i−1 + 1, a]2 ([k, v]/2k−2i) Деление в скобках (фактически сдвиг вправо) должно выполняться до умножения; идея состоит в том, чтобы ускорить умножение, отбросив лишние биты v, ненужные в данном приближения. Хотя кажется, что результат d может содержать больше 2i+1 битов, этого никогда не произойдет. Затем присвоить [2i + 1, а] значение [2i+1, d]/2i−1. 5. (Улучшение окончательной оценки.) Присвоить [3k, d] значение 22k[k + 1, а] − [k + 1, а]2·[k, v]. Затем присвоить [k + 1, а] значение ([Зk, d] + 22k−2)/22k−1. 6. (Окончательное деление.) Выдать в качестве результата ([k + 1, a] · [m, u] + 2k+n−2)/22+k−1[33].Как использовать алгоритмы?
Для нахождения π надо будет провести вычисления по одной из формул, выписанных ранее в этом пункте, с использованием ряда для арктангенса. Фактически для страховки следует использовать две формулы и затем сравнить результаты бит за битом. Значением π будет общая начальная часть этих двух результатов. Все еще остается открытым вопрос, как с помощью алгоритмов, работающих только с целыми числами, получить очевидно дробные значения членов ряда. Пусть мы хотим вычислить я, скажем, с точностью 1000 битов. Вычислим тогда 21000π, умножив все числители на 21000. Эта процедура делает также все делимые много больше делителей (как предполагалось выше) и позволяет прекратить вычисления, когда частные станут нулевыми. Выберем теперь (не обязательно наилучший) ряд для вычислений, скажем π = 16 arctg(1/5) − 4 arctg(1/239). Мы фактически будем вычислять 21000π, поэтому хотелось бы вычислить 21000·16 arctg (1/5). Первым членом соответствующего ряда будет 21000·16/5; назовем его a1 (отметим, что a1 складывается с суммой). Теперь, чтобы получить следующий член ai+1 из ai, поделим a1 на 5·5·(2i − 1)[34]. Если ai добавлялся к сумме, то вычтем ai+1 из суммы, если ai вычитался, прибавим ai+i. Будем поделим a1 на 5·5·(2i − 1). Если ai добавлялся к сумме, то вычисления заканчиваются, когда члены обоих рядов станут нулевыми. В результате получим примерно тысячу битов числа π. Результат, конечно, надо будет перевести в десятичную систему. Тема. Составьте программы, реализующие описанные выше алгоритмы умножения и деления, и все необходимые им служебные подпрограммы. Используйте их для вычисления я с высокой точностью при помощи одного из выписанных рядов. Проследите, чтобы ваши программы не оказались слишком тесно привязаны к вычислению π; библиотека программ для вычислений с высокой точностью может быть полезна и для других задач. Должна быть предусмотрена возможность увеличения точности счета без изменения программ, а лишь путем расширения памяти для результатов. Выходные данные должны включать статистику по использованию каждой программы, по числу выполнений каждого шага двух центральных алгоритмов и по использованию памяти. Сбор такой информации обойдется очень дешево в сравнении со всей работой. Указания исполнителю. Этот этюд длинный и трудный. Не последнюю роль здесь играет то, что два центральных алгоритма нужно в какой-то степени принимать на веру. Однако, как это часто бывает в реальных задачах, главной проблемой является не кодирование программы, а выбор структур данных. Как представлять длинные числа? Обозначение [m, u] наводит на мысль, что всякое длинное число представляется парой аргументов длина и значение. Часть длина легко реализуется, но значение имеет, очевидно, переменную длину, и его трудно будет непосредственно хранить в памяти. Поэтому мысделаем значение указателем на очень длинный вектор битов; тогда каждая пара будет иметь фиксированный размер. Однако имеющийся в нашем распоряжении вектор не настолько длинен, чтобы мы могли позволить себе использовать каждую его часть только по одному разу. Таким образом, нужна программа для сбора ненужной памяти. Сейчас мы фактически описали традиционную схему размещения цепочек. Итак, в конечном итоге нам нужны кроме алгоритма умножения и деления следующие вспомогательные подпрограммы: Выделение памяти. Получая величину длина в качестве аргумента, эта подпрограмма возвращает указатель в вектор битов, который может использоваться как значение. Начиная с бита, на который указывает значение, расположено длина битов, которые не будут использоваться ни для каких других целей. Возврат памяти. Исходными данными для этой подпрограммы служит пара длина и значение. Связанная с ними память освобождается для повторного использования. Эту подпрограмму необходимо вызывать всякий раз, когда длина какой-либо переменной меняется. Уплотнение памяти. Эта подпрограмма должна просмотреть всю используемую память и попытаться объединить неиспользуемые отрезки вектора битов в более длинные отрезки. Обычно подпрограмма уплотнения вызывается в тех случаях, когда подпрограмма выделения памяти не смогла найти достаточно длинную цепочку последовательных битов. Поскольку такая возможность может не потребоваться при решении коротких задач, эту подпрограмму можно запрограммировать позднее. Существует много способов хранения информации о неиспользуемой памяти. Сдвиг. Исходными данными для подпрограммы служат длинное число и величина сдвига; результатом должно быть длинное число, сдвинутое вправо или влево на соответствующую величину. Эта операция отвечает умножению или делению на степень двойки. Сложение. Исходными данными подпрограммы служат два длинных числа, а результатом должна быть их сумма в виде числа на один бит длиннее более длинного из операндов. Такое сложение можно выполнять так же, как вручную, двигаясь справа налево. Вычитание. Эта подпрограмма аналогична подпрограмме сложения и выдает разность двух длинных чисел. Подавление нулей. Исходными данными этой подпрограммы служит длинное число, а результатом должно быть более короткое длинное число, имеющее то же значение, но без старших нулей. Если окажется, что исходное число равно нулю, то результатом должно быть [1, 0]. Короткое умножение. Исходными данными служат два длинных числа длиной точно 32 бита; результатом должно быть их 64-разрядное произведение. Эту операцию можно выполнять справа налево, как в ручном методе. Умножение длинного на короткое. Исходными данными служат длинное число и обычное число, по величине равное 64 или меньше; результатом должно быть их произведение в виде длинного числа. Эту операцию можно выполнять справа налево, как вручную. Деление длинного на короткое. Исходными данными служат длинное число и обычное число, не превосходящее 64, а результатом должно быть длинное частное от деления длинного числа на короткое. Эту операцию можно выполнять слева направо, как это делается вручную. Перевод. Исходными данными для этой подпрограммы является длинное число, а результатом должно быть то же число, записанное в десятичной системе на некотором устройстве вывода. При появлении потребности в более сложном выводе можно разработать более детальные спецификации подпрограммы перевода. Инструментовка. В качестве языка реализации сразу же приходит на ум Паскаль: в этом языке хорошие структуры данных и управляющие структуры. Однако Паскаль не позволяет легко переводить внутреннее битовое представление в битовые цепочки, доступные программисту, и обратно. Языки более низкого уровня — BLISS и XPL — обеспечивают более прямой доступ к ЭВМ за счет некоторой потери выразительности и надежности. Хорошая защищенность языков высокого уровня и доступ к машинному представлению сочетаются в PL/I, но обычно за это приходится расплачиваться временем выполнения. Для данного этюда важно также время, которое вы потеряете, пытаясь постичь некоторые весьма изощренные возможности PL/I. Интересной представляется реализация на Траке, поскольку в этом случае автоматически решается задача распределения памяти для цепочек. Длительность исполнения. Одному исполнителю на 5 недель или двум на 3 недели. Развитие темы. Как только у нас появляется арифметика высокой точности, сразу же возникает много интересных задач. Одна из них — точное вычисление числа e. Ряд для e особенно прост: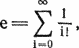 где 0! = 1. Любой студент, изучающий математический анализ, может придумать еще очень много рядов и констант.
* Партия переводчика. Можно существенно сократить как время работы программ, так и время их написания, если, не послушавшись автора, создать набор специализированных программ для вычисления π. Анализируя ряд для π, мы видим, что его вычисление требует всего двух программ высокой точности. Это программа сложения-вычитания длинных чисел (сложение и вычитание настолько похожи, что их можно рассматривать как одно действие) и программа деления длинного числа на короткое, т. е. на представимое в виде обычного целого числа. Эти действия, выполняемые классическими ручными методами, занимают лишь линейное по n время.
Кроме того, имеет смысл хранить длинные числа не в двоичной системе счисления, а в десятичной (конечно, не по одной цифре в элементе массива, а по столько цифр, сколько помещается в обычном целом числе). При этом отпадает необходимость в программе перевода. Теперь арифметические программы могут работать несколько медленнее (но вовсе не обязательно; далеко не все компиляторы используют команды сдвига для умножения и деления на степени двойки), тем не менее в целом можно получить выигрыш в скорости, поскольку время работы алгоритма перевода длинных чисел из двоичной системы в десятичную (описанного у Кнута) пропорционально n², т. е. того же порядка, что и время всех остальных вычислений.
С помощью лишь этих программ сложения и деления можно вычислить многие математические константы: π, e, √2, ∛2, ln 2 и т. д. Реализация такого усеченного варианта потребует, вероятно, не более одной человеко-недели. Сложные динамические структуры данных уже не потребуются; у нас будет всего два-три длинных числа известного размера, для представления которых вполне подойдут массивы Фортрана.
где 0! = 1. Любой студент, изучающий математический анализ, может придумать еще очень много рядов и констант.
* Партия переводчика. Можно существенно сократить как время работы программ, так и время их написания, если, не послушавшись автора, создать набор специализированных программ для вычисления π. Анализируя ряд для π, мы видим, что его вычисление требует всего двух программ высокой точности. Это программа сложения-вычитания длинных чисел (сложение и вычитание настолько похожи, что их можно рассматривать как одно действие) и программа деления длинного числа на короткое, т. е. на представимое в виде обычного целого числа. Эти действия, выполняемые классическими ручными методами, занимают лишь линейное по n время.
Кроме того, имеет смысл хранить длинные числа не в двоичной системе счисления, а в десятичной (конечно, не по одной цифре в элементе массива, а по столько цифр, сколько помещается в обычном целом числе). При этом отпадает необходимость в программе перевода. Теперь арифметические программы могут работать несколько медленнее (но вовсе не обязательно; далеко не все компиляторы используют команды сдвига для умножения и деления на степени двойки), тем не менее в целом можно получить выигрыш в скорости, поскольку время работы алгоритма перевода длинных чисел из двоичной системы в десятичную (описанного у Кнута) пропорционально n², т. е. того же порядка, что и время всех остальных вычислений.
С помощью лишь этих программ сложения и деления можно вычислить многие математические константы: π, e, √2, ∛2, ln 2 и т. д. Реализация такого усеченного варианта потребует, вероятно, не более одной человеко-недели. Сложные динамические структуры данных уже не потребуются; у нас будет всего два-три длинных числа известного размера, для представления которых вполне подойдут массивы Фортрана.
Литература
Ахо, Хопкрофт, Ульман (Aha А. V., Haperoft J. E., Ullman J. D.). The Design and Analysis of Computer Algorithms. Addison-Wesley, Reading, MA, 1974. Section 8.2, pp. 279–286. [Имеется перевод: Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. — М.: Мир, 1979, § 8.2, с. 313–320.] Мы почерпнули алгоритм умножения у Кнута, а алгоритм деления — у Ахо, Хопкрофта и Ульмана; оба алгоритма переработаны для наших целей Эти книги содержат подробную информацию по основам и детальный анализ алгоритмов, включая оценки сложности. Описываются также альтернативные алгоритмы умножения, основанные на быстром преобразовании Фурье[35]. Брент (Brent R. P.). A FORTRAN Multiple-Precision Arithmetic Package, Department of Computer Science, Carnegie-Mellon University, May 1976. Брент описывает пакет подпрограмм для арифметических действий с высокой точностью, написанных на переносимом, машинно-независимом Фортране. Благодаря включенной в книгу библиографии, вы сможете найти другие работы в этой области. В пакете, предложенном Брентом, не используется алгоритм Тоома—Кука, и автор объясняет почему. Брент (Brent R. P.). Fast Multiple-precision Evaluation of Elementary Functions, Stanford University, Technical Report STAN-CS-75-515, August 1975. Томас (Thomas G. В., Jr.). Calculus and Analytic Geometry, 3rd ed. Addison-Wesley, Reading, MA, 1960. Section 16.3—3, pp. 809–812. Томас приводит сведения по математическому анализу, необходимые для рассмотренных нами вычислений и подобных им; изложение в его книге простое и классическое. Рейтуиснер, а также Шенкс и Ренч — два примера из ряда работ по вычислению π. В обеих работах дается некоторый исторический обзор, обе они используют подход, предлагаемый Томасом. Брент развивает совершенно новые методы вычисления функций sin, cos, log, arctg и т. д., основанные на эллиптических интегралах. Его алгоритмы работают значительно быстрее описанных нами рядов. Работа Брента пока существует в виде технического доклада. Кнут (Knuth D. E.). The Art of Computer Programming/Seminumerical Algorithms, Addison-Wesley, Reading, MA, 1969. Section 4.3.3, pp. 258–280. [Имеется перевод: Кнут Д. Искусство программирования для ЭВМ. Т. 2. Получисленные алгоритмы. — М.: Мир, 1977, п. 4.3.3., стр. 314–340[36].] Рейтуиснер (Reitwiesner G. W.). An ENIAC Determination of π and e to More than 2000 Decimal Places, Mathematical Tables and Aids to Computation, 4, pp. 11–15, 1950. Шенкс, Ренч (Shanks D., Wrench J. W.). Calculation of π to 100 000 Decimals, Mathematics of Computation, 16, pp. 76–99, 1962. *Кудрявцев Л. Д. Математический анализ. — М.: Высшая школа, 1973.23. Великий комбинатор, или Оптимальные стратегии для игры с угадыванием
В игре, как и в музыкальном произведении, можно выделить тему и мотивы. Причина успеха самых удачных игр часто состоит в том, что они мастерски соединяют по-новому некоторые из давно известных принципов построения игр. Как и в музыке, старая идея, возрожденная в новом обличье, может выглядеть привлекательней, чем мешанина свежеиспеченных новых веяний. В середине 70-х годов широкую популярность в Англии получила игра великий комбинатор (Mastermind)[37], и она, похоже, станет классикой. Вы и ваш компьютер получите большое удовольствие, сыграв в нее. Правила великого комбинатора крайне просты. Один из игроков, загадывающий, записывает секретную комбинацию из любых четырех цифр от 1 до 6 (повторения допускаются), называемую кодом. Второй игрок, отгадывающий, пытается раскрыть код, высказывая разумные предположения, называемые пробами. Каждая проба, как и код, представляет собой произвольную комбинацию из четырех цифр в диапазоне от 1 до 6. Отгадывающий игрок сообщает пробу загадывающему, и тот должен ответить, сколько цифр в пробе совпадает с цифрами кода как по положению, так и по величине и сколько из остальных цифр пробы входят в код, но стоят на другом месте. Так, на пробу 1123 при коде 4221 будет получен ответ: «Одна цифра совпадает и стоит на том же месте, и еще одна совпадает, но стоит на другом месте». Тур игры продолжается до тех пор, пока отгадывающий не назовет пробу, в точности совпадающую с кодом, т. е. пока не отгадает код. После этого игроки меняются ролями и проводят еще один тур. Победителем считается тот из игроков, кто определит код противника за меньшее число проб. Хотя здесь не последнюю роль играет везенье, тем не менее игрок, систематически делающий правильные умозаключения из получаемой информации, должен иметь лучшие результаты по итогам нескольких партий. Практически вы должны пытаться выводить из ответов на ваши пробы отрицательные следствия относительно того, какие коды невозможны; психологические тесты показывают, что для многих людей это оказывается совсем не просто. В табл. 23.1 приведен один полный тур. Написать программу, имитирующую роль загадывающего, не составляет труда. Отгадывание головоломок, заданных машиной, — тоже развлечение, позволяющее отточить ум. Однако гораздо интереснее, если компьютер сможет выступать также и в роли отгадывающего, чтобы можно было сыграть несколько партий и определить победителя. Боб Кули из Lawrence Livermore Laboratory и Д. Кнут разработали довольно близкие стратегии, позволяющие ЭВМ достигнуть высокого класса игры. Центральное место в обеих стратегиях занимает идея пространства решений. Начальное пространство решений Р0 состоит из всех возможных кодов (и имеет, следовательно, б4 элементов); после i-й пробы Gi пространство Pi состоит из всех тех членов пространства Pi−1, которые не опровергаются ответом Ri. Иными словами, пространство Pi — это множество всех комбинаций, которые все еще могут быть кодом; задача отгадывающего — свести пространство к одному элементу.
Первая стратегия, предложенная Кули, несколько проще. Пробой Gi пусть будет любая случайно выбранная комбинация с одной повторяющейся цифрой, например 4311, 6552 или 1335. Выполните эту пробу и постройте пространство Pi на основе ответа Ri. Новая проба Gi+1 ищется по пространству Рi, i ≥ 1, путем поочередного сравнения всех комбинаций С из Pi с пробой Gi. В качестве следующей пробы выбирается наименее похожая на Gi комбинация С. Мерой сходства служит число точных совпадений, а в случае равенства — число цифр, совпадающих по значению, но расположенных по-другому. Так, среди трех комбинаций 2641, 2356 и 1345 наиболее похожей на 2345 будет 1345, а 2641 — наименее похожей. Если имеется несколько наименее похожих комбинаций, то можно выбрать любую кандидатуру случайным образом. Тур прекращается, когда будет получен ответ «четыре точных попадания», и, разумеется, в случае пространства из одного элемента в качестве следующей пробы всегда надо брать этот элемент. Как показывают эксперименты, размеры пространства решений сокращаются после каждой пробы примерно в 4 раза и никогда не требуется более шести проб.
Вторая стратегия предложена Дональдом Кнутом. Он утверждает, что она минимизирует наибольшее число проб, необходимых для нахождения кода; никакой код не требует более пяти проб. В основе алгоритма лежит наблюдение, что нам хотелось бы сделать пространство Pi как можно меньше. Следовательно, мы выбираем пробу Gi, минимизирующую |Pi| по всем возможным ответам Ri. Кандидатом в Gi будет любая комбинация С. Попробуйте применить все возможные комбинации С в качестве проб к пространству Pi−1; пусть Sc, <0,0> обозначает число членов Pi−1, дающих в ответе нулевое число точных совпадений и нулевое Число совпадений только по цвету[38] Sc, <0,1> — число членов, дающих соответственно нуль и одно совпадение и т. д. до Sc, <4,0> для наиболее удачной комбинации с четырьмя точными совпадениями. Введем обозначение
Написать программу, имитирующую роль загадывающего, не составляет труда. Отгадывание головоломок, заданных машиной, — тоже развлечение, позволяющее отточить ум. Однако гораздо интереснее, если компьютер сможет выступать также и в роли отгадывающего, чтобы можно было сыграть несколько партий и определить победителя. Боб Кули из Lawrence Livermore Laboratory и Д. Кнут разработали довольно близкие стратегии, позволяющие ЭВМ достигнуть высокого класса игры. Центральное место в обеих стратегиях занимает идея пространства решений. Начальное пространство решений Р0 состоит из всех возможных кодов (и имеет, следовательно, б4 элементов); после i-й пробы Gi пространство Pi состоит из всех тех членов пространства Pi−1, которые не опровергаются ответом Ri. Иными словами, пространство Pi — это множество всех комбинаций, которые все еще могут быть кодом; задача отгадывающего — свести пространство к одному элементу.
Первая стратегия, предложенная Кули, несколько проще. Пробой Gi пусть будет любая случайно выбранная комбинация с одной повторяющейся цифрой, например 4311, 6552 или 1335. Выполните эту пробу и постройте пространство Pi на основе ответа Ri. Новая проба Gi+1 ищется по пространству Рi, i ≥ 1, путем поочередного сравнения всех комбинаций С из Pi с пробой Gi. В качестве следующей пробы выбирается наименее похожая на Gi комбинация С. Мерой сходства служит число точных совпадений, а в случае равенства — число цифр, совпадающих по значению, но расположенных по-другому. Так, среди трех комбинаций 2641, 2356 и 1345 наиболее похожей на 2345 будет 1345, а 2641 — наименее похожей. Если имеется несколько наименее похожих комбинаций, то можно выбрать любую кандидатуру случайным образом. Тур прекращается, когда будет получен ответ «четыре точных попадания», и, разумеется, в случае пространства из одного элемента в качестве следующей пробы всегда надо брать этот элемент. Как показывают эксперименты, размеры пространства решений сокращаются после каждой пробы примерно в 4 раза и никогда не требуется более шести проб.
Вторая стратегия предложена Дональдом Кнутом. Он утверждает, что она минимизирует наибольшее число проб, необходимых для нахождения кода; никакой код не требует более пяти проб. В основе алгоритма лежит наблюдение, что нам хотелось бы сделать пространство Pi как можно меньше. Следовательно, мы выбираем пробу Gi, минимизирующую |Pi| по всем возможным ответам Ri. Кандидатом в Gi будет любая комбинация С. Попробуйте применить все возможные комбинации С в качестве проб к пространству Pi−1; пусть Sc, <0,0> обозначает число членов Pi−1, дающих в ответе нулевое число точных совпадений и нулевое Число совпадений только по цвету[38] Sc, <0,1> — число членов, дающих соответственно нуль и одно совпадение и т. д. до Sc, <4,0> для наиболее удачной комбинации с четырьмя точными совпадениями. Введем обозначение
 Теперь в качестве пробы Gi выберите комбинацию С, минимизирующую Sc (при наличии нескольких таких С выберите комбинацию из Pi−1, если это возможно; если же нет — делайте случайный выбор). Вы, вероятно, уже заметили, что этот алгоритм можно использовать для предварительного анализа великого комбинатора, так чтобы в процессе игры не был нужен никакой анализ комбинаций. Проделав такой анализ, Кнут показал, что оптимальной первой пробой при использовании его стратегии будет ххуу, где х ≠ у. Для проверки своей программы посмотрите, начинает ли она с пробы ххуу.
Тема. Напишите программу, которая будет разыгрывать партии великого комбинатора. Реализуйте стратегию отгадывания, так чтобы машина могла загадывать коды и отгадывать их. Кроме собственно игры ваша программа может накапливать сведения о мастерстве разных игроков. Ваш местный великий комбинатор, возможно, пожелает приехать в Англию на очередной чемпионат. С вашей программой, как и другими игровыми программами, вероятно, будет иметь дело не слишком искушенный пользователь. Поэтому следует позаботиться о том, чтобы ввод данных был простым и естественным, а вывод понятным и красиво оформленным.
Рекомендации исполнителю. Единственная серьезная проблема в этом этюде связана с эффективностью при программировании алгоритма анализа — эффективностью как по памяти, так и по времени. Особенно длинный внутренний цикл требуется для второй стратегии. Заметьте, что комбинации суть не что иное, как числа, записанные по основанию 6 (но вместо цифр от 0 до 5 используются цифры от 1 до 6). Избранный вами язык, вероятно, повлияет на выбор представления, но старайтесь все же построить эффективный внутренний цикл для алгоритма угадывания кода.
Инструментовка. Для этой задачи пригоден почти любой процедурный язык с достаточно развитыми структурами данных. Эта программа в значительной мере — упражнение по структурному программированию.
Длительность исполнения. Одному исполнителю на 2 недели.
Развитие темы. Наиболее очевидное расширение — это изменение множества цифр, из которых составляется код, или количество цифр в коде. Более развитая версия великого комбинатора допускает коды из пяти цифр от 1 до 8. Слишком большое значение любого из двух параметров может привести к непомерному росту времени работы, однако ни один из алгоритмов не зависит сколько-нибудь существенно от чисел 6 и 4. Программа без всякого труда могла бы читать объем словаря (число различных цифр) и длину кода в качестве исходных данных и соответствующим образом изменять свои алгоритмы анализа.
Теперь в качестве пробы Gi выберите комбинацию С, минимизирующую Sc (при наличии нескольких таких С выберите комбинацию из Pi−1, если это возможно; если же нет — делайте случайный выбор). Вы, вероятно, уже заметили, что этот алгоритм можно использовать для предварительного анализа великого комбинатора, так чтобы в процессе игры не был нужен никакой анализ комбинаций. Проделав такой анализ, Кнут показал, что оптимальной первой пробой при использовании его стратегии будет ххуу, где х ≠ у. Для проверки своей программы посмотрите, начинает ли она с пробы ххуу.
Тема. Напишите программу, которая будет разыгрывать партии великого комбинатора. Реализуйте стратегию отгадывания, так чтобы машина могла загадывать коды и отгадывать их. Кроме собственно игры ваша программа может накапливать сведения о мастерстве разных игроков. Ваш местный великий комбинатор, возможно, пожелает приехать в Англию на очередной чемпионат. С вашей программой, как и другими игровыми программами, вероятно, будет иметь дело не слишком искушенный пользователь. Поэтому следует позаботиться о том, чтобы ввод данных был простым и естественным, а вывод понятным и красиво оформленным.
Рекомендации исполнителю. Единственная серьезная проблема в этом этюде связана с эффективностью при программировании алгоритма анализа — эффективностью как по памяти, так и по времени. Особенно длинный внутренний цикл требуется для второй стратегии. Заметьте, что комбинации суть не что иное, как числа, записанные по основанию 6 (но вместо цифр от 0 до 5 используются цифры от 1 до 6). Избранный вами язык, вероятно, повлияет на выбор представления, но старайтесь все же построить эффективный внутренний цикл для алгоритма угадывания кода.
Инструментовка. Для этой задачи пригоден почти любой процедурный язык с достаточно развитыми структурами данных. Эта программа в значительной мере — упражнение по структурному программированию.
Длительность исполнения. Одному исполнителю на 2 недели.
Развитие темы. Наиболее очевидное расширение — это изменение множества цифр, из которых составляется код, или количество цифр в коде. Более развитая версия великого комбинатора допускает коды из пяти цифр от 1 до 8. Слишком большое значение любого из двух параметров может привести к непомерному росту времени работы, однако ни один из алгоритмов не зависит сколько-нибудь существенно от чисел 6 и 4. Программа без всякого труда могла бы читать объем словаря (число различных цифр) и длину кода в качестве исходных данных и соответствующим образом изменять свои алгоритмы анализа.
Литература
Алеф0 (Aleph0). Computer Recreations, Software — Practice and Experience, 1, pp. 201–204, 1971. Mastermind. Invicta Plastics, Ltd. Oadby, Leicester, England. Описывается исходная игра. Она сильно похожа на некоторые традиционные игры; вся Англия увлечена этой игрой из-за ее простоты. Кнут (Knuth D. E.). The Computer as Master Mind. He опубликовано, 1976. Кнут утверждает, что путем исчерпывающего анализа различных случаев можно показать оптимальность его стратегии в указанном выше смысле. Однако останется ли она оптимальной при изменении объема словаря и длины кода? И какая стратегия будет оптимальной, если мы стремимся свести к минимуму ожидаемое число проб, а не максимальное? Таненбаум (Tanenbaum A. S). Computer Recreations: A Heuristic for Playing Jotto, Software — Practice and Experience, 3, pp. 397–399, 1973. В обеих статьях из журнала Software — Practice and Experience рассматриваются игры, аналогичные великому комбинатору; описываются реальные программы и предлагаются некоторые стратегии машинной игры. Было бы, наверное, очень интересно организовать турнир между различными эвристиками. Уэллс (Wells D.). Mastermind. Games and Puzzles, 23, pp. 10–11, March/April 1974. Games and Puzzles — широко известный английский журнал, посвященный играм, головоломкам и всевозможным интеллектуальным развлечениям. По стилю он далек от математического издания: в нем вы скорее найдете исторический, тематический, эстетический и стратегический разбор абсолютно любого приятного времяпрепровождения (ну, почти любого), не требующего ничего, кроме обыкновенного стола. Постоянно публикуются новые и старые игры. А из головоломок вы почерпнете немало глубоких алгоритмических проблем. Короче говоря, это весьма ценное приобретение для любителей убить время.24. Секрет фирмы, или Математический подход к раскрытию шифров
Представьте себе такую ситуацию. Благодаря выдающимся профессиональным познаниям и незаурядным программистским способностям вас выдвинули на должность руководителя большой группы сотрудников, занимающихся разработкой суперновейшего и пока еще секретного Мини-компилятора для ЭВМ УМ-1 (см. гл. 27 и 25). Как-то раз, уходя со службы около часу ночи (руководитель должен подавать хороший пример), вы замечаете торчащий в дверях измятый клочок бумаги (содержание которого воспроизведено на рис. 24.1). Сначала вы решаете, что это запись содержимого памяти машины, и уже собираетесь выбросить бумажку. Но, присмотревшись повнимательнее, замечаете, что буквы собраны в группы по пять, — очень странно для УМ-1. Что бы это могло быть?ЖНФЖП ЕЕЫШВ ЛПЖАТ ГФБЦМ КЖЬЗА ЮЪИВУ ЩЖРСЮ БЬЬКЬ ЫЕСУУ ЦТЮБШ УНЭДДО ЭЭШЮЗ УЬЕКН АУЕЫЩ ШЖРЬЙ ЛЮПКН ДЙЯГЭ ЪНЫГЖ ОУШИШ УФГБР ШМАГВ ВУВОС ЗХЧИУ ГНЛАЯ ЬЬКИЯ РЦЖРЫ АХЪБИ ЖГЭЯЦ СЪУЫФ ЯРМЭФ ЧФЬЩС ЬФШВЕ ОМКТИ МБЭВЪ КФХЙЦ ХНЪЮЪ МФЛБИ МРУЛМ ЯЗФЧЪ ЪЧЗНК ЗНИВЯ НШГЛЩ ИЛЗНФ ФУЖКН ДЙЯГЭ ЕУЮЛЛ ЮЖНЯИ ЕМДЙШ ГЯУГВ ЦФЩВЮ МФАГЯ ВХМЭВ ВФПГФ ФЖККГ ЦМЛЫБ ШМПУЕ ШЖЯЯЮ ЯРЧВЪ ЖУПВМ КЛЫЭС ЭЧИРЫ ГЫЩЗЗ ЗКЖЛЕ ШВРЪЧ ЪААЖЗ ДХЪФС БРНМЪ КЫБЪФ УНЦЮБ ТЖУНЯ ЕШИМУ КФВГВ ГЧМЗВ ЗРВМЪ ЪЕЕТО ЯЦБЖГ ВИЖМД КЗЗПА ФЯВНР ЫГЮЩЭ ЯЫДОЪ ЧНГВЫ АХЪВЛ НШАПВ ЧОЬОЙ КЮАШО КЗЛЩУ ШЯРНЗ ГХЛТЮ ЖЫШШГ ППЬЫШ АЬФМА ФЕЙЗА ЙШЕУЭ ЖЛЗИЗ НЖККР ЦЯДЧК НДЙЯГ ЭБФЬА ВБЭКЗ ФКЫТВ ЛЕЪЭЯ ЛЭЩЗН ФХГЧК ТКЫЮЗ ЗЪУЖА ПВЧОЬ ОЙКЕС ЛЗАЮЪ ИВУНЫ БКЗВЯ ЪГОСЩ ЛБЬГМ ЯВЗГЬ КШЪГЙ ЕНПСМ ЭВГОГ ЧСОРГ ЩОЦМВ ДГЩКЧ ЮЗВЗК ЦЧЯРЧ ВЪЖФЫ ЕЛЖАЪ УССХР УОЬЫЕ ЙГЫОТ УЕАГЖ ГЫСЩИ ЯРВТЮ ДЖНЛГ ЦМЗЬЪ ЯИЦТР ЕМИКЦ ЩВЦОР ЛХМХЖ БРЬПУ ГВЯРЬ ПМЯЖЖ РЧПШЪ ЧУВГЧ СЕЕГЦ ЬПЗДМ ОЬОЧЗ КВУФЯ УПОХЪ ГЪЭЯЖ ВЖФ
Рисунок 24.1. Таинственная записка, найденная в вычислительном центре. Случайное вкрапление русских слов, например ШИШ или ОЙ, по-видимому, ничего не означает. Но обратите внимание на повторение сочетаний ЗАЮЪИВУ, ЬЬК, других коротких сочетаний, а особенно на повторяющуюся группу букв КНДЙЯГЭ.
Снова возвращаетесь в свой кабинет, пытаясь решить загадку. Бумага отменная, слегка пахнет мускусом; почерк явно женский и веет от него этаким французским шармом. Теперь, по здравом размышлении, новая сотрудница мисс Хари начинает казаться вам, пожалуй, немножко слишком экзотичной. Ее французский акцент, неизменное черное платье для коктейля, нитка черного жемчуга, подчеркивающая декольте, и этот будоражащий запах мускуса, наполняющий комнату, когда она туда входит… Она говорит, что работала раньше в региональном вычислительном центре Мак-Дональда в Киокаке. Что-то тут не так. Подождите… Неужели мисс Хари шпионит в пользу знаменитой французской фирмы И Бей Эм? А эта записка — шифровка, в которой все секреты вашего новейшего чудо-компилятора? Чтобы уличить мисс Хари, записку нужно расшифровать. Но как? Может, обратимся за помощью к компьютеру?
Основы шифрования
ЭВМ, безусловно, может оказать помощь, иначе Управление национальной безопасности просто пускает на ветер деньги налогоплательщиков, закупая такое количество техники. Для начала необходимо как следует присмотреться к секретному сообщению. Возможно, что найденная записка была зашифрована при помощи простой подстановки, т. е. каждая буква первоначального текста была заменена какой-либо другой буквой согласно некоторому правилу шифрования. Сообщение, подвергшееся зашифровке, называется исходным текстом, а в результате получается шифрованный текст. Задача состоит в том, чтобы восстановить исходный текст и правило шифрования (последнее нужно лишь в том случае, если могут появиться другие сообщения, зашифрованные по тому же правилу). Будем предполагать, что исходный текст написан по-русски[39]. Разбиение шифрованного текста на группы по пять букв скрывает, по-видимому, исходную структуру текста, разбитого на слова, которая была бы весьма ценной подсказкой, облегчающей расшифровку[40]. В простейшем общем классе подстановочных шифров для построения правила шифрования используется некоторый смешанный алфавит, например перестановка обычного алфавита. На рис. 24.2 показан полный исходный алфавит, смешанный алфавит и шифрование короткого сообщения, в котором каждая буква заменяется соответствующей буквой смешанного алфавита. Всякий, кто увлекается головоломками из воскресных газет, знает, что зашифрованные такой подстановкой тексты расшифровываются до смешного просто: сообщения из 30 или 40 букв зачастую оказывается для этого вполне достаточно. Тем не менее слегка усовершенствовав эту систему, можно сделать ее значительно более надежной.АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
ЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕР
ПОПРОБУЙТЕ ПРОЧИТАТЬ КРИПТОГРАММУ ТОЧКА
ЪПЪЫПУОГЮЯ ЪЫПТКЮЗЮХ ЛЫКЪЮПВЫЗММО ЮПТЛЗ
Рисунок 24.2. Простая подстановка по смешанному алфавиту. Обратите внимание, что точка заменена словом ТОЧКА.
На рис. 24.3 изображен квадрат Виженера, построенный на основе смешанного алфавита, приведенного на рис. 24.2. Сверху и по левому краю квадрата выписан исходный алфавит. В первой строке квадрата представлен смешанный алфавит. Во второй строке тот же алфавит циклически сдвинут на одну позицию, при этом первая буква переместилась в правый конец строки. Квадрат состоит из 32 смешанных алфавитов, полученных из одного смешанного алфавита, каждому из них соответствует та буква исходного алфавита, которая записана слева от него. На рис. 24.4 показано шифрование фразы при помощи ключевого слова ЛИСП и данного квадрата. Ключевое слово многократно записывается под исходным текстом, и каждая буква исходного текста шифруется при помощи смешанного алфавита, соответствующего той букве ключевого слова, которая стоит под данной буквой исходного текста. Эта схема шифрования уже не поддается раскрытию при помощи простого подсчета частот букв, поскольку одна и та же буква исходного текста шифруется по-разному в зависимости от выпавшей на нее буквы ключевого слова. Кроме того, выбрав заранее список ключевых слов и порядок их смены, отправитель и получатель могут повысить секретность переписки, поскольку разным сообщениям будут соответствовать разные ключевые слова, благодаря чему затрудняется анализ, основанный на частотах букв. Тем не менее не так уж все это безнадежно.
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
А ЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕР
Б УШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗ
В ШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУ
Г ВЬЯЖЩКГЛФМДПЪЫШООСИЙТЧБАЭХЦЕРЗУШ
Д ЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВ
Е ЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬ
Ж ЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯ
3 ЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖ
И КГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩ
Й ГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩК
К ЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГ
Л ФМДПЪЬНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛ
М МДПЪЬНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФ
Н ДПЪЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМ
О ПЪЫЮООСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМД
П ЪЫНЮОСЙЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДП
Р ЫНЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪ
С НЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫ
Т ЮОСИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫН
У ОСИЙТЧБАЭХЦВРЗУШВЬЯЖЩКГЛФМДПЪЫНЮ
Ф СИЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮО
X ЦЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОС
Ц ЙТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИ
Ч ТЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙ
Ш ЧБАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТ
Щ БАЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧ
Ъ АЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБ
Ы ЭХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБА
Ь ХЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭ
Э ЦЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХ
Ю ЕРЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦ
Я РЗУШВЬЯЖЩКГЛФМДПЪЫНЮОСИЙТЧБАЭХЦЕ
Рисунок 24.3. Квадрат Виженера, построенный на основе смешанного алфавита, приведенного на рис. 24.2.
ПОПРОБУЙТЕ ПРОЧИТАТЬ КРИПТОГРАММУ ТОЧКА
ЛИСПЛИСПЛИ СПЛИСПЛИС ПЛИСПЛИСПЛИС ПЛИСП
АЙЗРЕГЬЧЦЦ ЗРЕРБУФАД БЭЫЗУБФУЪТСЬ УБРЭЪ
или
АЙЗРБ ГЬЧЦД ЗРБРБ УФАДБ ЭЫЗУБ ФУЪТС ЬУБРЭ Ъ
Рисунок 24.4. Шифрование при помощи квадрата Виженера. Обратите внимание на повторение сочетания РБ на расстоянии 8. Второе повторение этого сочетания на расстоянии 2 — ложное. Статистика языка проявляется даже на коротких примерах.
Как раскрыть шифр
Будем предполагать, что криптограмма мисс Хари получена при помощи квадрата Виженера, хотя бы по той причине, что он — ее соотечественник. Если наше предположение неверно, методы решения позволят обнаружить это. Если бы сообщение было зашифровано при помощи простой подстановки, то расшифровать его можно было бы, подсчитав количество появлений каждой буквы в шифрованном тексте, поделив это количество на длину сообщения и сравнив полученные величины с частотами букв русского алфавита, приведенными на рис. 24.5. Для сообщений такой длины, как наше, распределения частот, если выписать их в убывающем порядке, почти полностью совпадут, и, таким образом, для каждой буквы исходного текста откроется ее двойник в шифрованном тексте. Но для квадрата Виженера такой простой метод уже не сработает. Необходимо определить не только смешанный алфавит, но и ключевое слово; поскольку каждый из этих элементов искажен другим, то трудно даже догадаться, с какого конца начать.О .0940
А .0896
Е .0856
И .0739
Н .0662
Т .0611
Р .0561
С .0554
П .0421
М .0417
В .0400
Л .0358
К .0322
Л .0280
Я .0243
Ы .0225
Б .0197
3 .0193
У .0179
Г .0153
Ь .0125
Ч .0118
Й .0094
X .0093
Ц .0087
Ж .0064
Ю .0063
Щ .0048
Ф .0034
Э .0033
Ш .0032
Ъ .0002
Рисунок 24.5. Таблица частот букв русского алфавита. Получена по текстам нескольких препринтов, издававшихся в ИПМ АН СССР им. М. В. Келдыша.
Правильной отправной точкой будет нахождение длины ключевого слова. Обратите внимание, что в примере на рис. 24.4 первая, пятая, девятая, … буквы исходного текста зашифрованы при помощи одного и того же смешанного алфавита Л. Если рассматривать лишь каждую четвертую букву шифрованного текста, то получим распределение частот, подобное распределению для букв русского алфавита, поскольку буквы в этих позициях зашифрованы при помощи одного и того же смешанного алфавита, т. е. при помощи простой подстановки. Аналогично если взять каждую четвертую букву шифрованного текста, начиная со второй, третьей или четвертой позиции, то снова получим распределение частот как для букв русского алфавита. Существует способ измерить, насколько данное распределение частот подобно распределению букв алфавита. Рассмотрим индекс совпадения
 где fi — количество появлений i-й буквы, а N — общее число рассматриваемых букв. Если все буквы рассматриваемого подмножества текста зашифрованы при помощи одного алфавита, то этот индекс совпадения должен иметь значение больше 0.045 и, вероятно, меньше 0.065 (теоретическое значение равно 0.055). Исходя из этого, алгоритм определения длины ключевого слова будет таким.
Шаг 1. Для i от 1 до 20 предположить, что длина ключевого слова равна i, и выполнить шаги 2, 3, 4. Мы выбрали верхнюю границу равной 20 лишь для удобства. Разумеется, ключевое слово может быть и длиннее.
Шаг 2. Для j от 1 до i выполнить шаг 3. В этих двух шагах будут вычислены i различных значений НС.
Шаг 3. Построить распределение числа появления букв в позициях j, i + j, 2i + j, …, т. е. в каждой i-й цозиции, начиная с j-й позиции. По формуле, приведенной выше, вычислить ИСj для полученного распределения. В качестве N в этой формуле нужно использовать число букв в данном подмножестве текста, а не длину всего текста.
Шаг 4. Если все значения ИС1, ИС2, …, ИСi больше 0.045, то, вероятно, i кратно длине ключевого слова. Если только один из ИС меньше 0.045, то i также может быть кратно длине ключевого слова.
Проверить длину ключевого слова можно и другим способом. Найдите два места в шифрованном тексте, где две одинаковые буквы идут в том же порядке, например ЦМ в позициях 19 и 54 на рис. 24.1. Такое повторение могло произойти по двум разным причинам. Возможно, в соответствующих местах исходного текста были различные сочетания букв, которым отвечали разные части ключевого слова, и они случайно отобразились в одинаковые сочетания букв, либо в исходном тексте были повторения, которые попали на одинаковые части ключевого слова, и, таким образом, оказались зашифрованными дважды одним и тем же способом. Во втором случае расстояние между началами повторяющихся сочетаний букв должно быть кратно длине ключевого слова. К сожалению, невозможно определить, по какой из двух причин произошло повторение данного сочетания букв: случайное повторение пар букв в шифрованном тексте довольно частое явление. Но если в шифрованном тексте повторяются сочетания из трех или более букв, то вероятность того, что это повторение произошло случайно, а не в результате повторения ключа, очень мала (для сочетаний из четырех и более букв она практически нулевая). Таким образом, другой способ выявления длины ключевого слова — отыскать в шифрованном тексте все пары повторяющихся групп из трех и более букв и измерить расстояния между ними. Число, которое делит 90% или более из этих расстояний, — прекрасный претендент на роль длины ключевого слова. Данная проверка вместе с вычислением значений ИС однозначно определяет длину ключевого слова.
Предположим, нам удалось выяснить, что длина ключевого слова равна k. Тогда первоначальный шифрованный текст можно разбить на k групп G1, G2, …, Gk, где каждая группа начинается с позиции i, 1 ≤ i ≤ k, и содержит каждую k-ю букву текста, начиная с i-й буквы. Каждая из этих к групп была зашифрована при помощи только одного алфавита, т. е. при помощи простой подстановки. Остается в каждой группе для каждой шифрованной буквы определить ее эквивалент в исходном тексте. Но здесь у нас имеется хорошее подспорье. Если бы был известен алфавит, по которому была зашифрована какая-нибудь из групп, то алфавит, по которому была зашифрована любая другая группа, можно было бы найти путем циклического сдвига уже известного алфавита на некоторое число букв. С другой стороны, определить исходные эквиваленты букв было бы проще, если бы удалось распределения числа появлений букв для различных групп скомбинировать в одно обобщенное распределение, поскольку, чем больше данных было использовано для построения какого-либо распределения, тем достовернее будут сделанные на его основе статистические выводы. Для построения такой комбинации необходимо знать относительные сдвиги между алфавитами, использованными для шифрования различных групп.
Относительные сдвиги находятся при помощи некой модификации индекса совпадения. Построим для каждой группы Gi распределение числа появлений букв и запишем его в алфавитном порядке шифрованных букв. В табл. 24.1 показаны распределения для сообщения, приведенного на рис. 24.1, в предположении, что k = 7. Пусть fi, α — количество появлений буквы α алфавита i; определим функцию
где fi — количество появлений i-й буквы, а N — общее число рассматриваемых букв. Если все буквы рассматриваемого подмножества текста зашифрованы при помощи одного алфавита, то этот индекс совпадения должен иметь значение больше 0.045 и, вероятно, меньше 0.065 (теоретическое значение равно 0.055). Исходя из этого, алгоритм определения длины ключевого слова будет таким.
Шаг 1. Для i от 1 до 20 предположить, что длина ключевого слова равна i, и выполнить шаги 2, 3, 4. Мы выбрали верхнюю границу равной 20 лишь для удобства. Разумеется, ключевое слово может быть и длиннее.
Шаг 2. Для j от 1 до i выполнить шаг 3. В этих двух шагах будут вычислены i различных значений НС.
Шаг 3. Построить распределение числа появления букв в позициях j, i + j, 2i + j, …, т. е. в каждой i-й цозиции, начиная с j-й позиции. По формуле, приведенной выше, вычислить ИСj для полученного распределения. В качестве N в этой формуле нужно использовать число букв в данном подмножестве текста, а не длину всего текста.
Шаг 4. Если все значения ИС1, ИС2, …, ИСi больше 0.045, то, вероятно, i кратно длине ключевого слова. Если только один из ИС меньше 0.045, то i также может быть кратно длине ключевого слова.
Проверить длину ключевого слова можно и другим способом. Найдите два места в шифрованном тексте, где две одинаковые буквы идут в том же порядке, например ЦМ в позициях 19 и 54 на рис. 24.1. Такое повторение могло произойти по двум разным причинам. Возможно, в соответствующих местах исходного текста были различные сочетания букв, которым отвечали разные части ключевого слова, и они случайно отобразились в одинаковые сочетания букв, либо в исходном тексте были повторения, которые попали на одинаковые части ключевого слова, и, таким образом, оказались зашифрованными дважды одним и тем же способом. Во втором случае расстояние между началами повторяющихся сочетаний букв должно быть кратно длине ключевого слова. К сожалению, невозможно определить, по какой из двух причин произошло повторение данного сочетания букв: случайное повторение пар букв в шифрованном тексте довольно частое явление. Но если в шифрованном тексте повторяются сочетания из трех или более букв, то вероятность того, что это повторение произошло случайно, а не в результате повторения ключа, очень мала (для сочетаний из четырех и более букв она практически нулевая). Таким образом, другой способ выявления длины ключевого слова — отыскать в шифрованном тексте все пары повторяющихся групп из трех и более букв и измерить расстояния между ними. Число, которое делит 90% или более из этих расстояний, — прекрасный претендент на роль длины ключевого слова. Данная проверка вместе с вычислением значений ИС однозначно определяет длину ключевого слова.
Предположим, нам удалось выяснить, что длина ключевого слова равна k. Тогда первоначальный шифрованный текст можно разбить на k групп G1, G2, …, Gk, где каждая группа начинается с позиции i, 1 ≤ i ≤ k, и содержит каждую k-ю букву текста, начиная с i-й буквы. Каждая из этих к групп была зашифрована при помощи только одного алфавита, т. е. при помощи простой подстановки. Остается в каждой группе для каждой шифрованной буквы определить ее эквивалент в исходном тексте. Но здесь у нас имеется хорошее подспорье. Если бы был известен алфавит, по которому была зашифрована какая-нибудь из групп, то алфавит, по которому была зашифрована любая другая группа, можно было бы найти путем циклического сдвига уже известного алфавита на некоторое число букв. С другой стороны, определить исходные эквиваленты букв было бы проще, если бы удалось распределения числа появлений букв для различных групп скомбинировать в одно обобщенное распределение, поскольку, чем больше данных было использовано для построения какого-либо распределения, тем достовернее будут сделанные на его основе статистические выводы. Для построения такой комбинации необходимо знать относительные сдвиги между алфавитами, использованными для шифрования различных групп.
Относительные сдвиги находятся при помощи некой модификации индекса совпадения. Построим для каждой группы Gi распределение числа появлений букв и запишем его в алфавитном порядке шифрованных букв. В табл. 24.1 показаны распределения для сообщения, приведенного на рис. 24.1, в предположении, что k = 7. Пусть fi, α — количество появлений буквы α алфавита i; определим функцию
 Считается, что если β + r больше 32, то происходит циклический возврат к началу алфавита. Чем больше значение Ri, j, r, тем больше вероятность того, что алфавит для группы j в квадрате Виженера находится на r позиций ниже алфавита для группы i. Вычислим все значения Ri, j, r (для j ≤ i их можно не вычислять благодаря свойству симметрии) и выберем i и j, которые дают максимальное значение Ri, j, r. Вероятно, группа j сдвинута на r позиций относительно группы i.
Из групп Gi и Gj построим новую супергруппу Gij, положив величину fij, α равной fi, α + fi, α+r. Отбросим из рассмотрения группы Gi и Gj, заменив их группой Gij, и повторим описанный в последних двух абзацах процесс. После k − 1 повторений станут известны относительные сдвиги для всех k алфавитов. Кроме того, будет найдено обобщенное распределение частот. Для того чтобы найти исходные эквиваленты букв шифрованного текста, переупорядочим последние согласно их частотам. В результате буквы шифрованного текста должны расположиться в том же порядке, что и буквы русского алфавита (см. рис. 24.5). Теперь нетрудно восстановить весь квадрат Виженера и расшифровать текст. Ключевое слово можно найти, перебрав 32 набора из к букв, относительные расстояния между которыми соответствуют найденным сдвигам алфавитов. Возможно, что некоторые редко встречающиеся буквы окажутся не на своих местах. Эту ситуацию можно поправить при помощи визуального исследования полученного текста. Следует восстановить и смешанный алфавит, и ключевое слово, поскольку они оба могут иметь некоторую психологическую связь с содержанием сообщения и их выявление поможет дополнительно убедиться в правильности решения. Между прочим, что же написала мисс Хари?
Считается, что если β + r больше 32, то происходит циклический возврат к началу алфавита. Чем больше значение Ri, j, r, тем больше вероятность того, что алфавит для группы j в квадрате Виженера находится на r позиций ниже алфавита для группы i. Вычислим все значения Ri, j, r (для j ≤ i их можно не вычислять благодаря свойству симметрии) и выберем i и j, которые дают максимальное значение Ri, j, r. Вероятно, группа j сдвинута на r позиций относительно группы i.
Из групп Gi и Gj построим новую супергруппу Gij, положив величину fij, α равной fi, α + fi, α+r. Отбросим из рассмотрения группы Gi и Gj, заменив их группой Gij, и повторим описанный в последних двух абзацах процесс. После k − 1 повторений станут известны относительные сдвиги для всех k алфавитов. Кроме того, будет найдено обобщенное распределение частот. Для того чтобы найти исходные эквиваленты букв шифрованного текста, переупорядочим последние согласно их частотам. В результате буквы шифрованного текста должны расположиться в том же порядке, что и буквы русского алфавита (см. рис. 24.5). Теперь нетрудно восстановить весь квадрат Виженера и расшифровать текст. Ключевое слово можно найти, перебрав 32 набора из к букв, относительные расстояния между которыми соответствуют найденным сдвигам алфавитов. Возможно, что некоторые редко встречающиеся буквы окажутся не на своих местах. Эту ситуацию можно поправить при помощи визуального исследования полученного текста. Следует восстановить и смешанный алфавит, и ключевое слово, поскольку они оба могут иметь некоторую психологическую связь с содержанием сообщения и их выявление поможет дополнительно убедиться в правильности решения. Между прочим, что же написала мисс Хари?
 Значение R1, 0, 2 равно 333, а значение R3, 6, 12 равно 335. Значение R3, 6, 12 получается перемножением чисел появлений букв от А до У для G3 на числа появлений букв от М до Я для G6 и чисел появлений букв от Ф до Я для G3 на числа появлений букв от А до Л для G6 и сложением всех этих произведений.
Тема. Напишите программу, которая в качестве входных данных воспринимает шифрованное сообщение и, в предположении, что оно зашифровано по схеме Виженера, печатает расшифрованный текст. Программа должна также печатать квадрат Виженера и ключевое слово, которые она вычисляет в процессе решения задачи. Специальные входные параметры должны управлять выводом промежуточных результатов, таких, как, например, все возможные длины ключевого слова, распределения частот букв для отдельных алфавитов, значения ИС и т. д., которые нужны для контроля. Эти результаты могут быть полезны при отладке, а также в тех, к сожалению, вполне реальных ситуациях, когда предложенное машиной решение оказалось не совсем точным. Четкость оформления выводных данных имеет большое значение: бестолковые распечатки лишь затрудняют работу интуиции специалиста по расшифровке сообщений.
Указания исполнителю. Описанные здесь алгоритмы вполне понятны и легко реализуются, но обладают одним неприятным свойством — они не дают однозначного результата. Длина ключевого слова, например, будет лишь «вероятной», так что необходимо еще сделать обоснованный выбор одной из возможных длин. Аналогично алгоритмическое определение исходных эквивалентов для редко встречающихся букв шифрованного текста следует проверить, убедившись, что при расшифровке получаются правильные русские слова. Увеличивая статистическую информацию, доступную программе, мы получим более надежное основание для алгоритмических решений, но все равно эти решения должен проверить человек. Помимо указанных алгоритмов в вашей программе должны быть реализованы средства, позволяющие подтвердить обоснованность выводов, которые делает программа. Один хороший способ обеспечить такую оценочную функцию — написать программу в рамках какой-либо диалоговой системы, чтобы программа и пользователь смогли совместно обсудить качество каждого решения до того, как оно будет окончательно принято. «Обсуждение» обычно состоит в том, что программа сообщает человеку факты, говорящие в пользу того или иного возможного решения, а человек либо принимает его, либо отвергает, после чего вычисление может быть продолжено.
Несмотря на то что алгоритмы неоднозначны и такая расплывчатость обычно порождает у программиста чувство неуверенности, эту программу легко проверить. Первой частью работы, по-видимому, должна быть программа шифровки, которая воспринимает в качестве исходных данных русский текст и, выбрав некоторым случайным образом смешанный алфавит и ключевое слово, выдает квадрат Виженера и печатает зашифрованный текст в стандартном пятибуквенном формате. Пробелы и пунктуация должны убираться из текста автоматически. Эта программа должна уметь также воспринимать в качестве возможных параметров квадрат Виженера и ключевое слово, чтобы можно было повторно проверять отдельные особенности работы программы расшифровки. Помните о том, что для хорошего статистического поведения алгоритмов необходимо, чтобы сообщение было в 30–40 раз длиннее ключевого слова.
Инструментовка. Эта задача прямо-таки создана для языка типа Снобол, в котором средства работы с текстовыми данными сочетаются с простыми арифметическими операциями. Хорошим кандидатом может быть и какой-нибудь другой язык, с более широким диапазоном алгебраических вычислений и с достаточными средствами обработки текстовых данных, например PL/I, Паскаль или XPL. Но какой бы язык вы ни выбрали, постарайтесь избежать представления литер целыми числами; требования машинного представления не должны навязывать некрасивое, путаное решение задачи.
Длительность исполнения. Одному исполнителю на 2 недели.
* Партия переводчика. При переводе на русский язык зашифрованного примера надо было сначала расшифровать его. Попытка сделать это с помощью описанной процедуры не привела к успеху. После небольшого размышления стало ясно, что наш ключ не подходит потому, что он от другого замка! Действительно, предлагаемый автором способ определения относительных сдвигов столбцов с помощью величин Ri,j,r исходит из того, что два столбца отличаются, кроме случайных отклонений, циклическим сдвигом на величину, равную разности номеров двух букв ключевого слова. Это свойство будет иметь место, если несколько изменить способ шифрования. В нашем случае вместо Ri,j,r следует использовать числа pi, j, r, вычисляемые, как описано ниже.
Пусть число букв алфавита равно n. Будем обозначать i-ю букву алфавита xi или yi в зависимости от того, идет речь об исходном тексте или о зашифрованном. Нам известны средняя частота pi = = p(xi) появления i-й буквы в русском языке, число fk, i появлений i-й буквы в k-й группе зашифрованного текста, общее число Nk букв в k-й группе. Определим вероятности pk(yj|xi) появления фактического числа букв fk, j, если буква yj в k-й группе обозначает букву xi исходного текста. Эти вероятности подчиняются биномиальному распределению.
Значение R1, 0, 2 равно 333, а значение R3, 6, 12 равно 335. Значение R3, 6, 12 получается перемножением чисел появлений букв от А до У для G3 на числа появлений букв от М до Я для G6 и чисел появлений букв от Ф до Я для G3 на числа появлений букв от А до Л для G6 и сложением всех этих произведений.
Тема. Напишите программу, которая в качестве входных данных воспринимает шифрованное сообщение и, в предположении, что оно зашифровано по схеме Виженера, печатает расшифрованный текст. Программа должна также печатать квадрат Виженера и ключевое слово, которые она вычисляет в процессе решения задачи. Специальные входные параметры должны управлять выводом промежуточных результатов, таких, как, например, все возможные длины ключевого слова, распределения частот букв для отдельных алфавитов, значения ИС и т. д., которые нужны для контроля. Эти результаты могут быть полезны при отладке, а также в тех, к сожалению, вполне реальных ситуациях, когда предложенное машиной решение оказалось не совсем точным. Четкость оформления выводных данных имеет большое значение: бестолковые распечатки лишь затрудняют работу интуиции специалиста по расшифровке сообщений.
Указания исполнителю. Описанные здесь алгоритмы вполне понятны и легко реализуются, но обладают одним неприятным свойством — они не дают однозначного результата. Длина ключевого слова, например, будет лишь «вероятной», так что необходимо еще сделать обоснованный выбор одной из возможных длин. Аналогично алгоритмическое определение исходных эквивалентов для редко встречающихся букв шифрованного текста следует проверить, убедившись, что при расшифровке получаются правильные русские слова. Увеличивая статистическую информацию, доступную программе, мы получим более надежное основание для алгоритмических решений, но все равно эти решения должен проверить человек. Помимо указанных алгоритмов в вашей программе должны быть реализованы средства, позволяющие подтвердить обоснованность выводов, которые делает программа. Один хороший способ обеспечить такую оценочную функцию — написать программу в рамках какой-либо диалоговой системы, чтобы программа и пользователь смогли совместно обсудить качество каждого решения до того, как оно будет окончательно принято. «Обсуждение» обычно состоит в том, что программа сообщает человеку факты, говорящие в пользу того или иного возможного решения, а человек либо принимает его, либо отвергает, после чего вычисление может быть продолжено.
Несмотря на то что алгоритмы неоднозначны и такая расплывчатость обычно порождает у программиста чувство неуверенности, эту программу легко проверить. Первой частью работы, по-видимому, должна быть программа шифровки, которая воспринимает в качестве исходных данных русский текст и, выбрав некоторым случайным образом смешанный алфавит и ключевое слово, выдает квадрат Виженера и печатает зашифрованный текст в стандартном пятибуквенном формате. Пробелы и пунктуация должны убираться из текста автоматически. Эта программа должна уметь также воспринимать в качестве возможных параметров квадрат Виженера и ключевое слово, чтобы можно было повторно проверять отдельные особенности работы программы расшифровки. Помните о том, что для хорошего статистического поведения алгоритмов необходимо, чтобы сообщение было в 30–40 раз длиннее ключевого слова.
Инструментовка. Эта задача прямо-таки создана для языка типа Снобол, в котором средства работы с текстовыми данными сочетаются с простыми арифметическими операциями. Хорошим кандидатом может быть и какой-нибудь другой язык, с более широким диапазоном алгебраических вычислений и с достаточными средствами обработки текстовых данных, например PL/I, Паскаль или XPL. Но какой бы язык вы ни выбрали, постарайтесь избежать представления литер целыми числами; требования машинного представления не должны навязывать некрасивое, путаное решение задачи.
Длительность исполнения. Одному исполнителю на 2 недели.
* Партия переводчика. При переводе на русский язык зашифрованного примера надо было сначала расшифровать его. Попытка сделать это с помощью описанной процедуры не привела к успеху. После небольшого размышления стало ясно, что наш ключ не подходит потому, что он от другого замка! Действительно, предлагаемый автором способ определения относительных сдвигов столбцов с помощью величин Ri,j,r исходит из того, что два столбца отличаются, кроме случайных отклонений, циклическим сдвигом на величину, равную разности номеров двух букв ключевого слова. Это свойство будет иметь место, если несколько изменить способ шифрования. В нашем случае вместо Ri,j,r следует использовать числа pi, j, r, вычисляемые, как описано ниже.
Пусть число букв алфавита равно n. Будем обозначать i-ю букву алфавита xi или yi в зависимости от того, идет речь об исходном тексте или о зашифрованном. Нам известны средняя частота pi = = p(xi) появления i-й буквы в русском языке, число fk, i появлений i-й буквы в k-й группе зашифрованного текста, общее число Nk букв в k-й группе. Определим вероятности pk(yj|xi) появления фактического числа букв fk, j, если буква yj в k-й группе обозначает букву xi исходного текста. Эти вероятности подчиняются биномиальному распределению.
 Далее найдем по формуле Байеса вероятности pk(xi|yj) того, что буква уj в k-й группе означает букву xi исходного текста. Априорные вероятности гипотез примем равными 1/n.
Далее найдем по формуле Байеса вероятности pk(xi|yj) того, что буква уj в k-й группе означает букву xi исходного текста. Априорные вероятности гипотез примем равными 1/n.
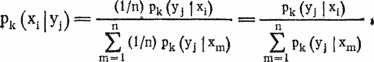 Рассмотрим теперь пару групп (столбцов табл. 24.1) k и l. Будем говорить, что между ними имеется сдвиг r, если каждой букве yj зашифрованного текста в 1-й группе соответствует буква исходного текста на r большая (по модулю n), чем в k-й группе. Это означает, что в ключевом слове 1-я буква на r меньше k-й. Для оценки вероятностей pk, l, r того, что между k-й и l-й группами имеется сдвиг r, вычислим величины
Рассмотрим теперь пару групп (столбцов табл. 24.1) k и l. Будем говорить, что между ними имеется сдвиг r, если каждой букве yj зашифрованного текста в 1-й группе соответствует буква исходного текста на r большая (по модулю n), чем в k-й группе. Это означает, что в ключевом слове 1-я буква на r меньше k-й. Для оценки вероятностей pk, l, r того, что между k-й и l-й группами имеется сдвиг r, вычислим величины
 Символы ⊕, ⊖ означают сложение и вычитание по модулю n. Величина рк, i г есть вероятность фактического распределения числа появлений букв при условии, что имеет место сдвиг r. Здесь не учитывается, что разные yj соответствуют разным Значения pk, l, r получаются по формуле Байеса
Символы ⊕, ⊖ означают сложение и вычитание по модулю n. Величина рк, i г есть вероятность фактического распределения числа появлений букв при условии, что имеет место сдвиг r. Здесь не учитывается, что разные yj соответствуют разным Значения pk, l, r получаются по формуле Байеса
 Фактический сдвиг r(k, l) между k-й и l-й группами должен иметь довольно большую вероятность pk, l, r. Но насколько большую? В следующей таблицеприведены данные о расшифровке оригинала примера.
Фактический сдвиг r(k, l) между k-й и l-й группами должен иметь довольно большую вероятность pk, l, r. Но насколько большую? В следующей таблицеприведены данные о расшифровке оригинала примера.
 В клетке с координатами k, l указано, какое место в порядке убывания pk, l, r для фиксированных k и l занимает фактический сдвиг r(k, l). Видно, что за двумя исключениями номер места не превышает шести. Таким образом, величины сдвигов r(k, l) следует искать среди тех, которые дают 6–7 наибольших значений pk, l, r для данных k и l. Для выбора из них фактических величин сдвига следует воспользоваться согласованностью сдвигов r(k, l) ⊕ r(l, n) = r(k, m). Складывая всех кандидатов для r(1, 2) с r(2, 3) и проверяя, находится ли результат среди кандидатов для r(1, 3), можно отбросить большую часть вариантов. Затем следует аналогично определить r(1, 4), учитывая r(2, 4) и r(3, 4), и т. д. Этот перебор легко провести вручную, если число кандидатов для каждого r(k, l) не более 8. Поскольку возможны исключительные случаи (r(3, 5) и r(4, 5) в приведенной выше таблице), то в результате этого процесса сдвиг для какой-либо группы может оказаться определенным неправильно либо процесс может вообще не сойтись (будут отброшены все варианты). В таком случае следует заново определить величину сдвига для наихудшей группы (определяемой, например, по наибольшему среднему месту для сдвигов относительно этой группы), учитывая большее число кандидатов.
После определения сдвигов следует найти ключевое слово, как описано в основном тексте, рассматривая все слова вида xa, xa ⊖ r(1, 2), xa ⊖ r(1, 3), … (а = 1, …, n). Возможно, для получения осмысленного слова придется изменить одну из букв. Определив ключевое слово, находим окончательные величины сдвигов.
Теперь для определения перестановки вычислим вероятности p(xi|yj) того, что буква yj в зашифрованном тексте соответствует букве xi в первой группе, xi ⊕ r(1, 2) — во второй и т. д.:
В клетке с координатами k, l указано, какое место в порядке убывания pk, l, r для фиксированных k и l занимает фактический сдвиг r(k, l). Видно, что за двумя исключениями номер места не превышает шести. Таким образом, величины сдвигов r(k, l) следует искать среди тех, которые дают 6–7 наибольших значений pk, l, r для данных k и l. Для выбора из них фактических величин сдвига следует воспользоваться согласованностью сдвигов r(k, l) ⊕ r(l, n) = r(k, m). Складывая всех кандидатов для r(1, 2) с r(2, 3) и проверяя, находится ли результат среди кандидатов для r(1, 3), можно отбросить большую часть вариантов. Затем следует аналогично определить r(1, 4), учитывая r(2, 4) и r(3, 4), и т. д. Этот перебор легко провести вручную, если число кандидатов для каждого r(k, l) не более 8. Поскольку возможны исключительные случаи (r(3, 5) и r(4, 5) в приведенной выше таблице), то в результате этого процесса сдвиг для какой-либо группы может оказаться определенным неправильно либо процесс может вообще не сойтись (будут отброшены все варианты). В таком случае следует заново определить величину сдвига для наихудшей группы (определяемой, например, по наибольшему среднему месту для сдвигов относительно этой группы), учитывая большее число кандидатов.
После определения сдвигов следует найти ключевое слово, как описано в основном тексте, рассматривая все слова вида xa, xa ⊖ r(1, 2), xa ⊖ r(1, 3), … (а = 1, …, n). Возможно, для получения осмысленного слова придется изменить одну из букв. Определив ключевое слово, находим окончательные величины сдвигов.
Теперь для определения перестановки вычислим вероятности p(xi|yj) того, что буква yj в зашифрованном тексте соответствует букве xi в первой группе, xi ⊕ r(1, 2) — во второй и т. д.:
 (r(1, 1) полагаем равным нулю, d — число групп)
(r(1, 1) полагаем равным нулю, d — число групп)
 Фактические значения xi должны давать большие значения p(xi|yj). Числа p(xi|yj) дают для определения перестановки существенно более четкую информацию, чем числа pk,l, r для определения сдвигов. Оказывается, что при длине текста около 700 букв для большинства букв yj зашифрованного текста соответствующие им xi дают максимальное значение p(xi|yj). Перестановка легко уточняется, если начать расшифровку, учитывая осмысленность получаемого текста.
При реализации этого алгоритма на ЭВМ следует иметь в виду, что числа p̃k, l, r могут оказаться весьма малыми. Так, при расшифровке оригинала примера они лежали в диапазоне от 10−51 до 10−36. Если на вашей ЭВМ такие числа непредставимы, то вычислите логарифмы log p̃k, l, r. Числа pk, l, r и p(xi|yj) можно не вычислять, воспользовавшись вместо них pk, l, r и p(xi|yj), отличающимися постоянным множителем.
Этот способ позволил расшифровать английский оригинал примера. Удастся ли вам проделать то же с русским текстом?
Фактические значения xi должны давать большие значения p(xi|yj). Числа p(xi|yj) дают для определения перестановки существенно более четкую информацию, чем числа pk,l, r для определения сдвигов. Оказывается, что при длине текста около 700 букв для большинства букв yj зашифрованного текста соответствующие им xi дают максимальное значение p(xi|yj). Перестановка легко уточняется, если начать расшифровку, учитывая осмысленность получаемого текста.
При реализации этого алгоритма на ЭВМ следует иметь в виду, что числа p̃k, l, r могут оказаться весьма малыми. Так, при расшифровке оригинала примера они лежали в диапазоне от 10−51 до 10−36. Если на вашей ЭВМ такие числа непредставимы, то вычислите логарифмы log p̃k, l, r. Числа pk, l, r и p(xi|yj) можно не вычислять, воспользовавшись вместо них pk, l, r и p(xi|yj), отличающимися постоянным множителем.
Этот способ позволил расшифровать английский оригинал примера. Удастся ли вам проделать то же с русским текстом?
Литература
Гэн (Gaines H. F.). Cryptanalysis. Dover, New York, NY, 1956. Элементарная книга, которая обычно прежде всех других попадает в руки любителям тайнописи. Здесь указано недорогое издание в бумажном переплете, содержащее подробные методы раскрытия для довольно сложных шифров. Оригинал книги вышел в свет достаточно давно, поэтому в ней вы не найдете обсуждения математических методов, имеющихся в книге Синкова, но классические методы описаны хорошо. Приводится несколько полезных таблиц. Гарднер (Gardner М.). Mathematical Games. Scientific American, August, 1977, pp. 120–124. Гарднер сообщает о новом, практически нераскрываемом шифре. Метод шифрования основан на свойствах очень больших простых чисел, а для зашифровки необходима ЭВМ. Если вы реализуете задачу гл. 22, то будете иметь средство для создания идеально секретного метода коммуникации. Кан (Kahn D.). The Code Breakers. Macmillan, New York, NY, 1967. Кан написал очень ясную книгу по криптографии. Хотя после 1967 г. стали известны некоторые новые интересные материалы о второй мировой войне, тем не менее книга содержит все, что может быть интересно любителю, об истории и методах тайнописи. В книге прекрасная библиография, Синков (Sinkov A.). Elementary Cryptanalysis — A Mathematical Approach. Random House, New York, NY, 1968. Очень простая книга по анализу криптограмм. Содержит некоторые математические обоснования. По-видимому, Управлению национальной безопасности известны и более прогрессивные методы тайнописи, но оно, естественно, об этом не распространяется. Рассуждения, приведенные в этой главе, взяты из материалов Синкова.ТЕМЫ ДЛЯ КУРСА ПО КОМПИЛЯТОРАМ
Для того чтобы охватить полный курс по компиляторам, темы для этюдов собраны в одно место. Любой студент, справившийся со всеми четырьмя этюдами, хорошо усвоит как практические, так и теоретические вопросы создания трансляторов. Если выполнять этюды в порядке их следования, то результаты каждого из них могут служить входными данными для последующих. Например, для тестирования компилятора можно применить эмулятор машины и загрузчик. Не каждый студент возьмется, вероятно, в одиночку за изготовление компилятора или загрузчика, а вот интерпретатор Трака или моделирование компьютера под силу и одному исполнителю. Все четыре темы могут быть исполнены за полтора — два семестра при соответствующем руководстве.25. Уча — учимся, или... МОДЕЛИРОВАНИЕ БОЛЬШОГО КОМПЬЮТЕРА
Если вы читаете эти строки, у вас почти наверняка есть под рукой подходящий компьютер. Возможно, покажется несколько странным, зачем нужно писать программу, делающую буквально то же самое, что уже умеет делать компьютер (если он исправен). Но уверены ли вы, что в точности знаете, что ваша ЭВМ в состоянии делать? Да и позволят ли вам другие пользователи достаточно долго узурпировать машину, чтобы изучить все черты ее характера? Билл Мак-Киман утверждает, что никогда не следует браться за большой проект, зависящий от структуры машины вроде компилятора или операционной системы, до тех пор, пока не создан имитатор. Но как это всегда бывает, чтобы чему-то научиться, надо научить этому кого-нибудь другого (скажем, компьютер?!). Учебной машины модели 1 в действительности не существует. Однако, следуя традиции, она заимствует характерные черты нескольких известных машин. УМ-1 проще многих компьютеров из пластика и металла, но именно это позволяет больше внимания уделить ее структуре. Приводимое описание не претендует на полноту, характерную для руководств по ЭВМ — для такого изложения потребовалось бы дополнительное место, а его у нас нет. Чтобы восполнить пробелы, необходимо обратиться к собственным знаниям о других компьютерах. Численные значения везде, где они будут встречаться ниже, представлены в шестнадцатеричной системе (по основанию 16), как наиболее удобной для машины. Память и регистры ЭВМ УМ-1 снабжена памятью из 216 8-разрядных байтов, адресуемых от 0 до 216-1. Каждый байт памяти может содержать одну из 256 литер в коде ASCII [41], воспроизведенном на рис. 25.1. Любая группа четырех смежных байтов, адрес самого левого из которых делится нацело на четыре, является словом. Рисунок 25.1. Набор кодировок символов ASCII. Позиции, отмеченные знаком
Рисунок 25.1. Набор кодировок символов ASCII. Позиции, отмеченные знаком  Рисунок 25.2. Схема основной памяти. Обратите внимание, что к регистрам можно адресоваться как к памяти.
Регистр признака результата (РПР) содержит 4 двоичных разряда. Чаще всего формирование РПР является побочным результатом выполнения команды, и его содержимое может опрашиваться командами передачи управления. Четыре разряда этого регистра — признак результата — называются (слева направо) соответственно бит переполнения, бит больше, чем, бит меньше, чем, и бит равно. В случае когда содержимое РПР задается непосредственно в команде, РПР сначала полностью обнуляется, а затем уже требуемые разряды устанавливаются равными 1. Если происходит переполнение, устанавливается лишь бит переполнения. Опрос состояния РПР не влияет на его содержимое.
Рисунок 25.2. Схема основной памяти. Обратите внимание, что к регистрам можно адресоваться как к памяти.
Регистр признака результата (РПР) содержит 4 двоичных разряда. Чаще всего формирование РПР является побочным результатом выполнения команды, и его содержимое может опрашиваться командами передачи управления. Четыре разряда этого регистра — признак результата — называются (слева направо) соответственно бит переполнения, бит больше, чем, бит меньше, чем, и бит равно. В случае когда содержимое РПР задается непосредственно в команде, РПР сначала полностью обнуляется, а затем уже требуемые разряды устанавливаются равными 1. Если происходит переполнение, устанавливается лишь бит переполнения. Опрос состояния РПР не влияет на его содержимое.
Типы данных в машине
О литерах выше уже упоминалось. Иногда их рассматривают как положительные 8-разрядные целые числа. Слова могут содержать 32-разрядные целые числа в дополнительном коде. Нулевой разряд в слове является разрядом знака и равен нулю в случае положительных чисел и единице — в случае отрицательных (знак является признаком дополнительного кода). Когда более короткие целые со знаком, например, обсуждаемые ниже непосредственные операнды, выступают в комбинации со словами, знаковый разряд укороченного слова размножается влево, заполняя отсутствующие биты. Вещественные числа занимают также одно слово. Нулевой разряд определяет знак числа, разряды с 1-го по 7-й образуют порядок, а разряды с 8-го по 31-й — мантиссу. Положительные вещественные числа в знаковом разряде имеют нуль, поле порядка содержит показатель степени 16, увеличенный на 4016, а мантисса представляет собой 24-разрядную нормализованную шестнадцатеричную дробную часть числа, причем считается, что шестнадцатеричная точка стоит в мантиссе слева от старшей цифры. Нормализованность шестнадцатеричной мантиссы означает, что, по крайней мере, самая левая ее шестнадцатеричная цифра отлична от нуля, если таковая вообще имеется. Если мантисса получилась нулевой, то все число полагается равным нулю. Любой конечный результат операции действительной арифметики, который из-за ограниченности поля порядка не может быть представлен в слове, вызывает особый случай некорректности представления. Отрицательные вещественные числа представляют собой двоичное дополнение соответствующих положительных значений. В командах с вещественным непосредственным операндом применяются специальные короткие вещественные числа, образуемые отбрасыванием трех самых правых цифр мантиссы.Форматы команд
Встречаются команды короткие — в двухбайтовом формате — и длинные — четырехбайтовые. Все команды должны располагаться с границы четных байтов: если перед началом цикла выполнения команды в САК оказывается нечетный адрес, возникает особый случай запрещенного адреса команды. Первый байт любой команды содержит косвенный бит [42] в разряде 0 и код операции (КОП) в разрядах с 1-го по 7-й. Не все коды операций имеют смысл, и не во всех командах используется косвенный бит. Появление запрещенного КОП вызывает особый случай некорректной команды. В большинстве команд в разрядах с 8-го по 11-й указывается либо общий регистр, либо 4-разрядная литерная константа, употребляемая в качестве маски, а в разрядах с 12-го по 15-й задается второй общий регистр. Имеются четыре вида команд: регистр-регистр (двухбайтовые команды), регистр-память, непосредственная и байтовая. Каждый тип отличается присущей ему характерной интерпретацией и способом адресации, которые мы сейчас и рассмотрим подробнее. 1. Регистр-регистр. Во всех командах типа регистр-регистр в разрядах с 12-го по 15-й указывается регистр, выступающий в качестве одного из операндов команды. Если задан косвенный бит, то операнд расположен по адресу, содержащемуся в 16—31-м разрядах регистра, номер которого указан в 12—15-м разрядах команды. В разрядах с 8-го по 11-й может быть задан или регистр, или маска. В командах CCS и MCS косвенный бит не используется. Рисунок 25.3. Форматы представления информации,
2. Регистр-память. Обычно в командах типа регистр-память в разрядах с 8-го по 11-й указывается регистр или 4-разрядная маска, и они выступают в качестве одного из операндов. Остальная часть команды используется для формирования исполнительного адреса по следующему правилу:
— Если косвенный бит равен 0 и указатель индекс-регистра (разряды с 12-го по 15-й) равен 0, то исполнительный адрес дается полем адреса (разряды с 16-го по 31-й) команды.
— Если косвенный бит равен нулю, а указатель индекс-регистра нулю не равен, то адресная часть команды дополняется слева нулями и складывается (разумеется, в дополнительном коде) с содержимым индекс-регистра. Разряды 16—31 результата образуют исполнительный адрес. Содержимое индекс-регистра не изменяется,
— Если косвенный бит не нуль, а указатель индекс регистра — нуль, адресное поле указывает местонахождение в памяти двухбайтового косвенного поля. Содержимое косвенного поля образует исполнительный адрес. Если косвенное поле начинается не с границы четного байта, происходит особый случай некорректной косвенной адресации.
— Если косвенный бит и указатель индекс-регистра не равны нулю, косвенное поле складывается с содержимым индекс-регистра и в качестве исполнительного адреса берутся правые 16 разрядов суммы. При этом может иметь место особый случай некорректной косвенной адресации.
3. Непосредственная. Во всех непосредственных командах регистр указывается в разрядах с 8-го по 11-й, а в разрядах 12—31 содержится непосредственный операнд. В качестве непосредственного операнда может выступать 20-разрядное целое в дополнительном коде, 20-разрядный логический вектор или же действительное число в коротком формате. В командах с непосредственным операндом косвенный бит игнорируется.
4. Байтовая. Команды байтового типа выполняются аналогично командам типа регистр-память.
Описание команд
Опишем в этом разделе каждую команду. В первой строке описания приводится краткая справка, состоящая из названия команды, ее формата (RR, RS, IM, СН[43]), шестнадцатеричного кода операции, записи команды на языке ассемблера[44] и перечисления разрядов регистра признака результата, которые могут командой изменяться. Затем следует словесное описание. Содержимое РПР, устанавливаемое в результате выполнения команды, обозначает- обозначается символами О, L, G, Е[45]) или Нет (указание на то, что РПР не изменяется).
Load Register RR 0016 LR,R1 R2 GLE (Загрузка регистра)
В регистр R1 пересылается содержимое слова по исполнительному адресу. Пересылаемое значение сравнивается с нулем, и в РПР устанавливается соответствующий разряд: G, L или Е[46]). Если исполнительный адрес не попадает на границу слова, происходит особый случай неверной адресации слова.
Load RS 2016 L, R1A, R2 GLE (Загрузка)
Эта команда выполняется аналогично команде Load Register с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Immediate IM 4016 LI,R1 I GLE (Загрузка непосредственная)
Эта команда выполняется так же, как Load Register, с той разницей, что пересылаемая величина является непосредственным операндом I, при этом его знаковый разряд размножается на 12 битов влево. Особых случаев произойти не может.
Load Character СН 6016 LC, R1 А, R2 GE (Загрузка байта)
Регистр R1 обнуляется, и байт по исполнительному адресу записывается в его разряды 24—31. Производится сравнение пересылаемой величины с нулем, и в РПР устанавливаются разряды G или Е.
Load Negative Register RR 0116 LNR, R1 R2 OGLE (Загрузка регистра отрицательная)
В регистр R1 засылается дополнительный код слова по исполнительному адресу. Результат сравнивается с нулем и устанавливается РПР. При переполнении в РПР устанавливается лишь разряд 0. Может иметь место особый случай неверной адресации слова.
Load Negative RS 2116 LN, R1A,R2 OGLE (Загрузка отрицательная)
Эта команда выполняется так же, как Load Negative Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Negative Immediate IM 4116 LNI,R1 I GLE (Загрузка непосредственная отрицательная)
В регистр R1 помещается 32-разрядное двоичное дополнение 20-разрядного непосредственного операнда I, заданного в дополнительном коде. Переполнение произойти не может. Установка РПР осуществляется сравнением результата с нулем.
Load Negative Character CH 6116 LNC,R1 A,R2 LE (Загрузка байта отрицательная)
Байт по исполнительному адресу дополняется слева нулями до 32 разрядов и дополнительный код полученного слова помещается в регистр R1. Переполнения произойти не может. Для установки РПР полученная величина сравнивается с нулем.
Store Register RR 0216 STR, R1 R2 GLE (Запись регистра)
Содержимое R1 запоминается в слове по исполнительному адресу. Результат сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Store RS 2216 ST, R1 A, R2 GLE (Запись в память)
Эта команда выполняется так же, как команда Store Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Store Character CH 6216 STC, R1 A,R2 GE (Запись в память байта)
Разряды 24—31 регистра R1 помещаются в байт по исполнительному адресу. Для установки РПР занесенная величина сравнивается с нулем.
Swap Register RR 0316 SWAPR, R1 R2 GLE (Обмен)
Содержимое регистра Rl и слова по исполнительному адресу меняются местами. Новая величина в R1 сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Swap RS 2316 SWAP,R1 A,R2 GLE (Обмен с памятью)
Эта команда выполняется так же, как команда Swap Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Swap Character CH 6316 SWAPC, R1 А, R2 GE (Обмен с байтом)
Разряды 24—31 регистра R1 меняются местами с байтом по исполнительному адресу. РПР устанавливается при сравнении нового содержимого R1 с нулем. Разряды с 0-го по 23-й регистра R1 не изменяются,
And Register RR 0416 ANDR,R1 R2 GLE (И)
В регистр R1 помещается поразрядное логическое произведение (И) содержимого R1 и слова по исполнительному адресу. Если все разряды результата состоят из единиц, то в РПР устанавливается G, если из нулей — то Е, иначе — L, Может иметь место особый случай неверной адресации слова.
And RS 2416 AND,R1A,R2 GLE (И)
Эта команда выполняется аналогично And Register с тем отличием, что для определения исполнительного адреса используется правило адресации команд типа регистр-память.
And Immediate IM 4416 ANDI,R1 I LE (И)
В регистре R1 помещается поразрядное логическое произведение (И) содержимого R1 и непосредственно указанной величины I, дополненной слева 12 нулевыми разрядами. РПР устанавливается так же, как в команде And Register.
And Character CH 6416 ANDC,R1 A,R2 GLE (И)
В регистре R1 разряды 24—31 заменяются их логическим произведением на байт по исполнительному адресу. Разряды 0—23 регистра R1 не изменяются. РПР устанавливается так же, как в команде And Register.
Or Register RR 0516 ORR, R1 R2 GLE (ИЛИ)
Эта команда выполняется так же, как And Register, но логическое И заменяется логическим ИЛИ.
Or RS 2516 OR, R1A, R2 GLE (ИЛИ)
Эта команда выполняется так же, как And, но логическое И заменяется логическим ИЛИ.
Or Immediate LM 4516 ORI,R1 I GLE (ИЛИ)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется логическим ИЛИ.
Or Character СН 6516 ORC,R1 А R2 (ИЛИ)
Эта команда выполняется так же, как And Character, но логическое И заменяется логическим ИЛИ.
Exclusive Or Register RR 0616 XORR,R1 R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Register, но логическое И заменяется исключающим ИЛИ.
Exclusive Or RS 2616 XOR,R1 A,R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Immediate IM 4616 XORI,R1 I GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Character CH 6616 XORC,R1 A,R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Character, но логическое И заменяется исключающим ИЛИ.
Not Register RR 0716 NOTR, Rl R2 GLE (Отрицание)
Эта команда выполняется так же, как And Register, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not RS 2716 NOT,R1A, R2 GLE (Отрицание)
Эта команда выполняется так же, как And, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not Immediate IM 4716 NOTI,R1 I GLE (Отрицание)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется логическим отрицанием расширенного второго операнда. Исходное содержимое R1 игнорируется.
Not Character CH 6716 NOTC,R1 A,R2 GLE (Отрицание)
Эта команда выполняется так же, как And Character, но логическое И заменяется логическим отрицанием второго операнда. Содержимое разрядов 24—31 регистра R1 игнорируется.
Branch Conditions Set Register RR 0816 BCSR,M1 R2 Нет (Условный переход по единице)
Если логическое произведение содержимого РПР и 4-разрядной маски M1 не равно нулю, содержимое САК замещается исполнительным адресом,
Branch Conditions Set RS 2816 BCS,M1 A,R2 Нет (Условный переход по единице)
Эта команда выполняется так же, как Branch Conditions Set Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch Conditions Reset Register RR 0916 BCRR,M1 R2 Нет (Условный переход по нулю)
Если логическое произведение содержимого РПР и 4-разрядной маски M1 равно нулю, содержимое САК замещается исполнительным адресом.
Branch Conditions Reset RS 2916 BCR,M1 A,R2 Нет (Условный переход по нулю)
Эта команда выполняется так же, как Branch Conditions Reset Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch and Link Register RR 0A16 BALR,R1 R2 Нет (Переход с возвратом)
Текущее содержимое САК засылается в регистр R1, а исполнительный адрес команды помещается в САК. Если признак косвенной адресации не задан, исполнительный адрес равен указателю регистра R2, умноженному на 4.
Branch and Link RS 2A16 BAL,R1 A,R2 Нет (Переход с возвратом)
Текущее содержимое САК заносится в регистр R1, а в САК засылается исполнительный адрес команды.
Save Condition Register RR 0B16 SACR,M1 R2 Нет (Сохранение состояния)
Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается слово, состоящее из всех единиц; в противном случае записывается нулевое слово. Может иметь место особый случай неверной адресации слова.
Save Condition RS 2В16 SAC, М1 А, R2 Нет (Сохранение состояния)
Эта команда выполняется так же, как команда Save Condition Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Save Condition Character CH 6B16 SACC,M1 A,R2 Нет (Сохранение состояния)
Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается байт, состоящий из всех единиц; в противном случае записывается нулевой байт.
Compare Register RR 0С16 CR,R1 R2 GLE (Сравнение)
В результате арифметического сравнения содержимого регистра R1 и слова по исполнительному адресу в РПР устанавливается соответствующий разряд: G, L или Е. Может иметь место особый случай неверной адресации слова.
Compare RS 2С16 С , R1 A , R2 GLE (Сравнение)
Эта команда выполняется так же, как Compare Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Compare Immediate IM 4C16 CI,R1 I GLE (Сравнение непосредственное)
Содержимое 32-разрядного регистра R1 арифметически сравнивается с полным словом, образованным из непосредственного операнда размножением его знакового разряда на 12 позиций влево. Вырабатывается соответствующий признак результата, и разряд G, L или Е устанавливается в РПР.
Compare Character CH 6C16 CC,R1 A,R2 GLE (Сравнение байтов)
Содержимое разрядов 24—31 регистра R1 сравнивается как 8-разрядное целое положительное число с байтом по исполнительному адресу. Вырабатывается соответствующий признак результата, и в РПР устанавливается разряд G, L или Е.
Compare Character String RR 0E16 CCS,M1 R2 GLE (Сравнение цепочки байтов)
Указатель регистра R2 обозначает пару регистров R2 и (R2+1)mod16 (второй регистр будем везде называть R2+1). В двойном слове, образованном парой R2 и R2+1 должно содержаться описание цепочки, а именно в разрядах 16—31 регистра R2 указывается адрес байта А1, в разрядах 0—15 регистра R2+1 — длина цепочки L и в разрядах 16—31 регистра R2 +1 — адрес байта А2. Для выполнения команды величины A1, A2 и L помещаются во внутренние регистры, РПР обнуляется и Е-бит РПР устанавливается в единицу. Затем отрабатывает следующий цикл.
1. Если L=0, то разряды 0—15 обоих регистров обнуляются, в 16—31-й разряды R2 из в внутренних регистров переносится А1, а в 16—31-й разряды R2+1 переносится А2, и выполнение команды заканчивается.
2. Байты по А1 и А2 сравниваются как 8-разрядные целые числа, и в РПР устанавливается соответствующий признак результата.
3. Если Е-бит РПР не равен единице, то 0—15-й разряды регистра R2 обнуляются, а из внутренних регистров в 16—31-й разряды R2 пересылается А1, в 0—15-й разряды R2+1 — длина L и в 16—31-й разряды R2+1 — адрес А2, и команда завершается.
4. L уменьшается на 1, адрес А1 увеличивается на величину маски M1, представляющую собой 4-разрядное целое в дополнительном коде, А2 увеличивается на 1, и цикл повторяется с первого шага.
Move Character String RR 0F16 MCS,M1 R2 Нет (Пересылка цепочки байтов)
В двойном слове R2 и (R2 +1)mod16 содержится описание цепочки в виде, описанном в команде Compare Character String. Поля L, A1 и А2 загружаются во внутренние регистры. Затем выполняется цикл.
1. Если L=0, разряды 0—15 регистров R2 и R2+1 очищаются, в 16—31-й разряды R2 помещается текущее А1, в 16—31-й разряды R2+1—значение А2, и выполнение команды завершается.
2. Байт по адресу А1 пересылается в байт по А2.
3. L уменьшается на 1, а А2 увеличивается на 1.
4. А1 увеличивается на величину маски M1, рассматриваемую как 4-разрядное целое число в дополнительном коде, и цикл возвращается к первому шагу.
Supervisor Call RS 2E16 SVC,R1 A,R2 Нет (Обращение к супервизору)
Выполнение программы прерывается, и управление передается в управляющую программу супервизора.
Execute RS 2F16 EX , R1 A, R2 Нет (Выполнить)
Выполняется команда, содержащаяся по исполнительному адресу. Результаты ее исполнения становятся таковыми для данной команды Execute. Если исполнительный адрес команды Execute нечетный, имеет место особый случай некорректности команды Execute. Глубина вложений команды Execute может быть любой. Заметим, что изменение САК происходит только в случае, когда это явным образом производится в подчиненной команде.
Load Adress RS 4E16 LA,R1 A,R2 Нет (Загрузка адреса)
Исполнительный адрес команды помещается в регистр R1
Load Multiple RS 6E16 LM,R1A,R2 Нет (Загрузка групповая)
В регистры от R1 до R2 загружается содержимое последовательных слов памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше, чем R1, то загружаются регистры от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Store Multiple RS 6F16 STM,R1A,R2 Нет (Запись групповая)
Содержимое регистров от R1 до R2 записывается в последовательные слова памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше R1, то записывается содержимое регистров от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Add Register RR 1016 AR,R1 R2 OGLE (Сложение)
Слово в регистре R1 складывается со словом по исполнительному адресу, и результат помещается в R1. Для установки РПР сумма сравнивается с нулем. В случае переполнения в РПР устанавливается лишь О-бит. Может иметь место особый случай неверной адресации слова.
Add RS 3016 A,R1 A,R2 OGLE (Сложение)
Эта команда выполняется так же, как Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Add Immediate IM 5016 AI,R1 I OGLE (Сложение непосредственное)
20-разрядный непосредственный операнд I, заданный в дополнительном коде, складывается с содержимым регистра R1, и сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Add Character CH 7016 AC, R1 A, R2 OGLE (Сложение байта)
Байт по исполнительному адресу дополняется слева 24 нулевыми разрядами и складывается с содержимым регистра R1, причем сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Register RR 1116 SR,R1 R2 OGLE (Вычитание)
Слово по исполнительному адресу (вычитаемое) вычитается из содержимого регистра R1 (уменьшаемое), и разность записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Subtract RS 3116 S,R1 A,R2 OGLE (Вычитание)
Эта команда выполняется так же, как Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Subtract Immediate IМ 5116 SI, R1 I OGLE (Вычитание непосредственное)
Из содержимого регистра R1 (уменьшаемое) вычитается 20-разрядный непосредственный операнд (вычитаемое), рассматриваемый как целое в дополнительном коде, и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Character CH 7116 SC,R1 A,R2 OGLE (Вычитание байта)
Из содержимого регистра R1 (уменьшаемое) вычитается байт по исполнительному адресу, дополненный слева 24 нулевыми разрядами (вычитаемое), который трактуется как положительное целое число. Результат записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Reverse Subtract Register RR 1216 RSR,R1 R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как команда Subtract Register, с тем отличием, что вычитаемое и уменьшаемое меняются ролями[47]).
Reverse Subtract RS 3216 RS,R1 A,R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как Subtract, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Immediate IM 5216 RSI,R1 I OGLE (Вычитание непосредственное обратное)
Эта команда выполняется так же, как Subtract Immediate, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Character CH 7216 RSC,R1 A,R2 OGLE (Вычитание байта обратное)
Эта команда выполняется так же, как Subtract Character, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Multiply Register RR 1316 MR,R1 R2 OGLE (Умножение)
Перемножаются содержимое регистра R1 и слова по исполнительному адресу; младшие 32 разряда произведения записываются в регистр R1. Для установки РПР результат в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Multiply RS 3316 M,R1 A,R2 OGLE (Умножение)
Эта команда выполняется так же, как Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Multiply Immediate IM 5316 MI,R1 I OGLE (Умножение непосредственное)
В регистр RI записываются младшие 32 разряда произведения содержимого регистра R1 на 20-разрядный непосредственный операнд I. Для установки РПР произведение в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Multiply Character СН 7316 МС, R1 А, R2 OGLE (Умножение байта)
В регистр R1 записываются младшие 32 разряда произведения содержимого регистра R1 на 8-разрядное положительное целое число, расположенное в байте по исполнительному адресу. Для установки РПР величина в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Divide Register RR 1416 DR,R1 R2 OGLE (Деление)
Содержимое регистра R1 (делимое) делится на слово по исполнительному адресу (делитель), и частное записывается в регистр R1. Деление определено таким образом, что остаток получается неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, то про происходит особый случай деления на нуль и регистр R1 не меняется.
Divide RS 3416 D, R1 A, R2 OGLE (Деление)
Эта команда выполняется так же, как Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Divide Immediate IM 5416 DI, R1 I OGLE (Деление непосредственное)
В регистр R1 записывается частное от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде. Операция определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется.
Divide Character CH 7416 DC, R1 A, R2 GLE (Деление на байт)
В регистр R1 записывается частное от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число в байте по исполнительному адресу (делитель). Частное определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется. Переполнение невозможно.
Reverse Divide Register RR 1516 RDR,R1 R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide RS 3516 RD, Rl A,R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide Immediate IM 5516 RDI,R1 I GLE (Деление непосредственное обратное)
Эта команда выполняется так же, как Divide Immediate, с тем отличием; что делимое и делитель меняются ролями.
Reverse Divide Character CH 7516 RDC,R1 A,R2 GLE (Деление на байт обратное)
Эта команда выполняется так же, как Divide Character, с тем отличием, что делимое и делитель меняются ролями.
Remainder Register RR 1616 REMR,R1 R2 GE (Остаток от деления)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на слово по исполнительному адресу (делитель). Для установки РПР остаток сравнивается с нулем. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder RS 3616 REM, R1 А, R2 GE (Остаток от деления)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Remainder Immediate IM 5616 REMI, R1 I GE (Остаток от деления непосредственного)
В регистр R1 записывается неотрицательный остаток от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде (делитель). Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder Character CH 7616 REMC, R1 A, R2 GE (Остаток от деления на байт)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число (делитель) в байте по исполнительному адресу. Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Reverse Remainder Register RR 1716 RREMR,R1 R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder RS 3716 RREM,R1 A,R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Immediate IM 5716 RREMI,R1 I GE (Остаток от деления непосредственного обратного)
Эта команда выполняется так же, как Remainder Immediate, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Character CH 7716 RREMC, R1 A, R2 GE (Остаток от деления на байт обратного)
Эта команда выполняется так же, как Remainder Character, с тем отличием, что делимое и делитель меняются ролями.
Real Add Register RR 1816 FAR,R1 R2 GLE (Сложение вещественное)
Величина в регистре R1 складывается с вещественным числом по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР сумма сравнивается с нулем. Могут иметь место особые случаи и неверной адресации слова, и некорректности вещественного представления[48]).
Real Add RS 3816 FA,R1 A,R2 GLE (Сложение вещественное)
Эта команда выполняется так же, как Rl Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Add Immediate IM 5816 FAI,R1 I GLE (Сложение вещественное непосредственное)
В регистр R1 записывается сумма величины из регистра R1 и непосредственного операнда I в коротком вещественном формате. Может иметь место особый случай некорректности вещественного представления.
Real Subtract Register RR 1916 FSR,R1 R2 GLE (Вычитание вещественное)
Из содержимого регистра Rl (уменьшаемое) вычитается вещественное число по исполнительному адресу (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова и некорректности вещественного представления.
Real Subtract RS 3916 FS,R1A,R2 GLE (Вычитание вещественное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Subtract Immediate IM 5916 FSI,R1 I GLE (Вычитание вещественное непосредственное)
Из величины в регистре R1 (уменьшаемое) вычитается непосредственный короткий вещественный операнд I (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Reverse Real Subtract Register RR 1A16 RFSR, R1 R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract RS ЗА16 RFS,R1 A,R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract Immediate IM 5A16 RFSI,R1 I GLE (Вычитание вещественное непосредственное обратное)
Эта команда такая же, как Real Subtract Immediate, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Real Multiply Register RR 1B16 FMR,R1 R2 GLE (Умножение вещественное)
Величина в регистре R1 умножается на вещественное число по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Могут иметь место особые случаи как неверной адресации слова, так и некорректности вещественного представления.
Real Multiply RS 3B16 FM, R1 A , R2 GLE (Умножение вещественное)
Эта команда такая же, как Real Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Multiply Immediate IM 5B16 FMI,R1 I GLE (Умножение вещественное непосредственное)
Величина в регистре R1 умножается на короткий вещественный непосредственный операнд I, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Real Divide Register RR 1С16 FDR,R1 R2 GLE (Деление вещественное)
Величина в регистре R1 (делимое) делится на вещественное число по исполнительному адресу (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова, некорректности вещественного представления и деления на нуль.
Real Divide RS 3C16 FD, R1 A, R2 GLE (Деление вещественное)
Эта команда такая же, как Real Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Divide Immediate IM 5C16 FDI,R1 I GLE (Деление вещественное непосредственное)
Величина в регистре R1 (делимое) делится на короткий вещественный непосредственный операнд I (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи некорректности вещественного представления и деления на нуль.
Reverse Real Divide Register RR 1D16RFDR, R1 R2 GLE (Деление вещественное обратное)
Эта команда такая же, как Real Divide Register с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide RS 3D16 RFD,R1 A,R2 GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide Immediate IM 5D16 RFDI,R1 I GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide Immediate, с тем отличием, что делимое и делитель меняются ролями.
Convert To Real Register RR 1Е16 FLOATR,R1 R2 GLE (Преобразование в вещественное)
32-разрядное целое в дополнительном коде по исполнительному адресу преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат преобразования сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Convert To Real RS 3E16 FLOAT,R1 A,R2 GLE (Преобразование в вещественное)
Эта командатакая же, как Convert To Real Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Real Immediate IM 5E16 FLOATI, R1 I GLE (Преобразование в вещественное непосредственное)
Непосредственный операнд, рассматриваемый как 20-разрядное целое в дополнительном коде, преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат сравнивается с нулем.
Convert To Integer Register RR 1F16 FIXR,R1 R2 OGLE (Преобразование в целое)
Целая часть вещественного числа в слове по исполнительному адресу преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова [49].
Convert To Integer RS 3F16 FIX, R1 A, R2 OGLE (Преобразование в целое)
Эта команда такая же, как Convert To Integer Register, если не считать того, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Integer Immediate IM 5F16 FIXI,R1 I OGLE (Преобразование в целое непосредственное)
Короткий вещественный непосредственный операнд I преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем.
Real Floor RS 7816 FLOOR, R1 A, R2 GLE (Вещественное округление с недостатком)
В регистр R1 записывается в вещественном формате ближайшее целое, не превосходящее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Real Ceiling RS 7916 CEIL,R1 A,R2 GLE (Вещественное округление с избытком)
В регистр R1 записывается в вещественном формате ближайшее целое, не меньшее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Minimum RS 7A16 MIN, R1 A, R2 LE (Минимум)
В регистр R1 записывается минимальная из величин, содержащихся в регистре R1 и слове по исполнительному адресу. Установка РПР производится в результате сравнения исходного и конечного содержимого R1. Может иметь место особый случай неверной адресации слова.
Maximum RS 7В16 МАХ, R1 А, R2 GE (Максимум)
Эта команда такая же, как Minimum, с тем отличием, что минимум заменяется на максимум.
Shift Logical RS 7C16 SHIFTL,R1 A,R2 OGLE (Сдвиг логический)
Исполнительный адрес рассматривается как 16-разрядное число в дополнительном коде, называемое счетчиком сдвига. Содержимое регистра R1 сдвигается на число разрядов, равное значению счетчика сдвига, сдвиг происходит влево при положительном значении счетчика и вправо — при отрицательном. Разряды, выталкиваемые за границы регистра, теряются. При потере хотя бы одного единичного разряда в РПР устанавливается О-бит. Для установки в РПР остальных разрядов результат сравнивается с нулем[50]).
Shift Circular RS 7D16 SHIFTC,R1 A,R2 GLE (Сдвиг циклический)
Эта команда работает так же, как Shift Logical, с тем отличием, что разряды, выталкиваемые за пределы регистра, занимают освобождающиеся позиции с другой стороны. Переполнение произойти не может.
Shift Arithmetic RS 7E16 SHIFTA,R1 A,R2 OGLE (Сдвиг арифметический)
Эта команда работает аналогично команде Shift Logical при сдвигах влево, а при сдвигах вправо освободившимся разрядам присваивается значение нулевого разряда. Если при сдвиге влево бит, выдвинутый в знаковый разряд, отличается от последнего, происходит переполнение.
Shift Real RS 7F16 SHIFTR,R1 A,R2 GLE (Сдвиг вещественный)
Исполнительный адрес рассматривается как 16-разрядный счетчик сдвига в дополнительном коде. Мантисса абсолютного значения вещественного числа в регистре R1 сдвигается влево или вправо на 4 разряда, освободившиеся позиции заполняются нулями. Если в итоге мантисса равна нулю, значит, таков результат. В противном случае из порядка вычитается значение счетчика сдвига и полученная величина записывается с исходным знаком в регистр R1. Переполнение произойти не может, но возможен особый случай некорректности вещественного представления. Для установки РПР результат сравнивается с нулем.
Рисунок 25.3. Форматы представления информации,
2. Регистр-память. Обычно в командах типа регистр-память в разрядах с 8-го по 11-й указывается регистр или 4-разрядная маска, и они выступают в качестве одного из операндов. Остальная часть команды используется для формирования исполнительного адреса по следующему правилу:
— Если косвенный бит равен 0 и указатель индекс-регистра (разряды с 12-го по 15-й) равен 0, то исполнительный адрес дается полем адреса (разряды с 16-го по 31-й) команды.
— Если косвенный бит равен нулю, а указатель индекс-регистра нулю не равен, то адресная часть команды дополняется слева нулями и складывается (разумеется, в дополнительном коде) с содержимым индекс-регистра. Разряды 16—31 результата образуют исполнительный адрес. Содержимое индекс-регистра не изменяется,
— Если косвенный бит не нуль, а указатель индекс регистра — нуль, адресное поле указывает местонахождение в памяти двухбайтового косвенного поля. Содержимое косвенного поля образует исполнительный адрес. Если косвенное поле начинается не с границы четного байта, происходит особый случай некорректной косвенной адресации.
— Если косвенный бит и указатель индекс-регистра не равны нулю, косвенное поле складывается с содержимым индекс-регистра и в качестве исполнительного адреса берутся правые 16 разрядов суммы. При этом может иметь место особый случай некорректной косвенной адресации.
3. Непосредственная. Во всех непосредственных командах регистр указывается в разрядах с 8-го по 11-й, а в разрядах 12—31 содержится непосредственный операнд. В качестве непосредственного операнда может выступать 20-разрядное целое в дополнительном коде, 20-разрядный логический вектор или же действительное число в коротком формате. В командах с непосредственным операндом косвенный бит игнорируется.
4. Байтовая. Команды байтового типа выполняются аналогично командам типа регистр-память.
Описание команд
Опишем в этом разделе каждую команду. В первой строке описания приводится краткая справка, состоящая из названия команды, ее формата (RR, RS, IM, СН[43]), шестнадцатеричного кода операции, записи команды на языке ассемблера[44] и перечисления разрядов регистра признака результата, которые могут командой изменяться. Затем следует словесное описание. Содержимое РПР, устанавливаемое в результате выполнения команды, обозначает- обозначается символами О, L, G, Е[45]) или Нет (указание на то, что РПР не изменяется).
Load Register RR 0016 LR,R1 R2 GLE (Загрузка регистра)
В регистр R1 пересылается содержимое слова по исполнительному адресу. Пересылаемое значение сравнивается с нулем, и в РПР устанавливается соответствующий разряд: G, L или Е[46]). Если исполнительный адрес не попадает на границу слова, происходит особый случай неверной адресации слова.
Load RS 2016 L, R1A, R2 GLE (Загрузка)
Эта команда выполняется аналогично команде Load Register с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Immediate IM 4016 LI,R1 I GLE (Загрузка непосредственная)
Эта команда выполняется так же, как Load Register, с той разницей, что пересылаемая величина является непосредственным операндом I, при этом его знаковый разряд размножается на 12 битов влево. Особых случаев произойти не может.
Load Character СН 6016 LC, R1 А, R2 GE (Загрузка байта)
Регистр R1 обнуляется, и байт по исполнительному адресу записывается в его разряды 24—31. Производится сравнение пересылаемой величины с нулем, и в РПР устанавливаются разряды G или Е.
Load Negative Register RR 0116 LNR, R1 R2 OGLE (Загрузка регистра отрицательная)
В регистр R1 засылается дополнительный код слова по исполнительному адресу. Результат сравнивается с нулем и устанавливается РПР. При переполнении в РПР устанавливается лишь разряд 0. Может иметь место особый случай неверной адресации слова.
Load Negative RS 2116 LN, R1A,R2 OGLE (Загрузка отрицательная)
Эта команда выполняется так же, как Load Negative Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Load Negative Immediate IM 4116 LNI,R1 I GLE (Загрузка непосредственная отрицательная)
В регистр R1 помещается 32-разрядное двоичное дополнение 20-разрядного непосредственного операнда I, заданного в дополнительном коде. Переполнение произойти не может. Установка РПР осуществляется сравнением результата с нулем.
Load Negative Character CH 6116 LNC,R1 A,R2 LE (Загрузка байта отрицательная)
Байт по исполнительному адресу дополняется слева нулями до 32 разрядов и дополнительный код полученного слова помещается в регистр R1. Переполнения произойти не может. Для установки РПР полученная величина сравнивается с нулем.
Store Register RR 0216 STR, R1 R2 GLE (Запись регистра)
Содержимое R1 запоминается в слове по исполнительному адресу. Результат сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Store RS 2216 ST, R1 A, R2 GLE (Запись в память)
Эта команда выполняется так же, как команда Store Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Store Character CH 6216 STC, R1 A,R2 GE (Запись в память байта)
Разряды 24—31 регистра R1 помещаются в байт по исполнительному адресу. Для установки РПР занесенная величина сравнивается с нулем.
Swap Register RR 0316 SWAPR, R1 R2 GLE (Обмен)
Содержимое регистра Rl и слова по исполнительному адресу меняются местами. Новая величина в R1 сравнивается с нулем, и устанавливается РПР. Может произойти особый случай неверной адресации слова.
Swap RS 2316 SWAP,R1 A,R2 GLE (Обмен с памятью)
Эта команда выполняется так же, как команда Swap Register, но исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Swap Character CH 6316 SWAPC, R1 А, R2 GE (Обмен с байтом)
Разряды 24—31 регистра R1 меняются местами с байтом по исполнительному адресу. РПР устанавливается при сравнении нового содержимого R1 с нулем. Разряды с 0-го по 23-й регистра R1 не изменяются,
And Register RR 0416 ANDR,R1 R2 GLE (И)
В регистр R1 помещается поразрядное логическое произведение (И) содержимого R1 и слова по исполнительному адресу. Если все разряды результата состоят из единиц, то в РПР устанавливается G, если из нулей — то Е, иначе — L, Может иметь место особый случай неверной адресации слова.
And RS 2416 AND,R1A,R2 GLE (И)
Эта команда выполняется аналогично And Register с тем отличием, что для определения исполнительного адреса используется правило адресации команд типа регистр-память.
And Immediate IM 4416 ANDI,R1 I LE (И)
В регистре R1 помещается поразрядное логическое произведение (И) содержимого R1 и непосредственно указанной величины I, дополненной слева 12 нулевыми разрядами. РПР устанавливается так же, как в команде And Register.
And Character CH 6416 ANDC,R1 A,R2 GLE (И)
В регистре R1 разряды 24—31 заменяются их логическим произведением на байт по исполнительному адресу. Разряды 0—23 регистра R1 не изменяются. РПР устанавливается так же, как в команде And Register.
Or Register RR 0516 ORR, R1 R2 GLE (ИЛИ)
Эта команда выполняется так же, как And Register, но логическое И заменяется логическим ИЛИ.
Or RS 2516 OR, R1A, R2 GLE (ИЛИ)
Эта команда выполняется так же, как And, но логическое И заменяется логическим ИЛИ.
Or Immediate LM 4516 ORI,R1 I GLE (ИЛИ)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется логическим ИЛИ.
Or Character СН 6516 ORC,R1 А R2 (ИЛИ)
Эта команда выполняется так же, как And Character, но логическое И заменяется логическим ИЛИ.
Exclusive Or Register RR 0616 XORR,R1 R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Register, но логическое И заменяется исключающим ИЛИ.
Exclusive Or RS 2616 XOR,R1 A,R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Immediate IM 4616 XORI,R1 I GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется исключающим ИЛИ.
Exclusive Or Character CH 6616 XORC,R1 A,R2 GLE (Исключающее ИЛИ)
Эта команда выполняется так же, как And Character, но логическое И заменяется исключающим ИЛИ.
Not Register RR 0716 NOTR, Rl R2 GLE (Отрицание)
Эта команда выполняется так же, как And Register, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not RS 2716 NOT,R1A, R2 GLE (Отрицание)
Эта команда выполняется так же, как And, но логическое И заменяется логическим отрицанием второго операнда. Исходное содержимое R1 игнорируется.
Not Immediate IM 4716 NOTI,R1 I GLE (Отрицание)
Эта команда выполняется так же, как And Immediate, но логическое И заменяется логическим отрицанием расширенного второго операнда. Исходное содержимое R1 игнорируется.
Not Character CH 6716 NOTC,R1 A,R2 GLE (Отрицание)
Эта команда выполняется так же, как And Character, но логическое И заменяется логическим отрицанием второго операнда. Содержимое разрядов 24—31 регистра R1 игнорируется.
Branch Conditions Set Register RR 0816 BCSR,M1 R2 Нет (Условный переход по единице)
Если логическое произведение содержимого РПР и 4-разрядной маски M1 не равно нулю, содержимое САК замещается исполнительным адресом,
Branch Conditions Set RS 2816 BCS,M1 A,R2 Нет (Условный переход по единице)
Эта команда выполняется так же, как Branch Conditions Set Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch Conditions Reset Register RR 0916 BCRR,M1 R2 Нет (Условный переход по нулю)
Если логическое произведение содержимого РПР и 4-разрядной маски M1 равно нулю, содержимое САК замещается исполнительным адресом.
Branch Conditions Reset RS 2916 BCR,M1 A,R2 Нет (Условный переход по нулю)
Эта команда выполняется так же, как Branch Conditions Reset Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Branch and Link Register RR 0A16 BALR,R1 R2 Нет (Переход с возвратом)
Текущее содержимое САК засылается в регистр R1, а исполнительный адрес команды помещается в САК. Если признак косвенной адресации не задан, исполнительный адрес равен указателю регистра R2, умноженному на 4.
Branch and Link RS 2A16 BAL,R1 A,R2 Нет (Переход с возвратом)
Текущее содержимое САК заносится в регистр R1, а в САК засылается исполнительный адрес команды.
Save Condition Register RR 0B16 SACR,M1 R2 Нет (Сохранение состояния)
Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается слово, состоящее из всех единиц; в противном случае записывается нулевое слово. Может иметь место особый случай неверной адресации слова.
Save Condition RS 2В16 SAC, М1 А, R2 Нет (Сохранение состояния)
Эта команда выполняется так же, как команда Save Condition Register, с тем отличием, что исполнительный адрес вычисляется с помощью правила адресации команд типа регистр-память.
Save Condition Character CH 6B16 SACC,M1 A,R2 Нет (Сохранение состояния)
Если логическое произведение И содержимого РПР и 4-разрядного поля маски M1 отлично от нуля, по исполнительному адресу записывается байт, состоящий из всех единиц; в противном случае записывается нулевой байт.
Compare Register RR 0С16 CR,R1 R2 GLE (Сравнение)
В результате арифметического сравнения содержимого регистра R1 и слова по исполнительному адресу в РПР устанавливается соответствующий разряд: G, L или Е. Может иметь место особый случай неверной адресации слова.
Compare RS 2С16 С , R1 A , R2 GLE (Сравнение)
Эта команда выполняется так же, как Compare Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Compare Immediate IM 4C16 CI,R1 I GLE (Сравнение непосредственное)
Содержимое 32-разрядного регистра R1 арифметически сравнивается с полным словом, образованным из непосредственного операнда размножением его знакового разряда на 12 позиций влево. Вырабатывается соответствующий признак результата, и разряд G, L или Е устанавливается в РПР.
Compare Character CH 6C16 CC,R1 A,R2 GLE (Сравнение байтов)
Содержимое разрядов 24—31 регистра R1 сравнивается как 8-разрядное целое положительное число с байтом по исполнительному адресу. Вырабатывается соответствующий признак результата, и в РПР устанавливается разряд G, L или Е.
Compare Character String RR 0E16 CCS,M1 R2 GLE (Сравнение цепочки байтов)
Указатель регистра R2 обозначает пару регистров R2 и (R2+1)mod16 (второй регистр будем везде называть R2+1). В двойном слове, образованном парой R2 и R2+1 должно содержаться описание цепочки, а именно в разрядах 16—31 регистра R2 указывается адрес байта А1, в разрядах 0—15 регистра R2+1 — длина цепочки L и в разрядах 16—31 регистра R2 +1 — адрес байта А2. Для выполнения команды величины A1, A2 и L помещаются во внутренние регистры, РПР обнуляется и Е-бит РПР устанавливается в единицу. Затем отрабатывает следующий цикл.
1. Если L=0, то разряды 0—15 обоих регистров обнуляются, в 16—31-й разряды R2 из в внутренних регистров переносится А1, а в 16—31-й разряды R2+1 переносится А2, и выполнение команды заканчивается.
2. Байты по А1 и А2 сравниваются как 8-разрядные целые числа, и в РПР устанавливается соответствующий признак результата.
3. Если Е-бит РПР не равен единице, то 0—15-й разряды регистра R2 обнуляются, а из внутренних регистров в 16—31-й разряды R2 пересылается А1, в 0—15-й разряды R2+1 — длина L и в 16—31-й разряды R2+1 — адрес А2, и команда завершается.
4. L уменьшается на 1, адрес А1 увеличивается на величину маски M1, представляющую собой 4-разрядное целое в дополнительном коде, А2 увеличивается на 1, и цикл повторяется с первого шага.
Move Character String RR 0F16 MCS,M1 R2 Нет (Пересылка цепочки байтов)
В двойном слове R2 и (R2 +1)mod16 содержится описание цепочки в виде, описанном в команде Compare Character String. Поля L, A1 и А2 загружаются во внутренние регистры. Затем выполняется цикл.
1. Если L=0, разряды 0—15 регистров R2 и R2+1 очищаются, в 16—31-й разряды R2 помещается текущее А1, в 16—31-й разряды R2+1—значение А2, и выполнение команды завершается.
2. Байт по адресу А1 пересылается в байт по А2.
3. L уменьшается на 1, а А2 увеличивается на 1.
4. А1 увеличивается на величину маски M1, рассматриваемую как 4-разрядное целое число в дополнительном коде, и цикл возвращается к первому шагу.
Supervisor Call RS 2E16 SVC,R1 A,R2 Нет (Обращение к супервизору)
Выполнение программы прерывается, и управление передается в управляющую программу супервизора.
Execute RS 2F16 EX , R1 A, R2 Нет (Выполнить)
Выполняется команда, содержащаяся по исполнительному адресу. Результаты ее исполнения становятся таковыми для данной команды Execute. Если исполнительный адрес команды Execute нечетный, имеет место особый случай некорректности команды Execute. Глубина вложений команды Execute может быть любой. Заметим, что изменение САК происходит только в случае, когда это явным образом производится в подчиненной команде.
Load Adress RS 4E16 LA,R1 A,R2 Нет (Загрузка адреса)
Исполнительный адрес команды помещается в регистр R1
Load Multiple RS 6E16 LM,R1A,R2 Нет (Загрузка групповая)
В регистры от R1 до R2 загружается содержимое последовательных слов памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше, чем R1, то загружаются регистры от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Store Multiple RS 6F16 STM,R1A,R2 Нет (Запись групповая)
Содержимое регистров от R1 до R2 записывается в последовательные слова памяти, начиная со слова по исполнительному адресу (исполнительный адрес вычисляется в предположении, что указан нулевой индекс-регистр). Если R2 меньше R1, то записывается содержимое регистров от R1 до 15 и от 0 до R2. Может иметь место особый случай неверной адресации слова.
Add Register RR 1016 AR,R1 R2 OGLE (Сложение)
Слово в регистре R1 складывается со словом по исполнительному адресу, и результат помещается в R1. Для установки РПР сумма сравнивается с нулем. В случае переполнения в РПР устанавливается лишь О-бит. Может иметь место особый случай неверной адресации слова.
Add RS 3016 A,R1 A,R2 OGLE (Сложение)
Эта команда выполняется так же, как Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Add Immediate IM 5016 AI,R1 I OGLE (Сложение непосредственное)
20-разрядный непосредственный операнд I, заданный в дополнительном коде, складывается с содержимым регистра R1, и сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Add Character CH 7016 AC, R1 A, R2 OGLE (Сложение байта)
Байт по исполнительному адресу дополняется слева 24 нулевыми разрядами и складывается с содержимым регистра R1, причем сумма помещается в R1. Для установки РПР сумма сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Register RR 1116 SR,R1 R2 OGLE (Вычитание)
Слово по исполнительному адресу (вычитаемое) вычитается из содержимого регистра R1 (уменьшаемое), и разность записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Subtract RS 3116 S,R1 A,R2 OGLE (Вычитание)
Эта команда выполняется так же, как Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Subtract Immediate IМ 5116 SI, R1 I OGLE (Вычитание непосредственное)
Из содержимого регистра R1 (уменьшаемое) вычитается 20-разрядный непосредственный операнд (вычитаемое), рассматриваемый как целое в дополнительном коде, и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Subtract Character CH 7116 SC,R1 A,R2 OGLE (Вычитание байта)
Из содержимого регистра R1 (уменьшаемое) вычитается байт по исполнительному адресу, дополненный слева 24 нулевыми разрядами (вычитаемое), который трактуется как положительное целое число. Результат записывается в R1. Для установки РПР разность сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Reverse Subtract Register RR 1216 RSR,R1 R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как команда Subtract Register, с тем отличием, что вычитаемое и уменьшаемое меняются ролями[47]).
Reverse Subtract RS 3216 RS,R1 A,R2 OGLE (Вычитание обратное)
Эта команда выполняется так же, как Subtract, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Immediate IM 5216 RSI,R1 I OGLE (Вычитание непосредственное обратное)
Эта команда выполняется так же, как Subtract Immediate, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Reverse Subtract Character CH 7216 RSC,R1 A,R2 OGLE (Вычитание байта обратное)
Эта команда выполняется так же, как Subtract Character, с тем отличием, что вычитаемое и уменьшаемое меняются ролями.
Multiply Register RR 1316 MR,R1 R2 OGLE (Умножение)
Перемножаются содержимое регистра R1 и слова по исполнительному адресу; младшие 32 разряда произведения записываются в регистр R1. Для установки РПР результат в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова.
Multiply RS 3316 M,R1 A,R2 OGLE (Умножение)
Эта команда выполняется так же, как Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Multiply Immediate IM 5316 MI,R1 I OGLE (Умножение непосредственное)
В регистр RI записываются младшие 32 разряда произведения содержимого регистра R1 на 20-разрядный непосредственный операнд I. Для установки РПР произведение в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Multiply Character СН 7316 МС, R1 А, R2 OGLE (Умножение байта)
В регистр R1 записываются младшие 32 разряда произведения содержимого регистра R1 на 8-разрядное положительное целое число, расположенное в байте по исполнительному адресу. Для установки РПР величина в R1 сравнивается с нулем. При переполнении в РПР устанавливается только О-бит.
Divide Register RR 1416 DR,R1 R2 OGLE (Деление)
Содержимое регистра R1 (делимое) делится на слово по исполнительному адресу (делитель), и частное записывается в регистр R1. Деление определено таким образом, что остаток получается неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, то про происходит особый случай деления на нуль и регистр R1 не меняется.
Divide RS 3416 D, R1 A, R2 OGLE (Деление)
Эта команда выполняется так же, как Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Divide Immediate IM 5416 DI, R1 I OGLE (Деление непосредственное)
В регистр R1 записывается частное от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде. Операция определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. При переполнении в РПР устанавливается только О-бит. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется.
Divide Character CH 7416 DC, R1 A, R2 GLE (Деление на байт)
В регистр R1 записывается частное от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число в байте по исполнительному адресу (делитель). Частное определяется таким образом, чтобы остаток от деления был неотрицательным. Для установки РПР частное сравнивается с нулем. Если делитель равен нулю, то происходит особый случай деления на нуль и регистр R1 не изменяется. Переполнение невозможно.
Reverse Divide Register RR 1516 RDR,R1 R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide RS 3516 RD, Rl A,R2 OGLE (Деление обратное)
Эта команда выполняется так же, как Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Divide Immediate IM 5516 RDI,R1 I GLE (Деление непосредственное обратное)
Эта команда выполняется так же, как Divide Immediate, с тем отличием; что делимое и делитель меняются ролями.
Reverse Divide Character CH 7516 RDC,R1 A,R2 GLE (Деление на байт обратное)
Эта команда выполняется так же, как Divide Character, с тем отличием, что делимое и делитель меняются ролями.
Remainder Register RR 1616 REMR,R1 R2 GE (Остаток от деления)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на слово по исполнительному адресу (делитель). Для установки РПР остаток сравнивается с нулем. Может иметь место особый случай неверной адресации слова. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder RS 3616 REM, R1 А, R2 GE (Остаток от деления)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Remainder Immediate IM 5616 REMI, R1 I GE (Остаток от деления непосредственного)
В регистр R1 записывается неотрицательный остаток от деления содержимого R1 (делимое) на значение 20-разрядного непосредственного операнда I в дополнительном коде (делитель). Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Remainder Character CH 7616 REMC, R1 A, R2 GE (Остаток от деления на байт)
В регистр R1 записывается неотрицательный остаток от деления содержимого регистра R1 (делимое) на положительное 8-разрядное целое число (делитель) в байте по исполнительному адресу. Для установки РПР остаток сравнивается с нулем. Если делитель равен нулю, происходит особый случай деления на нуль и регистр R1 не изменяется.
Reverse Remainder Register RR 1716 RREMR,R1 R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder Register, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder RS 3716 RREM,R1 A,R2 GE (Остаток от деления обратного)
Эта команда выполняется так же, как Remainder, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Immediate IM 5716 RREMI,R1 I GE (Остаток от деления непосредственного обратного)
Эта команда выполняется так же, как Remainder Immediate, с тем отличием, что делимое и делитель меняются ролями.
Reverse Remainder Character CH 7716 RREMC, R1 A, R2 GE (Остаток от деления на байт обратного)
Эта команда выполняется так же, как Remainder Character, с тем отличием, что делимое и делитель меняются ролями.
Real Add Register RR 1816 FAR,R1 R2 GLE (Сложение вещественное)
Величина в регистре R1 складывается с вещественным числом по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР сумма сравнивается с нулем. Могут иметь место особые случаи и неверной адресации слова, и некорректности вещественного представления[48]).
Real Add RS 3816 FA,R1 A,R2 GLE (Сложение вещественное)
Эта команда выполняется так же, как Rl Add Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Add Immediate IM 5816 FAI,R1 I GLE (Сложение вещественное непосредственное)
В регистр R1 записывается сумма величины из регистра R1 и непосредственного операнда I в коротком вещественном формате. Может иметь место особый случай некорректности вещественного представления.
Real Subtract Register RR 1916 FSR,R1 R2 GLE (Вычитание вещественное)
Из содержимого регистра Rl (уменьшаемое) вычитается вещественное число по исполнительному адресу (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова и некорректности вещественного представления.
Real Subtract RS 3916 FS,R1A,R2 GLE (Вычитание вещественное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Subtract Immediate IM 5916 FSI,R1 I GLE (Вычитание вещественное непосредственное)
Из величины в регистре R1 (уменьшаемое) вычитается непосредственный короткий вещественный операнд I (вычитаемое), и результат записывается в регистр R1. Для установки РПР разность сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Reverse Real Subtract Register RR 1A16 RFSR, R1 R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract Register, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract RS ЗА16 RFS,R1 A,R2 GLE (Вычитание вещественное обратное)
Эта команда такая же, как Real Subtract, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Reverse Real Subtract Immediate IM 5A16 RFSI,R1 I GLE (Вычитание вещественное непосредственное обратное)
Эта команда такая же, как Real Subtract Immediate, с тем отличием, что уменьшаемое и вычитаемое меняются ролями.
Real Multiply Register RR 1B16 FMR,R1 R2 GLE (Умножение вещественное)
Величина в регистре R1 умножается на вещественное число по исполнительному адресу, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Могут иметь место особые случаи как неверной адресации слова, так и некорректности вещественного представления.
Real Multiply RS 3B16 FM, R1 A , R2 GLE (Умножение вещественное)
Эта команда такая же, как Real Multiply Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Multiply Immediate IM 5B16 FMI,R1 I GLE (Умножение вещественное непосредственное)
Величина в регистре R1 умножается на короткий вещественный непосредственный операнд I, и результат записывается в регистр R1. Для установки РПР произведение сравнивается с нулем. Может иметь место особый случай некорректности вещественного представления.
Real Divide Register RR 1С16 FDR,R1 R2 GLE (Деление вещественное)
Величина в регистре R1 (делимое) делится на вещественное число по исполнительному адресу (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи неверной адресации слова, некорректности вещественного представления и деления на нуль.
Real Divide RS 3C16 FD, R1 A, R2 GLE (Деление вещественное)
Эта команда такая же, как Real Divide Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Real Divide Immediate IM 5C16 FDI,R1 I GLE (Деление вещественное непосредственное)
Величина в регистре R1 (делимое) делится на короткий вещественный непосредственный операнд I (делитель), и результат записывается в регистр R1. Для установки РПР частное сравнивается с нулем. Могут иметь место особые случаи некорректности вещественного представления и деления на нуль.
Reverse Real Divide Register RR 1D16RFDR, R1 R2 GLE (Деление вещественное обратное)
Эта команда такая же, как Real Divide Register с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide RS 3D16 RFD,R1 A,R2 GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide, с тем отличием, что делимое и делитель меняются ролями.
Reverse Real Divide Immediate IM 5D16 RFDI,R1 I GLE (Деление вещественное непосредственное обратное)
Эта команда такая же, как Real Divide Immediate, с тем отличием, что делимое и делитель меняются ролями.
Convert To Real Register RR 1Е16 FLOATR,R1 R2 GLE (Преобразование в вещественное)
32-разрядное целое в дополнительном коде по исполнительному адресу преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат преобразования сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Convert To Real RS 3E16 FLOAT,R1 A,R2 GLE (Преобразование в вещественное)
Эта командатакая же, как Convert To Real Register, с тем отличием, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Real Immediate IM 5E16 FLOATI, R1 I GLE (Преобразование в вещественное непосредственное)
Непосредственный операнд, рассматриваемый как 20-разрядное целое в дополнительном коде, преобразуется в формат вещественного числа и записывается в регистр R1. Для установки РПР результат сравнивается с нулем.
Convert To Integer Register RR 1F16 FIXR,R1 R2 OGLE (Преобразование в целое)
Целая часть вещественного числа в слове по исполнительному адресу преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова [49].
Convert To Integer RS 3F16 FIX, R1 A, R2 OGLE (Преобразование в целое)
Эта команда такая же, как Convert To Integer Register, если не считать того, что исполнительный адрес вычисляется по правилу адресации команд типа регистр-память.
Convert To Integer Immediate IM 5F16 FIXI,R1 I OGLE (Преобразование в целое непосредственное)
Короткий вещественный непосредственный операнд I преобразуется в 32-разрядное целое в дополнительном коде и записывается в регистр R1. При переполнении результат обнуляется и в РПР устанавливается О-бит. Для установки в РПР других разрядов результат сравнивается с нулем.
Real Floor RS 7816 FLOOR, R1 A, R2 GLE (Вещественное округление с недостатком)
В регистр R1 записывается в вещественном формате ближайшее целое, не превосходящее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Real Ceiling RS 7916 CEIL,R1 A,R2 GLE (Вещественное округление с избытком)
В регистр R1 записывается в вещественном формате ближайшее целое, не меньшее вещественного числа по исполнительному адресу. Для установки РПР результат сравнивается с нулем. Может иметь место особый случай неверной адресации слова.
Minimum RS 7A16 MIN, R1 A, R2 LE (Минимум)
В регистр R1 записывается минимальная из величин, содержащихся в регистре R1 и слове по исполнительному адресу. Установка РПР производится в результате сравнения исходного и конечного содержимого R1. Может иметь место особый случай неверной адресации слова.
Maximum RS 7В16 МАХ, R1 А, R2 GE (Максимум)
Эта команда такая же, как Minimum, с тем отличием, что минимум заменяется на максимум.
Shift Logical RS 7C16 SHIFTL,R1 A,R2 OGLE (Сдвиг логический)
Исполнительный адрес рассматривается как 16-разрядное число в дополнительном коде, называемое счетчиком сдвига. Содержимое регистра R1 сдвигается на число разрядов, равное значению счетчика сдвига, сдвиг происходит влево при положительном значении счетчика и вправо — при отрицательном. Разряды, выталкиваемые за границы регистра, теряются. При потере хотя бы одного единичного разряда в РПР устанавливается О-бит. Для установки в РПР остальных разрядов результат сравнивается с нулем[50]).
Shift Circular RS 7D16 SHIFTC,R1 A,R2 GLE (Сдвиг циклический)
Эта команда работает так же, как Shift Logical, с тем отличием, что разряды, выталкиваемые за пределы регистра, занимают освобождающиеся позиции с другой стороны. Переполнение произойти не может.
Shift Arithmetic RS 7E16 SHIFTA,R1 A,R2 OGLE (Сдвиг арифметический)
Эта команда работает аналогично команде Shift Logical при сдвигах влево, а при сдвигах вправо освободившимся разрядам присваивается значение нулевого разряда. Если при сдвиге влево бит, выдвинутый в знаковый разряд, отличается от последнего, происходит переполнение.
Shift Real RS 7F16 SHIFTR,R1 A,R2 GLE (Сдвиг вещественный)
Исполнительный адрес рассматривается как 16-разрядный счетчик сдвига в дополнительном коде. Мантисса абсолютного значения вещественного числа в регистре R1 сдвигается влево или вправо на 4 разряда, освободившиеся позиции заполняются нулями. Если в итоге мантисса равна нулю, значит, таков результат. В противном случае из порядка вычитается значение счетчика сдвига и полученная величина записывается с исходным знаком в регистр R1. Переполнение произойти не может, но возможен особый случай некорректности вещественного представления. Для установки РПР результат сравнивается с нулем.
Особые случаи и обращения к супервизору
В современных компьютерах организация ввода/вывода по крайней мере столь же сложна, как центральный процессор. Чтобы не увеличивать в два раза объем задачи, предположим, что супервизор управляет прохождением каждой задачи пользователя. Таблица 25.1 Сводка кодов операций Обращения к супервизору могут осуществляться как непосредственно при помощи команды вызова супервизора Supervisor Call, так и косвенным образом — при возникновении особых случаев. Различные поля команды Supervisor Call используется для задания требуемых действий и передачи параметров. Далее представлен минимальный набор действий супервизора в зависимости от содержимого указателя регистра R1.
R1 = 0 — Завершить выполнение программы и произвести после нее «чистку мусора»
R1 = 1 — Прочитать из входного потока целое число и записать его по исполнительному адресу команды SVC (адрес должен указывать на слово).
R1 = 2 — Прочитать вещественное число и записать его по исполнительному адресу.
R1 = 3 —Прочитать литеру и записать по исполнительному адресу.
R1 = 4 — Перейти во входном потоке к новой записи.
R1 = 5 — Слово по исполнительному адресу записать в выходной поток в виде целого числа.
R1 = 6 — Слово по исполнительному адресу записать в выходной поток в виде вещественного числа.
R1 = 7 —Байт по исполнительному адресу записать в выходной поток в виде литеры.
R1 = 8 —Записать в выходной поток признак конца записи.
R1 = 9 и R2 = 0 —Закончить трассировку выполнения команд.
R1 = 9 и R2 = 1 — Начать трассировку выполнения команд. Печатать текущую информацию о каждой выполняемой команде.
R1 = А — Исполнительный адрес команды SVC должен быть адресом слова. Правое полуслово указывает адрес начала, а левое — адрес конца участка памяти для дампа. Программа дампа должна выдавать содержимое памяти в указанных пределах как в шестнадцатеричном, так и в текстовом формате. Возможно, окажется полезным выводить также мнемонику команд. Идущие подряд одинаковые строки программа дампа должна распознавать и печатать одну из них.
R1 = F — Данный вызов супервизора никогда не будет предназначаться для системного применения и может быть использован в имитаторе для любых целей.
Предполагается, что целые и вещественные числа во входном и выходном потоках заканчиваются пробелами.
Особые случаи имеют место, когда в процессе выполнения команд возникают ошибки. При этом выполнение программы прерывается и супервизор извещается о причине прерывания и адресе команды, вызвавшей прерывание. Приведем вкратце перечень особых случаев.
Запрещенный адрес команды — на начало цикла выполнения команды адрес в САК — нечетный.
Некорректная команда — команда с данным кодом операции отсутствует.
Некорректная косвенная адресация — косвенный адрес — нечетный.
Неверная адресация слова — адрес слова, указанный в операнде команды, не делится на четыре.
Некорректность вещественного представления — результат некоторой операции, определяющей вещественное значение, не может быть представлен в формате нормализованного вещественного числа.
Некорректность команды Execute — исполнительный адрес команды Execute — нечетный.
Деление на нуль — в операциях деления или нахождения остатка делитель равен нулю.
Зацикливание кода операции — четырехбайтовая команда начинается с FFFE.
Реакция супервизора на особый случай оставляется на усмотрение исполнителя, она должна лишь включать в себя сообщение пользователю о происшедшем событии.
Обращения к супервизору могут осуществляться как непосредственно при помощи команды вызова супервизора Supervisor Call, так и косвенным образом — при возникновении особых случаев. Различные поля команды Supervisor Call используется для задания требуемых действий и передачи параметров. Далее представлен минимальный набор действий супервизора в зависимости от содержимого указателя регистра R1.
R1 = 0 — Завершить выполнение программы и произвести после нее «чистку мусора»
R1 = 1 — Прочитать из входного потока целое число и записать его по исполнительному адресу команды SVC (адрес должен указывать на слово).
R1 = 2 — Прочитать вещественное число и записать его по исполнительному адресу.
R1 = 3 —Прочитать литеру и записать по исполнительному адресу.
R1 = 4 — Перейти во входном потоке к новой записи.
R1 = 5 — Слово по исполнительному адресу записать в выходной поток в виде целого числа.
R1 = 6 — Слово по исполнительному адресу записать в выходной поток в виде вещественного числа.
R1 = 7 —Байт по исполнительному адресу записать в выходной поток в виде литеры.
R1 = 8 —Записать в выходной поток признак конца записи.
R1 = 9 и R2 = 0 —Закончить трассировку выполнения команд.
R1 = 9 и R2 = 1 — Начать трассировку выполнения команд. Печатать текущую информацию о каждой выполняемой команде.
R1 = А — Исполнительный адрес команды SVC должен быть адресом слова. Правое полуслово указывает адрес начала, а левое — адрес конца участка памяти для дампа. Программа дампа должна выдавать содержимое памяти в указанных пределах как в шестнадцатеричном, так и в текстовом формате. Возможно, окажется полезным выводить также мнемонику команд. Идущие подряд одинаковые строки программа дампа должна распознавать и печатать одну из них.
R1 = F — Данный вызов супервизора никогда не будет предназначаться для системного применения и может быть использован в имитаторе для любых целей.
Предполагается, что целые и вещественные числа во входном и выходном потоках заканчиваются пробелами.
Особые случаи имеют место, когда в процессе выполнения команд возникают ошибки. При этом выполнение программы прерывается и супервизор извещается о причине прерывания и адресе команды, вызвавшей прерывание. Приведем вкратце перечень особых случаев.
Запрещенный адрес команды — на начало цикла выполнения команды адрес в САК — нечетный.
Некорректная команда — команда с данным кодом операции отсутствует.
Некорректная косвенная адресация — косвенный адрес — нечетный.
Неверная адресация слова — адрес слова, указанный в операнде команды, не делится на четыре.
Некорректность вещественного представления — результат некоторой операции, определяющей вещественное значение, не может быть представлен в формате нормализованного вещественного числа.
Некорректность команды Execute — исполнительный адрес команды Execute — нечетный.
Деление на нуль — в операциях деления или нахождения остатка делитель равен нулю.
Зацикливание кода операции — четырехбайтовая команда начинается с FFFE.
Реакция супервизора на особый случай оставляется на усмотрение исполнителя, она должна лишь включать в себя сообщение пользователю о происшедшем событии.
Файлы абсолютной загрузки
Файл абсолютной загрузки описывает содержимое памяти УМ-1 перед выполнением программы. Обычно такие файлы получаются с помощью загрузчика УМ из перемещаемого языка загрузки, и в практически работающих системах такие файлы для экономии места в памяти, как правило, представляются в некотором двоичном формате. В нашем случае мы опишем формат, который можно отперфорировать, что облегчает процесс отладки. Каждая из записей физического файла состоит из 80 внешних литер, при этом допустимыми являются цифры, буквы А, В, С, D, E, F, N и пробел. Чаще всего эти внешние литеры будут объединяться в группы, образуя шестнадцатеричные числа. Заметим, что для образования одного двухразрядного шестнадцатеричного числа требуются две внешние литеры, и это в свою очередь как раз обеспечивает заполнение позиции одной внутренней литеры (байта) УМ-1). [51] Любая запись, кроме последней, имеет стандартный формат. Литера 1 представляет собой контрольную сумму всех остальных шестнадцатеричных цифр, получаемую путем их суммирования без учета переносимых знаков. Литеры со 2-й по 4-ю являются шестнадцатеричным порядковым номером, причем первая запись имеет номер 000. О выходе за пределы номеров записей следует сигнализировать как о нефатальной ошибке. Вслед за этой шапкой в записи располагаются триплеты: счетчик — адрес — данные. Поле счетчика содержит одну цифру и указывает, сколько байтов в памяти должна занять последующая информация. Поле адреса, состоящее из четырех цифр, дает шестнадцатеричный адрес начала информации в памяти УМ-1. И, наконец, поле данных содержит по две цифры на каждую подлежащую загрузке литеру, и любая такая пара цифр считывается как целое шестнадцатеричное число, определяя, таким образом, восемь битов информации для записи в память. В одной записи может быть несколько таких триплетов, однако ни один из них не должен выходить за границы записи. Первый же пробел, появившийся в поле адреса, ограничивает полезную информацию в записи, и оставшуюся часть записи можно, если угодно, использовать для комментариев. Последняя запись содержит на месте символов 1—3 литеры END, а символы с 4-го по 7-й определяют четырехзначный шестнадцатеричный адрес начала программы. Например, запись Е10241А2301020304207FF1ВЕС имеет контрольную сумму Е, порядковый номер 102 и помещает (достаточно бессмысленно) четыре литеры данных 01020304 с 1А23 адреса памяти, а две литеры 1ВЕС с адреса 07FF. Обратите внимание, что потребовалось восемь шестнадцатеричных цифр, чтобы задать четыре литеры во внутренней памяти. Тема. Напишите имитатор ЭВМ УМ-1. На вход имитатора должны поступать файл абсолютной загрузки и входной поток эмулируемой программы. Основное, что необходимо выдать, — это выходной поток программы. В виде приложения к имитатору напишите, по крайней мере, две программы для УМ-1, призванные проверить правильность эмуляции. Разумеется, эти программы надо будет вручную скомпоновать в формате файла абсолютной загрузки. Кроме записи результата в память имитатор должен уметь выполнять трассировку и дамп эмулируемой программы. Трассировка должна продемонстрировать прокручиваемую команду, вычисление исполнительного адреса, а также операнды и результаты как в их естественном, так и в шестнадцатеричном формате. Дамп должен включать в себя печать содержимого памяти (возможно, под управлением вспомогательных средств) в шестнадцатеричном виде, в мнемонических обозначениях команд, а также в форматах целом, вещественном и текстовом. Повторяющиеся группы данных должны печататься только один раз с указанием числа повторений. Управление трассировкой и дампом может выходить прямо на имитатор, возможно через пульт управления, или же может приводиться в действие путем обращений к супервизору в ходе выполнения программы. Указания исполнителю. Имитаторы компьютеров бывают, как правило, простыми, если они основаны на заурядном цикле: ячейка — декодирование — выполнение. Как только выделен код операции, так определен один из очевидных 128 путей ветвления. Эти 128 независимых программ моделирования команд могут использовать целый ряд общих подпрограмм, выполняющих частные задачи, а именно подпрограмм вычисления исполнительного адреса, установки САК, проверки особых случаев, итогового состояния памяти и тому подобные. Четкая разбивка на подпрограммы поможет продемонстрировать правильность работы. В то же время важна эффективность выполнения командного цикла — в противном случае расход времени может оказаться недопустимо большим. Необходимо найти разумный компромисс. Для остальных частей имитатора не нужна столь же высокая эффективность, поскольку им предстоит выполняться во много раз реже. Некоторые группы, выполнявшие в прошлом это задание, сообщали, что время, потраченное на конструирование простого ассемблера для получения тестовых вариантов, не прошло без пользы. Если в числе порученных вам работ окажется также и разработка загрузчика УМ, тщательно сконструированный ассемблер позволит применить его, ко всему прочему, и для проверки загрузчика. Инструментовка. Перед нами вновь программа, в которой ясность и эффективность противоречат друг другу. Рассмотрите возможность применения любого языка достаточно высокого уровня, в котором наиболее важные программы можно после отладки эффективно переписать на языке ассемблера. Поскольку обычная связь между подпрограммами может оказаться дорогостоящей, эта задача представляет удобный случай поэкспериментировать с языками, позволяющими прямо вставлять небольшие заплатки на языке ассемблера. В какой-то степени среди прочих языков этими качествами обладают Фортран, Алгол и XPL. Длительность исполнения. Одному исполнителю на шесть недель, двоим — на три недели. Если работа делается более чем одним исполнителем, каждый отчитывается за одну программу для УМ-1. Развитие темы. Самой очевидное дополнение к задаче состоит в получении временных характеристик (профиля) эмулируемой программы. Как часто работает каждая команда? Как часто используется каждая внутренняя подпрограмма? Какова картина обращений к памяти? К регистрам? И так далее, сколько пожелаете. Эту информацию бывает чрезвычайно трудно получить в реальном компьютере, но она очень помогает при анализе сложных ситуаций.Литература
Белл, Ньюэлл (Bell С. G., Newell A.). Computer Structures: Readings and Examples. McGraw-Hill, New York, NY, 1971. Белл и Ньюэлл обсуждают общие принципы машинной архитектуры и приводят около 30 примеров. Значительное место уделяется разработке обозначений для описания машины. Многие примеры почерпнуты из существенно отредактированных документов проектов подлинных машин. IBM Corporation. IBM System/360 Principles of Operation. IBM System Reference Library, GA22 6821-8, November 1970. Xerox Data Systems. Xerox Sigma 7 Computer Reference Manual. Order # 90 09503, 1971. УМ-1 весьма похожа как на Sigma 7, так и на IBM 360. Возможно, что сравнение этих машин с УМ-1 будет в чем-то полезно. С не меньшим успехом годятся другие выпуски указанных руководств. Кнут Д. Искусство программирования для ЭВМ. Т. 1. Основные алгоритмы. — М.: Мир, 1976, с. 159. Кнут описывает гипотетическую машину MIX. В п. 1.4.3.1 дается материал о MIАХ-имитаторе.26. Пища для УМа, или... СВЯЗЫВАЮЩИЙ ЗАГРУЗЧИК
В большинстве систем загрузчики находятся на положении пасынков. Их не любят пользователи, считая просто лишним препятствием на пути к вожделенному ответу. Они не нравятся и разработчикам компиляторов, поскольку являются составной частью системы (а вы считаете, что это не так?). Не по душе они и системным программистам, которые видят в них не более чем еще одно вспомогательное средство. Разве только коммерческие директора питают слабость к загрузчику за то, что он расходует так много машинного времени (и денег). Тем не менее, написав загрузчик для УМ-1, вы убедитесь, что его создание — очень стоящая задача. Загрузчик УМ представляет собой довольно стандартный настраивающий загрузчик, предназначенный для работы с языком Мини (гл. 27) и ЭВМ УМ-1 (гл. 25). Основные функции загрузчика УМ связаны с интерпретацией перемещаемого языка загрузки, обработкой достаточно сложных таблиц символов и регистрацией ошибок в ходе загрузки. Программы на языке Мини могут состоять из независимо скомпилированных программных сегментов, и загрузчик УМ обеспечивает проверку соответствия типов величин, общих для нескольких сегментов, и библиотечный поиск для сборки полных программ. Кроме того, перемещаемый язык загрузки позволяет настолько просто генерировать команды перехода вперед, что компиляторы могут быть не двух-, а однопроходными. Многие находящиеся в эксплуатации загрузчики предусматривают еще более сложную обработку, однако такая обработка требует весьма развитой системы ввода/вывода и поэтому неприемлема для этюда. Не исключено, что вы не сможете до конца прочувствовать загрузчик УМ (как сильные, так и слабые его стороны), пока не сконструируете компилятор или же специально не изучите загрузчики по литературе.Общая схема загрузчика
На вход загрузчика УМ поступают программный файл и библиотечный файл, причем каждый из них может состоять из некоторого числа модулей. Если же позволяет система, то программа или библиотека могут состоять более чем из одного файла. Загружены должны быть в первую очередь все модули программы, а модули из библиотечного файла загружаются, лишь если они соответствуют первичным ссылкам. К концу загрузки должен определиться ровно один начальный адрес программы, иначе фиксируется фатальная ошибка загрузки. В результате работы загрузчика получается файл абсолютной загрузки, который описывался в гл. 25. Загрузчик УМ содержит как счетчик абсолютного размещения (САР), так и счетчик относительного размещения (СОР). Перед началом загрузки САР устанавливается на адрес 4016. Всякий раз, когда начинается очередной модуль, САР настраивается на ближайшую свободную границу слова, а СОР обнуляется [52]. После того как загружен последний модуль, САР а последний раз продвигается к границе слова, следующего за верхней точкой модуля, и употребляется для определения значения абсолютного внешнего символа Максимальный Адрес. Перемещаемый язык загрузки состоит из набора команд загрузки, длиной восемь битов каждая. Команды записываются с помощью кодировок переменной длины, при этом отдельные параметры могут оказаться запрятанными в самих командах. Остальные параметры могут быть переменной длины, а употребляемые в командах выражения допускаются любой сложности. Все имена должны быть декларированы до их использования; описанные однажды, они везде ниже заменяются на их порядковые номера с целью уменьшения размера загрузочного модуля. Поскольку модули должны генерироваться однопроходным компилятором Мини, их размер в явном виде не указан. Поэтому загрузчик УМ должен следить за маркером конца, который позволит установить размер модуля. Внешние имена, встречающиеся в текущем модуле, должны быть описаны раньше всех других спецификаций загрузки. После того как все модули обработаны, из таблицы символов необходимо исключить все внутренние имена, глобальные символы сохранить и проделать соответствующие манипуляции с картой загрузки. Для целей диагностики можно ввести специальные символы, употребляемые только в карте загрузки. Загрузчик УМ в состоянии проверять типы внешних процедур и их аргументов.Структура физической записи
Записи в модуле загрузки представляют собой цепочки внешних литер переменной длины. В качестве литер используются либо шестнадцатеричные цифры, которые воспринимаются группами и образуют целые величины, либо литеры, почерпнутые из набора ASCII для УМ-1, которые представляют сами себя[53]. Первые шесть литер записи всегда связаны с ее физической структурой и неизменно располагаются в одном и том же формате. Позиция 1 содержит литеру 1, если данная запись — последняя в модуле, и 0 — во всех остальных случаях. В позициях 2—4 определяется трехзначный шестнадцатеричный порядковый номер записи в модуле — самая первая запись имеет номер 000. Нарушение порядка номеров записей является нефатальной ошибкой. Когда в модуле набирается 1000 записей, порядковый номер продолжается с 000. В позициях 5 и 6 указывается шестнадцатеричная длина записи. Эта длина включает в себя первые шесть литер и лежит, следовательно, между 07 и FF. Содержательная информация записи располагается во второй ее части, непосредственно примыкающей к постоянной шапке, и состоит из последовательности логических элементов загрузки. Логические элементы загрузки на границах физической записи могут произвольно прерываться. Логический элемент загрузки начинается с двух шестнадцатеричных цифр, идентифицирующих операцию загрузки, за которой следуют, если необходимо, параметры. Числовые параметры передаются всегда цепочкой шестнадцатеричных цифр такой длины, которая необходима для представления числа. Имена начинаются с поля счетчика из двух шестнадцатеричных цифр, за которым следуют фактические литеры имени — в количестве, указанном в счетчике. Таким образом, элемент 682C04Fool представляет собой операцию 68 — описание внешней ссылки с коротким номером символа 2С и именем Fool состоящим из четырех литер. Если параметром служит выражение, оно содержит собственные операции и может быть сколь угодно длинным. Заметим, что для задания одной внутренней литеры берутся две внешние шестнадцатеричные цифры.Описание элементов загрузки
Каждый отдельно взятый элемент загрузки характеризуется 8-разрядным кодом операции, двоичный формат которого показан во второй графе заголовка соответствующего пункта описания. Параметры, если таковые имеются, располагаются после кода операции. В названиях параметров содержатся общие указания об их употреблении. Не всегда можно сказать, насколько длинным окажется параметр. Параметры переменной длины будут всегда снабжаться указанием длины или явными ограничителями, Некоторые параметры окажутся запрятанными в коде операции.Элементы загрузки данных
Загрузка абсолютная 0000сссс Данные Поле счетчика сссс содержит уменьшенное на единицу количество внутренних литер данных, подлежащих загрузке. Остальная часть элемента состоит из числовых данных, которые требуется загрузить без смещения с текущим САР. К счетчикам САР и СОР прибавляется длина загруженного объекта. Загрузка слова со смещением 00010000 Данные Счетчики размещения сдвигаются к границе четного байта, если они уже на нее не установлены, загружаемый элемент данных, содержащий 8 цифр, помещается в очередные четыре байта, младшие два байта получают смещение относительно начала модуля, и к счетчикам размещения прибавляется длина загруженного объекта. Загрузка выражения 000110ww Выражение Поле параметра ww содержит уменьшенное на единицу количество байтов, загружаемых из аргумента-выражения. При вычислении выражения используется 32 двоичных разряда, но по назначению употребляются лишь младшие разряды результата. К счетчикам размещения прибавляется длина загруженного объекта. Загрузка относительно символа 0001010l Символ Данные Счетчики размещения настраиваются на ближайшую границу четного байта, если они уже на нее не установлены. Загружается восемь цифр данных. К двум младшим байтам данных в памяти прибавляется значение символа, номер которого указан в первом аргументе. Номер символа содержит две цифры, если I=0, и четыре цифры, если l=1. Смещение должно задаваться перемещаемым символом, но само значение его может быть еще не определено.Выражения при загрузке
Выражения, которые должны во время загрузки получить численные значения, вычисляются с использованием 32-разрядного сумматора, снабженного признаком типа (или абсолютного, или относительного). Цепочка элементов загрузки, определяющих загружаемое выражение, может быть произвольной длины и во всех случаях оканчивается признаком конца выражения. В выражении могут употребляться лишь те символы, значения которых уже определены, и только в допустимых сочетаниях типов в соответствии с табл. 26.1. Последняя приведенная в таблице комбинация возможна лишь при условии, что оба элемента располагаются в текущем модуле. В исходном состоянии сумматор, как правило, равен абсолютному нулю. Арифметическая операция 0010lsot Операнд Если бит о равен нулю, производится операция сложения; в противном случае — операция вычитания. Таблица 26.1. Допустимые комбинации типов операндов Если бит s равен нулю, операнд представляет собой константу, и тогда бит t указывает на то, является ли константа абсолютной (t = 0) или относительной (t = 1). В противном случае (s = 1) операнд представляет собой номер символа. Бит l указывает на то, содержит ли операнд две (l = 0) или четыре (l = 1) цифры. Операция выполняется, и значение соответствующего типа помещается на сумматор.
Установка СОР на сумматор 00110000 Нет
Текущее содержимое сумматора игнорируется, и в него помещается величина относительного типа, равная текущему значению СОР.
Конец выражения 00110001 Нет
Текущее выражение окончено, при этом на сумматоре находится его значение.
Если бит s равен нулю, операнд представляет собой константу, и тогда бит t указывает на то, является ли константа абсолютной (t = 0) или относительной (t = 1). В противном случае (s = 1) операнд представляет собой номер символа. Бит l указывает на то, содержит ли операнд две (l = 0) или четыре (l = 1) цифры. Операция выполняется, и значение соответствующего типа помещается на сумматор.
Установка СОР на сумматор 00110000 Нет
Текущее содержимое сумматора игнорируется, и в него помещается величина относительного типа, равная текущему значению СОР.
Конец выражения 00110001 Нет
Текущее выражение окончено, при этом на сумматоре находится его значение.
Определение символов
Вообще говоря, символы должны декларироваться до их употребления, и именно описание связывает внутренний номер символа с его именем. Внутри любого данного модуля номера символов могут встречаться только один раз. Определения могут находиться в любом месте модуля. Имена символов допускаются любой длины от 0 до 255 литер. Имя любого символа состоит из поля длины (две цифры) и следующих за ним литер самого имени. В конце обработки модуля все имена, кроме внешних и имен в карте загрузки, надлежит из таблицы символов загрузчика исключить. Определение внешнего символа 010lt000 Номер Выражение Внешнему символу, номер которого задается первым аргументом, присваивается значение второго аргумента. Номер символа состоит из двух цифр при l = 0 или четырех цифр в противном случае. Если бит t равен 0, то символ абсолютный, в противном случае — относительный. Типы определяющего выражения и уже занесенного в таблицу символа (тип символа задается параметром t) должны совпадать. Во время определения любые ссылки на символ должны быть заполнены. Определение символа в карте 0100t001 Имя Выражение Выражение, представленное вторым аргументом, вычисляется и приписывается символу, имя которого указано в первом аргументе, для последующего помещения в карту загрузки. Если t = 0, то тип символа абсолютный, в противном случае — относительный. Определение ссылки вперед 010lt01h Номер Выражение Ссылке вперед, номер которой указан в первом аргументе, ставится в соответствие выражение, приведенное во втором аргументе. При l = 0 номер ссылки состоит из двух цифр, в противном случае — из четырех. Символ является абсолютным, если t = 0, и относительным в противном случае. Если h = 0, то ссылка вперед сохраняется в таблице символов, в противном случае после данного определения ссылка исключается из таблицы. Описание внешней ссылки 011lt00p Номер Имя Символ с именем, указанным в аргументе, и номером, приведенным в первом аргументе, декларируется как ссылка на внешний символ другого модуля. Если l = 0, номер символа состоит из двух цифр, в противном случае — из четырех. При t = 0 тип символа абсолютный, в противном случае — относительный. Равенство р = 0 означает, что ссылка первична и ее надлежит отыскать и заполнить; в противном случае ссылка вторична, и ее необходимо заполнять, лишь если символ определяется по другой причине. Описание ссылки вперед 011lt010 Номер Декларируется ссылка вперед на символ, номер которого указан в аргументе. Если l = 0, номер содержит две цифры, в противном случае — четыре. При t=0 символ абсолютный, в противном случае — относительный. Описание внешнего имени 011lt011 Номер Имя Символ с номером и именем, указанными соответственно в первом и втором аргументах, декларируется в качестве внешнего символа, который будет определен в данном модуле. Описания внешних имен должны располагаться в самом начале модуля. Если l = 0, то номер символа содержит две цифры, в противном случае — четыре. При t = 0 тип символа абсолютный, в противном случае — относительный. Определение типов процедуры 011l0100 Номер N Тип1...ТипN С символом, номер которого указан в первом аргументе, соотносится цепочка типов, длина которой задается двумя литерами второго аргумента. Если I = 0, то номер символа состоит из двух цифр, в противном случае — из четырех. Каждый тип представляется одной литерой. Чтобы определить символ, он должен быть уже описан в этом разделе как внешний. Данная команда, как и последующая, может употребляться компилятором Мини для проверки правильности количества и типов аргументов внешних процедур. В компиляторе необходимо установить способ представления возможных типов аргументов в виде целых чисел, которого надо придерживаться при всех трансляциях. Проверка типов процедуры 011l0101 Номер N Тип1...ТипN Аргументы этой команды те же, что и в команде определения типов процедуры, с тем отличием, что символ должен быть внешней ссылкой текущего модуля. Перечисленные в команде типы сравниваются с типами указанного символа, и, если они в чем-то не совпадают, объявляется фатальная ошибка загрузки.Прочие команды
Установка начального адреса 10010000 Выражение В качестве начального адреса загрузки устанавливается выражение, указанное в аргументе. Выражение должно быть относительным. Данная команда должна встретиться в загрузке ровно один раз. Нарушение этого условия приводит к фатальной ошибке загрузки. Начальный адрес должен присутствовать в карте загрузки в виде некоторого искусственного имени. Установка на четный адрес 10100000 Оба счетчика размещения продвигаются до ближайшего четного адреса, если они уже на такой адрес не установлены. Установка на адрес слова 10110000 Оба счетчика размещения продвигаются до адреса очередного слова, если они уже на такой адрес не установлены. Установка счетчиков размещения 11000000 Выражение Оба счетчика размещения принимают значение выражения, которое должно быть относительным и неотрицательным. Не забудьте, что САР—начало=СОР. Пустая команда 11010000 Невыполняемая команда. Может встречаться в выражениях. Конец модуля 11111111 Окончание текущего модуля. Если данная команда не встретится в физической записи, содержащей 1 в первом символе шапки, выдается сообщение о фатальной ошибке загрузки.Пример программы
Для того чтобы разъяснить некоторые из введенных понятий, приведем образец программы на языке ассемблера УМ-1 и ее модуль загрузки, сгенерированный гипотетическим ассемблером, Что представляет собой сама программа, значения не имеет, важно лишь то, что она наглядно демонстрирует многие характерные черты загрузки. Вероятно, если бы присваивание именам номеров производилось реальным ассемблером, то оно было бы выполнено более логично. Загружаемая программа приведена без разбивки по физическим записям и элементов управления ими, но с пояснениями, связывающими ее с языком ассемблера.
 Тема. Сконструируйте загрузчик УМ. На его вход должна поступать последовательность перемещаемых объектных файлов, а на выходе — как файл абсолютной загрузки, так и карта загрузки. Непременно сигнализируйте об ошибках загрузки. Необходимо, чтобы карта загрузки была отсортирована как по именам, так и по адресам. Содержащиеся в карте символы должны включать в себя внешние символы и ссылки, а также другие определенные символы. Кроме того, укажите размер каждого модуля.
Указания исполнителю. В большинстве загрузчиков время расходуется на два вида работ: организацию ввода/вывода и обработку таблицы символов. Очевидно, что коль скоро считывается и записывается большой объем информации, существует нижний предел времени, затрачиваемого на ввод/вывод. Тем не менее, в данной работе упор должен делаться, во всяком случае, не на технику совершенствования ввода/вывода, да и язык высокого уровня, видимо, не очень-то способствует этому. А вот работу с таблицей символов, если ее тщательно продумать, улучшить можно. Поэтому надо так спланировать загрузчик, чтобы можно было легко подключать и отключать разные программы обработки таблиц символов. Напишите простую программу управления таблицами, отладьте загрузчик полностью, а потом попытайтесь совершенствовать операции с символами.
Накопленный опыт показывает, что работу по подготовке тестирующих программ надо начинать пораньше. Перевод языка ассемблера в модуль загрузки оказывается труднее, чем может показаться. Не исключено, что вам захочется применить ассемблер для УМ-1, предлагавшийся в гл. 25 в качестве средства отладки. Постарайтесь воспользоваться каждой командой, по крайней мере, один раз.
Инструментовка. Используйте любой процедурный язык высокого уровня. Однако возможности выбора языка не безграничны, хотя в них и имеются средства работы с битами. Помните, что необходимо читать записи переменной длины.
Длительность исполнения. Одному исполнителю на шесть недель; двоим или троим — на 3 недели. Каждый участник должен сделать одну тестовую программу в перемещаемом объектном коде.
Тема. Сконструируйте загрузчик УМ. На его вход должна поступать последовательность перемещаемых объектных файлов, а на выходе — как файл абсолютной загрузки, так и карта загрузки. Непременно сигнализируйте об ошибках загрузки. Необходимо, чтобы карта загрузки была отсортирована как по именам, так и по адресам. Содержащиеся в карте символы должны включать в себя внешние символы и ссылки, а также другие определенные символы. Кроме того, укажите размер каждого модуля.
Указания исполнителю. В большинстве загрузчиков время расходуется на два вида работ: организацию ввода/вывода и обработку таблицы символов. Очевидно, что коль скоро считывается и записывается большой объем информации, существует нижний предел времени, затрачиваемого на ввод/вывод. Тем не менее, в данной работе упор должен делаться, во всяком случае, не на технику совершенствования ввода/вывода, да и язык высокого уровня, видимо, не очень-то способствует этому. А вот работу с таблицей символов, если ее тщательно продумать, улучшить можно. Поэтому надо так спланировать загрузчик, чтобы можно было легко подключать и отключать разные программы обработки таблиц символов. Напишите простую программу управления таблицами, отладьте загрузчик полностью, а потом попытайтесь совершенствовать операции с символами.
Накопленный опыт показывает, что работу по подготовке тестирующих программ надо начинать пораньше. Перевод языка ассемблера в модуль загрузки оказывается труднее, чем может показаться. Не исключено, что вам захочется применить ассемблер для УМ-1, предлагавшийся в гл. 25 в качестве средства отладки. Постарайтесь воспользоваться каждой командой, по крайней мере, один раз.
Инструментовка. Используйте любой процедурный язык высокого уровня. Однако возможности выбора языка не безграничны, хотя в них и имеются средства работы с битами. Помните, что необходимо читать записи переменной длины.
Длительность исполнения. Одному исполнителю на шесть недель; двоим или троим — на 3 недели. Каждый участник должен сделать одну тестовую программу в перемещаемом объектном коде.
Литература
Баррон (Barron D. W.). Assemblers and Loaders. Macdonald, London, 196& [Имеется перевод: Баррон Д. Ассемблеры и загрузчики. — М.: Мир, 1974.] Прессер, Уайт (Presser L., White J. R.). Linkers and Loaders, Comput Surveys, 4, 3, pp. 149—167, 1972. Книга Баррона представляет собой элементарное введение в ассемблеры и загрузчики. Описанный в ней загрузчик близок к нашему и вместе с тем рассмотрен более подробно. Прессер и Уайт описывают систему, применяемую на IBM 360. Поскольку в системе 360 исключено перемещение, чего нельзя сказать о других системах, основное внимание уделяется связыванию программ27. Мал золотник, или... КОМПИЛЯТОР ДЛЯ АЛГЕБРАИЧЕСКОГО ЯЗЫКА
Компилятор — это всегда большая программа. Написать его, практически на пустом месте, даже под опекой преподавателей вовсе не просто. И хотя при создании Мини ставилась цель свести все муки к минимуму, во всяком случае, в той мере, в какой это позволяло его просветительское назначение, предлагаемая задача все же оказалась самой трудной в книге. Если вы (и ваши верные друзья) не обладаете достаточной энергией и временем, то не стоит за нее и браться.Язык Мини
Мини — универсальный, процедурный, алгебраический язык программирования. Он уходит своими корнями в Алгол, Алгол 68 и Паскаль. Подобно этим языкам, Мини предназначен для компиляции, загрузки и выполнения на обычных ЭВМ (хорошим примером такой машины служит УМ-1, см. гл. 25). Синтаксис задается контекстно-свободной грамматикой, пригодной для разбора методами LRA). Семантика аналогична алгольной и паскалевой, и нам кажется достаточным ее неформальное описание. Квалификация читателя позволит ему домыслить все недосказанное[54]. Ниже приведены логически связанные части грамматики и их семантика.Единицы компиляции
<единица компиляции>::=<программный сегмент> | <единица компиляции> <программный сегмент> <программный сегмент>::= <главная программа> | <внешняя процедура> <Единица компиляции> — это цепочка замкнутых <программных сегментов>[55]. Каждый <программный сегмент> есть либо <главная программа>, либо <внешняя процедура>. Все сегменты <единицы компиляции> свяжет друг с другом загрузчик, однако не обязательно, чтобы все сегменты, нужные для полной загрузки, компилировались вместе. При загрузке должна присутствовать ровно одна <главная программа>.Программы
<главная программа> ::= <заголовокпрограммы><тело программы> <конец программы> <заголовок программы>::= PROGRAM <идентификатор> <тело программы>::= <тело сегмента> <конец программы>::= END PROGRAM <идентификатор>; Каждая <главная программа> именована, и закрывающее имя должно совпадать с открывающим. <Тело программы>, подобно большинству других сгруппированных инструкций, есть <тело сегмента> и может содержать все, что обычно свойственно программам. Заметим также, что резервированные слова, идентификаторы и константы не должны разрываться на границах записей. Их следует отделять друг от друга пробелами, знаками операций, комментариями или границами записей.Внешние процедуры
<внешняя процедура> ::= <внешняя подпрограмма> | <внешняя функция> <внешняя подпрограмма> ::= <заголовок внешней подпрограммы>: <тело внешней подпрограммы> <конец внешней подпрограммы> <внешняя функция> ::= <заголовок внешней функции>: <тело внешней функции> <конец внешней функции> <заголовок внешней подпрограммы> ::= EXTERNAL PROCEDURE <имя внешней процедуры> <заголовок внешней функции>::= EXTERNAL FUNCTION <имя внешней процедуры> <внешний тип> <имя внешней процедуры> ::= <идентификатор> | <идентификатор> <список внешних параметров> <список внешних параметров>::= <заголовок внешних параметров>) <заголовок внешних параметров>::= (<внешний параметр> | <заголовок внешних параметров>, <внешний параметр> <внешний параметр>::= <идентификатор> <внешний тип> | <идентификатор> <внешний тип> NAME <внешний тип>::= <базовый тип> <тело внешней подпрограммы>::= <тело сегмента> <тело внешней функции>::= <тело сегмента> <конец внешней подпрограммы>::= END EXTERNAL PROCEDURE <идентификатор>; <конец внешней функции>::= END EXTERNAL FUNCTION <идентификатор>; <Внешние процедуры> позволяют компилировать модули раздельно и собирать их вместе во время загрузки. При загрузке допускается лишь одна <внешняя процедура> с данным именем. <Внешние параметры> и возвращаемые <внешними функциями> значения должны иметь <базовый тип>. <Внешние параметры> передаются по значению, если они не помечены резервированным словом NAME; при наличии этого слова параметры передаются по имени. Перед <концом внешней подпрограммы> неявно располагается <инструкция возврата>, однако <внешние функции> должны завершать работу явной <инструкцией возврата> с возвращаемым значением; попытка выхода из <внешней функции> через <конец внешней функции> является семантической ошибкой, которую иногда можно обнаружить при компиляции. Единственной связью между переменными <внешней процедуры> и переменными вызывающей процедуры служит механизм передачи параметров. Однако во время сборки сегментов (например, с помощью загрузчика, подобного описанному в гл. 26) будет проверено совпадение типов формальных и фактических параметров, функций и возвращаемых значений. Из описания <внешних процедур> усматривается несколько важных различий между Мини и современными языками. В коммерческом языке целесообразно обеспечивать средства для разделения деклараций всех видов между <программными сегментами>. На наш взгляд, усложнения, вносимые в язык такой возможностью, слишком велики по сравнению с педагогическим эффектом от их реализации: это же справедливо по отношению к расширению диапазона возможных типов параметров <внешних процедур>. С другой стороны, коммерческие языки в своем большинстве не допускают передачу параметров по имени (из соображений эффективности), в то время как студента, овладевшего механизмом передачи по имени, не смутить уже, кажется, ничем. Мини многословнее аналогичных языков, поскольку современные исследования[56] показали важность умело распределенной избыточности для исправления синтаксических ошибок. Кроме того, программист, пишущий на Мини, должен явно различать декларации подпрограмм и функций. Хотя компилятор и может самостоятельно выявить различие, язык заставляет программиста явно демонстрировать свои намерения. Наконец, Мини позволяет полностью проверить совпадение типов во время компиляции и загрузки, следуя неписаному закону: во время выполнения нужно делать как можно меньше.Сегменты
<тело сегмента>::= <раздел определения типов> <раздел декларации переменных> <раздел определения процедур> <раздел выполняемых инструкций> <раздел определения типов>::= | <раздел определения типов> <определение типа> <раздел декларации переменных>::= I <раздел декларации переменных> <декларация переменных> <раздел определения процедур> ::= | <раздел определения процедур> <определение процедуры> <раздел выполняемых инструкций>::=<выполняемая инструкция> | <раздел выполняемых инструкций> <выполняемая инструкция> <Тело сегмента> состоит не менее чем из одной <выполняемой инструкции>, которой, возможно, предшествуют <определения типов>, <декларации переменных> и <определения процедур>. Область действия любого имени — вся оставшаяся часть тела данного сегмента; это имя можно использовать в следующих определениях и декларациях. Одно и то же имя нельзя декларировать или определять дважды в <теле сегмента>. Как и в Алголе, имя можно переопределить или передекларировать во внутреннем <теле сегмента>.Типы
<определение типа>::= TYPE <идентификатор> IS <тип> <тип>::== <базовый тип> | <массивный тип> | <структурный тип> | <идентификатор типа> <базовый тип> ::= INTEGER | REAL | BOOLEAN | STRING <массивный тип> ::= ARRAY <границы> OF <тип> <границы>::= [<граничное выражение>] [<граничное выражение>: <граничное выражение>] <граничное выражение>::= <выражение> <структурный тип>::= STRUCTURE <список полей> END STRUCTURE <список полей>::=<поле> | <список полей>, <поле> <поле>::== FIELD <идентификатор> IS <тип> <идентификатор типа>::= <идентификатор> <Определение типа> вводит для <типа> сокращение — <идентификатор>. В дальнейшем это сокращение можно использовать везде, где мог бы стоять <тип>. В набор типов входят встроенные <базовые типы>, однородные <массивные типы>, разнородные <структурные типы> и сокращения — <идентификаторы типов>. <Базовые типы> INTEGER и REAL могут отображаться на соответствующие аппаратные типы и подчиняться обычным правилам. <Базовый тип> BOOLEAN состоит всего из двух констант TRUE и FALSE. Элементами типа STRING являются цепочки литер произвольной длины, («степень произвола» может зависеть от реализации), но не менее нескольких тысяч. Массивы имеют одно измерение, однако их компоненты могут иметь произвольный тип, так что допускается декларация массива массивов массивов.... Если нижняя граница массива не задана явно, она полагается равной единице. <Граничные выражения> могут быть сколь угодно сложными, лишь бы их значение сводилось к типу INTEGER. В эти выражения могут входить только переменные, декларированные в объемлющих <телах сегментов> (но не в текущем <теле сегмента>) или в списке параметров объемлющей процедуры. Верхняя граница должна быть не меньше нижней. Там, где возможно, компилятор должен проверять это условие, однако в общем случае требуется проверка во время выполнения. Разные вхождения одинаковых <массивных типов> не рассматриваются компилятором как один и тот же <тип> при проверках совпадения типов. Чтобы допустить неоднократное использование, <массивный тип> нужно обозначить <идентификатором типа>. <Структурный тип> аналогичен записям в Паскале. <Идентификаторы> полей используются для именования элементов с <типами> полей. Поскольку определение рекурсивно, структуры могут иметь подструктуры. Конкретный <идентификатор> может именовать только одно <поле> <структурного типа>, однако допускается его использование и как имени переменной, и как имени поля другого (даже вложенного) <структурного типа>.Декларации
<декларация переменных>::= DECLARE <декларируемые имена> <тип>; <декларируемые имена> ::== <идентификатор> | <список декларируемых имен>> <список декларируемых имен>::= <<идентификатор> | <список декларируемых имен>, <идентификатор> <Декларация переменных> наделяет <типом> <идентификаторы>, употребленные среди <декларируемых имен>. <Идентификаторы> не получают начальных значений. Имя <кроме имени поля> в <теле сегмента> может определяться или декларироваться не более одного раза.Внутренние процедуры
<определение процедуры> ::= <определение подпрограммы> |<определение функции> |<определение внешней подпрограммы> | <определение внешней функции> <определение подпрограммы>::= <заголовок подпрограммы>: <тело подпрограммы> <конец подпрограммы> <определение функции> ::= <заголовок функции>: <тело функции> <конец функции> <определение внешней подпрограммы>::= <заголовок внешней подпрограммы> <определение внешней функции>::=<заголовок внешней функции>; <заголовок подпрограммы>::= PROCEDURE <имя процедуры> <заголовок функции>::= FUNCTION <имя процедуры> <тип> <тело подпрограммы>::= <тело сегмента> <тело функции>::= <тело сегмента> <конец подпрограммы>::= END PROCEDURE <идентификатор>; <конец функции> ::= END FUNCTION <идентификатор>; <имя процедуры>::= <идентификатор> |<идентификатор> <список внутренних параметров> <список внутренних параметров> ::= <заголовок внутренних параметров>) <заголовок внутренних параметров> ::= (<внутренний параметр |<заголовок внутренних параметров>, <внутренний параметр> <внутренний параметр>::= <идентификатор> <тип> | <идентификатор> <тип> NAME Непосредственно в <теле сегмента> можно определить лишь одну процедуру с данным именем. Определение <внешней подпрограммы> или <внешней функции> дается только заголовком, поскольку тело <внешней процедуры> доставит та же или другая <единица компиляции>. В локальном и окончательном определении процедуры должны совпадать имя процедуры, порядок, тип и способ передачи формальных параметров; это соответствие проверит загрузчик. Напомним, что параметры <внешней процедуры> должны иметь <базовый тип>. Определение локальных процедур дается аналогично. <Внутренние параметры>, так же как и возвращаемые функциями значения, могут иметь любой <тип>. Перед <концом подпрограммы> располагается неявная <инструкция возврата>. Выход из функции должен осуществляться посредством явной <инструкции возврата>, снабженной значением. Параметры с пометкой NAME передаются по имени, остальные — по значению. Сами по себе процедуры напоминают алгольные. Рекурсия допускается в полном объеме. <Имя процедуры> нельзя использовать до его декларации.Выполняемые инструкции
<выполняемая инструкция>::=<инструкция присваивания> |<инструкция вызова> |<инструкция возврата> |<инструкция завершения> |<условная инструкция> |<составная инструкция> |<инструкция цикла> |<инструкция выбора> |<инструкция возобновления> |<инструкция выхода> |<инструкция ввода> |<инструкция вывода> |<пустая инструкция> Поскольку используются принятые в Алголе 68 условные инструкции и инструкции цикла, нет нужды разбивать их на несколько отдельных синтаксических классов. Все инструкции должны завершаться точкой с запятой.Присваивания
<инструкция присваивания>::= SET <список целей> <выражение>; <список целей>::=<цель> |<список целей> <цель> <цель> ::=<переменная> <заменить на> <заменить на>::—:= В <инструкции присваивания> <тип> всех <целей> и <тип> присваиваемого <выражения> должен быть одним и тем же. <Цели> обрабатываются слева направо, чтобы определить адреса в памяти, и только затем вычисляется выражение, чтобы найти запоминаемое значение. Структуры и массивы можно присваивать в случае совпадения <типов>. Использование ключевого слова SET служит примером многословности Мини. Данная избыточность помогает исправлению, когда неправильно записано другое ключе вое слово (распространенная ошибка).Вызовы процедур
<инструкция вызова>::= CALL <обращение к процедуре>; <обращение к процедуре> ::= <идентификатор процедура> |<идентификатор процедуры> <список фактических параметров> <идентификатор процедуры>::= <идентификатор> <список фактических параметров> ::= <заголовок фактических параметров>) <заголовок фактических параметров>::=(<<выражение> |<заголовок фактических параметров>, <выражение> Можно вызывать только процедуры, получившие определения а областью действия, содержащей <инструкцию вызова>. Количество, порядок и типы фактических и формальных параметров должны совпадать. После того как в вызываемой процедуре выполнится <инструкция возврата>, управление будет передано на следующую за вызовом инструкцию. Ключевое слово CALL используется по тем же соображениям, что и SET в <инструкции присваивания>.Возвраты
<инструкция возврата> ::= RETURN; | RETURN <выражение>; <Инструкция возврата> может употребляться только в процедуре. Она возвращает управление в вызывающую инструкцию, В конце подпрограммы имеется неявная <инструкция возврата>. При возврате из подпрограммы значение указывать нельзя. При возврате из функции значение указывать обязательно. Оно должно иметь тот же тип, что и функция.Инструкции завершения
<инструкция завершения>::= EXIT; Данная инструкция вызывает нормальное завершение всей программы и возврат в супервизор. Она должна быть последней выполненной (не обязательно последней написанной) инструкцией <программы>.Условные инструкции
<условная инструкция> ::= <простая условная инструкция> |<метка> <простая условная инструкция> <простая условная инструкция>::= <спецификация условия> <истинная ветвь> FI; |<спецификация условия> <истинная ветвь> <ложная ветвь> FI; <спецификация условия> ::= IF <выражение> <истинная ветвь>::=THEN <тело условной инструкции> <ложная ветвь> ::= <иначе> <тело условной инструкции> <иначе>::= ELSE <тело условной инструкции> ::= <тело сегмента> В <условной инструкции> выбирается и выполняется <истинная ветвь> или <ложная ветвь> в зависимости от истинности <выражения> типа BOOLEAN. Каждая ветвь представляет собой <тело сегмента> и может содержать все необходимые определения, декларации и инструкции без дополнительных скобок. После выполнения выбранной ветви управление передается на инструкцию, следующую за условной.Составные инструкции
<составная инструкция> ::=<простая составная инструкция> |<метка> <простая составная инструкция> <простая составная инструкция>::<заголовок составной инструкции> <тело составной инструкции> <конец составной инструкции> <заголовок составной инструкции>::= BEGIN <тело составной инструкции> ::= <тело сегмента> <конец составной инструкции> ::= END; |END <идентификатор>; Другие возможности, заложенные в синтаксисе Мини, делают <составные инструкции> не особенно необходимыми. Однако <составные инструкции> полезны в сочетании с инструкциями REPEAT и REPENT. В начало составной инструкции можно поместить декларации и определения. Если после END записан <идентификатор>, он должен быть <меткой>, причем <метка> и <идентификатор> обязаны совпадать. Рисунок 27.1. Определение на метаМини, позволяющее понять действие <инструкции цикла>. Это «определение» влечет за собой обязательное перевычисление <цели цикла>.
Рисунок 27.1. Определение на метаМини, позволяющее понять действие <инструкции цикла>. Это «определение» влечет за собой обязательное перевычисление <цели цикла>.
Инструкции цикла
<инструкция цикла>::= <простая инструкция цикла> |<метка> <простая инструкция цикла> <простая инструкция цикла>::= <заголовок цикла> <тело цикла> <конец цикла> <заголовок цикла>::= <для> <цель цикла> <управление> DO <тело цикла> ::= <тело сегмента> <конец цикла>::= END FOR; |END FOR <идентификатор>; <для>::= FOR <цель цикла>::= <переменная> <заменить на> <управление>::= <шаговое управление> |<шаговое управление> <условное управление> <шаговое управление> ::= <начальное значение> <шаг> |<начальное значение> <предел> |<начальное значение> <шаг> <предел> <начальное значение>::= <выражение> <шаг>::= BY <выражение> <предел>::= ТО <выражение> <условное управление>::= WHILE <выражение> Проще всего объяснить поведение <инструкции цикла>, написав на «метаМини» небольшой фрагмент, заменяющий эту инструкцию. Чтобы найти результат работы <инструкции цикла>, нужно применить к ней «определение», данное на рис. 27.1. Подчеркнем, что, согласно этому определению, <цель цикла>, <предел> и <шаг> перевычисляются при каждом повторении. Предикат «существует» позволяет метаМини узнать, присутствуют ли соответствующие необязательные части в конкретной <инструкции цикла>. Если употреблен закрывающий <идентификатор>, он должен совпадать с <обязательно присутствующей> <меткой>. В данном определении <инструкции цикла> педагог вновь победил практика. Динамическое переопределение управляющих значений унаследовано из Алгола; большинство других языков отказалось от этого по соображениям эффективности. Однако, если вы сможете реализовать динамическое определение, полученных знаний с избытком хватит на построение более простых статических циклов. Шаговый и условный циклы соединены в одной инструкции, чтобы сделать Мини поменьше; в реальном языке их можно разделить. Соблюдайте осторожность при повторной обработке <цели цикла>; если цель — это формальный параметр или элемент массива, при каждом повторении за целью могут скрываться различные переменные.Выбор
<инструкция выбора>::=<простая инструкция выбора> |<метка> <простая инструкция выбора> <простая инструкция выбора> ::= <заголовок инструкции выбора> <тело инструкции выбора> <конец инструкции выбора> <заголовок инструкции выбора> ::= SELECT <выражение> OF <тело инструкции выбора>::=<список случаев> |<список случаев> <прочие случаи> <конец инструкции выбора> ::= END SELECT; |END SELECT <идентификатор>; <список случаев> ::= <случай> |<список случаев> <случай> <случай> ::= <заголовок случая> <тело случая> <заголовок случая> ::= CASE <селектор>: <селектор>::= <заголовок селектора>) <заголовок селектора>::= <<выражение> |<заголовок селектора>, <выражение> <прочие случаи>::=<заголовок прочих случаев> <тело случая> <заголовок прочих случаев> ::= OTHERWISE: <тело случая> ::= <тело сегмента> <Инструкция выбора> работает следующим образом.Вычисляется <выражение> в <заголовке инструкции выбора>. Обрабатываются все <случаи>, от первого до последнего, в <списке случаев>. Для каждого <случая>, слева направо, одно за другим вычисляются <выражения> в <селекторе>. Как только <выражение> вычислено, его значение сравнивается со значением первоначального <выражения> из <заголовка инструкции выбора>. Если они равны, выполняется соответствующее <тело случая>; на этом <инструкция выбора> завершает свою работу, и управление передается на следующую < инструкцию>.
Если ни один из случаев не выбран и если имеются <прочие случаи>, выполняется <тело случая> и <инструкция выбора> завершает работу. Иначе <инструкция выбора> ни на что не влияет, если не считать побочных эффектов от вычисления выражений.
Типы всех выражений, используемых для выбора <случая>, должны быть одинаковы. Если в конце <инструкции выбора> употреблен <идентификатор>, он должен совпадать с <обязательно присутствующей> <меткой> <инструкции выбора>.
Возобновление и выход
<инструкция возобновления>::=REPEAT <идентификатор>; <инструкция выхода>::=REPENT <идентификатор>; <Инструкция возобновления> вызывает возврат управления на начало объемлющего тела инструкции, помеченной <идентификатором>. Выполнение всех промежуточных объемлющих тел сегментов и инструкций, частями которых эти тела являются, завершается, как если бы произошел нормальный выход из них. Вся связанная с ними память разрушается. <Метка>, на которую выполняется переход, должна принадлежать той же процедуре, что и <инструкция возобновления>. Если не существует объемлющей инструкции с указанной меткой, <инструкция возобновления> рассматривается как семантически ошибочная. Семантика <инструкции выхода> аналогична, с той лишь разницей, что управление передается не на начало помеченной инструкции, а в точку, непосредственно следующую за помеченной объемлющей инструкцией. Заметим, что <инструкция возобновления> вызывает повторное выполнение инструкции, на начало которой передается управление.Ввод и вывод
<инструкция ввода>::= INPUT <список ввода>; <список ввода> ::= <переменная> |<список ввода>, переменная> <инструкция вывода>::== OUTPUT <список вывода>; <список вывода>::= <выражение> |<список вывода> <выражение> <Инструкция ввода> вызывает передачу элементов данных из входного потока в <переменные> <списка ввода>. Вводимые элементы должны иметь базовый тип, совпадающий с типом соответствующей переменной. Вводимый элемент представляется так же, как константа этого типа. Элементы входного потока необходимо разделять литерами пробела или конца записи. Аналогично <инструкция вывода> вызывает передачу <выражений> из <списка вывода> в выходной поток. <Выражения> должны иметь базовый тип. Точный формат выходного потока определяется при реализации; требуется лишь, чтобы выводимая информация годилась для последующего ввода. Каждая <инструкция вывода> в конце своей работы выдает литеру конца записи.Пустые инструкции и метки
<пустая инструкция>::=; <метка>::=<идентификатор>: <Пустая инструкция> не вызывает никаких действий. <Метка> — это <идентификатор>, который декларируется своим использованием и в данном <теле сегмента> не может декларироваться или определяться иначе, как имя поля.Выражения
<выражение>::= <выражение один> |<выражение> | <выражение один> |<выражение> XOR <выражение один> <выражение один>::= <выражение два> |<выражение один> & <выражение два> <выражение два> ::= <выражение три> | NOT <выражение три> <выражение три> ::= <выражение четыре> |<выражение три> <отношение> <выражение четыре> <выражение четыре>::= <выражение пять> |<выражение четыре> || <выражение пять> <выражение пять>::= <выражение шесть> |<выражение пять> <аддитивный оператор> <выражение шесть> |<аддитивный оператор> <выражение шесть> <выражение шесть>::= <выражение семь> |<выражение шесть> <мультипликативный оператор> <выражение семь> <выражение семь>::= FLOOR (<выражение>) |LENGTH (<выражение>) |SUBSTR (<выражение>, <выражение>, <выражение>) |CHARACTER (<выражение>) |NUMBER (<выражение>) |FLOAT (<выражение>) |FIX (<выражение>) |<выражение восемь> <выражение восемь>::= <переменная>| <константа> |<вызов функции> |(<выражение>) Выражения трактуются совершенно стандартным образом. Операнды операторов ||, XOR (исключающее или), & и NOT должны иметь тип BOOLEAN. Два произвольных элемента одного типа можно сравнить посредством <отношения> равенства и неравенства. Цепочки литер можно сравнить посредством любого <отношения>. Две цепочки равны тогда и только тогда, когда они в точности одинаковы. Цепочка А меньше цепочки В, если начало А равно началу В и в А больше нет литер или очередная литера А предшествует очередной литере В в алфавитной упорядоченности. Два любых целых или вещественных числа можно сравнивать посредством любого <отношения>; если целое сравнивается с вещественным, оно неявно преобразуется в вещественное. Результат любого сравнения имеет тип BOOLEAN. Операндами <аддитивных операторов> и <мультипликативных операторов> могут быть только целые и вещественные значения. Если целые операнды сочетаются с вещественными, перед выполнением операции целые преобразуются в вещественные. В операции MOD нельзя использовать вещественные числа; при выполнении операций MOD и деления целых чисел частное выбирается так, чтобы остаток был неотрицательным. Операндами оператора конкатенации || обычно служат цепочки литер; результат также является цепочкой. Операнды других базовых типов перед выполнением конкатенации преобразуются в цепочки, соответствующие их представлению при выводе. Функция FLOOR преобразует вещественный параметр в вещественное число, равное целому, не превосходящему параметр. Результатом функции LENGTH является целое число, равное длине цепочки-параметра. Первый параметр функции SUBSTR — цепочка; результатом служит подцепочка, начальная литера которой обозначена вторым целочисленным параметром (счет идет от нуля), а длина задана третьим целочисленным параметром. Функция CHARACTER преобразует целочисленный параметр в цепочку из одной литеры, имеющей в алфавите данный номер. Функция NUMBER выдает в качестве целочисленного результата номер, который имеет в алфавите первая литера цепочки-параметра. Функция FLOAT преобразует целочисленный параметр в вещественный результат, a FIX преобразует вещественный параметр в целочисленный результат. Выполнение функций SUBSTR, FIX и CHARACTER может закончиться ошибкой.Переменные
<переменная>::= <идентификатор> |<переменная>, <идентификатор> |<переменная> [<выражение>] <Переменная> — это либо просто <идентификатор>, либо <переменная> с последующим именем поля, либо <переменная> с индексом. Разумеется, все <переменные> должны быть декларированы. <Идентификатор> — терминальный элемент синтаксиса. Он обязан начинаться с большой или малой буквы, за которой может следовать произвольное число букв или десятичных цифр. Резервированные слова нельзя использовать в качестве <идентификаторов>. Как резервированные слова, так и <идентификаторы> должны отделяться от других неоператорных лексем, по крайней мере, одним пробелом, комментарием или литерой перевода строки. Лексемы не могут пересекать границ записей.Константы
<константа> ::= <целая константа> |<вещественная константа> |<булева константа> |<цепочечная константа> <булева константа>::= TRUE |FALSE <Целая константа> — это непрерывная цепочка десятичных цифр. Она должна отделяться от других неоператорных лексем по крайней мере одним пробелом, комментарием или литерой перевода строки. <Вещественная константа> — это непрерывная цепочка десятичных цифр, за которой вплотную следует точка и, возможно, еще одна цепочка десятичных цифр. В остальном <вещественные константы> подчиняются тем же правилам, что и <целые константы>. <Цепочечная константа> начинается и кончается двойной кавычкой "; между ними могут стоять любые литеры, кроме двойной кавычки. Чтобы включить в цепочку двойную кавычку, ее следует записать дважды. Например, """" — цепочка ровно из одной двойной кавычки. В остальном <цепочечная константа> ведет себя аналогично <идентификаторам>. В частности, она не может содержать литер перевода строки.Вызовы функций
<вызов функции>::= <идентификатор функции> ( ) |<идентификатор функции> <список фактических параметров> <идентификатор функции>::= <идентификатор> <Идентификатор функции> — это обычный <идентификатор>, употребленный в некотором определении функции. При вызове функций без параметров следует пользоваться первой альтернативой в <вызове функции>.Лексемы
<отношение>::= < |> |= |<= |>= |<> <аддитивный оператор>::=+ |- <мультипликативный оператор>::=* |/ |MOD С точки зрения разделения лексем операторами также считаются :, ;, (, ), , , [,], &, |, II, := и не считаются XOR, NOT и MOD. Комментарии начинаются с сочетания литер /*, продолжаются любой цепочкой, не содержащей */, и заканчиваются литерами */. Комментарии могут располагаться везде, где допускаются разделяющие пробелы. Комментарии выполняют роль разделителей.Пример программы
Приводимая ниже программа иллюстрирует некоторые черты языка Мини. Чрезвычайно трудно в нескольких строках воспользоваться всеми возможностями, однако программа Эратосфен позволяет ощутить дух Мини. Ее можно использовать и как тест для компиляторов, поскольку выводимая информация очевидна, а вычисления нетривиальны. Пожалуй, единственным трюком (заимствованным из Алгола) является использование управляющих значений цикла для проведения вычислений в функции integersqrt. Вот текст программы. [57]

Операционная среда
Для выполнения написанных на Мини программ требуется довольно развитая поддерживающая система. Рекурсивные процедуры требуют наличия активационного стека. Для работы с цепочками нужна куча. Ввод/вывод нуждается в связи с супервизором. Вероятно, в крупных реализациях можно воспользоваться поддержкой библиотечных программ, однако они делают больше того, что нужно для наших целей. Предпочтительнее обеспечить обслуживание посредством супервизорных вызовов управляющей программы, которую можно написать на вашем любимом языке. Тема. Напишите компилятор с Мини, порождающий перемещаемый объектный код для ЭВМ УМ-1 или другой вычислительной машины (см. гл. 25). Проверьте ваш компилятор, написав на Мини несколько программ, скомпилировав их, загрузив с помощью загрузчика УМ (см. гл. 26) и выполнив на ЭВМ УМ-1. Удостоверьтесь, что компилятор допускает все синтаксически и лексически правильные программы и отбраковывает все неправильные (семантические ошибки могут прервать компиляцию программы, правильной в других отношениях). При обработке ошибок не требуется исправлять ошибки или продолжать компиляцию, но необходимо точно указать причину и место ошибки. Листинг можно печатать без всяких хитростей — вам хватит других забот. Тщательно документируйте ход выполнения работы и встретившиеся трудности. Указания исполнителю. Перед вами самый крупный проект книги. Его полное осуществление потребует от вас мобилизации всех ресурсов. Обычно проекты подбирались так, что для их решения писалась, начиная с нуля, законченная программа. В данном случае постарайтесь использовать все доступные инструменты конструирования компиляторов. В частности, сейчас широко распространены программы синтаксического анализа, управляемые описанием грамматики. Они помогут вам сэкономить много времени. Программировать следует на языке высокого уровня (помните, что за эффективностью мы не гонимся). Язык с встроенными операциями над цепочками значительно ускорит разработку компилятора. Конкретные методы конструирования компиляторов описаны в книгах, перечисленных в списке литературы. Не будем повторяться, а предложим лишь порядок реализации методов: сначала лексический анализатор, затем синтаксический анализатор и, наконец, семантический синтезатор и генератор кода. Подобный подход позволит проводить тестирование по мере продвижения вперед, а не уповать на то, что, когда все будет сделано, оно сразу заработает правильно. Вполне вероятно, что проект останется незавершенным. Поэтому целесообразно наметить очередность реализации различных возможностей языка. Если порядок выбран правильно, конечный продукт станет подмножеством Мини. Начните с реализации отдельных {программных сегментов). Внутри них попытайтесь реализовать (выражения), основные типы инструкций, внутренние процедуры, декларации переменных с (базовыми типами). Пожалуй, труднее всего сгенерировать код для (инструкции цикла); оставьте это напоследок. На начальной стадии вам придется написать подпрограммы для вывода перемещаемого объектного кода; постарайтесь, чтобы ими было легко воспользоваться в дальнейшем. Несомненно, в операционную среду Мини войдет стековая дисциплина выделения памяти для процедур. Когда остальные инструкции достаточно обкатаются, принимайтесь за структурные типы данных. Размещение цепочек во время выполнения требует кучи, которая, вероятно, будет разделять память со стеком. Указанные механизмы выделения памяти вызовут изменения в супервизоре УМ-1. Ранние версии не должны включать сбор мусора для утилизации освободившихся частей. Параллельно с распределением памяти можно работать над компиляцией раздельных сегментов. Не забудьте с самого начала вставить в объектные модули код для отладки. Инструментовка. Пишите компилятор на каком-либо процедурном языке высокого уровня. Язык XPL как раз и предназначен для конструирования компиляторов. Сноболом пользоваться не следует, поскольку на этом языке компиляторы реализуются слишком легко и вы не получите необходимой подготовки.Длительность исполнения.
Двоим, троим или четверым на 10 недель. Каждый участник независимо отвечает за одну тестовую программу на Мини.Литература
Грис (Gries D.). Compiler Construction for Digital Computers. Wiley, New York, NY, 1971. [Имеется перевод: Грис Д. Конструирование компиляторов для цифровых вычислительных машин. — М.: Мир, 1975.] Выдающаяся книга по реализации компиляторов. В ней описано все о простых компиляторах и даны указания по сложным. Правда, остались недостаточно освещенными таблично-управляемые методы разбора LR(k), но этот пробел с избытком покрывают другие упоминаемые здесь книги. Если вы уже выбрали язык для компиляции, Грис покажет, как ее провести. Мак-Киман, Хорнинг, Уортмен (McKeeman W. M., Horning J. J. Wortman D. В.), A Compiler Generator. Prentice-Hall, Englewood Cliffs, NJ, 1970. В книге описывается язык XPL и его использование для конструирования компиляторов, В качестве иллюстрации метода приведен компилятор с XPL, написанный на XPL. В первых изданиях использовался ныне устаревший таблично-управляемый метод разбора SMSP, однако в следующих изданиях подробно обсуждается разбор LR(k). К сожалению, опубликованный листинг не претерпел изменений в сторону LR(k). He вошел и табличный генератор Де Ремера SLR(k). Книга может служить руководством по JCPL. Николс (Nickholls J. E.). Тhe Structure and Design of Programming Languages. Addison-Wesley, Reading, MA, 1975. Пратт (Pratt T. W.) Programming Languages Design and Implementation. Prentice Hall, Englewood Cliffs, NJ, 1975. [Имеется перевод: Пратт Т. Языки программирования: разработка и реализация. — М.: Мир, 1979.] Обе книги нужно читать до проектирования языка и реализации компилятора. В них внимание сконцентрировано не на конкретных методах компиляции, а на изучении влияния языковых структур на программиста, поддерживаемую систему, конечного пользователя и разработчика компилятора. Авторы тщательно взвешивают все «за» и «против» различных решений при создании языка программирования. Ахо А., Ульман Дж. Теория синтаксического анализа, перевода я компиляции. Т. 1, 2. — Пер. с англ. — М.: Мир, 1978.28. Новый атТРАКцион, или... ПОСТРОЕНИЕ ИНТЕРПРЕТАТОРА ЯЗЫКА ТРАК
Немного найдется языков программирования, которые начинающий программист мог бы реализовать в одиночку всего за несколько недель, но Трак (TRAC) [58] — как раз такой язык. Целью разработчика Трака Калвина Муэрса было создание простого, элегантного, мощного и к тому же интерактивного языка. Он ухитрился на основе старой идеи макро сделать язык, который удовлетворяет всем этим требованиям, может использоваться также в пакетном режиме и вдобавок ко всему необычайно прост для реализации (для написания первого процессора хватило двух выходных дней). Для набора и редактирования рукописи английского оригинала книги использовался некоторый диалект языка Трак.Язык Трак
Представьте, что перед вами интерактивный терминал, который позволяет работать с процессором Трака. Вы набираете свои программы на клавиатуре, переходя, если нужно, с одной строки на другую и заканчивая каждую программу специальной заключительной металитерой (первоначально это апостроф '); эти программы сразу же выполняются. Как только процессор встречает металитеру, он интерпретирует вашу программу и выдает результаты работы на терминал. После этого вы можете набрать новую программу, вызывая тем самым повторение этого цикла. Сама программа может представлять собой любую цепочку литер, но некоторые специальные подцепочки служат для вызова встроенных функций Трака. Функции можно использовать для самых обычных действий с числами или с текстами, но они могут также записывать или извлекать результаты других функций, так что из их значений можно сложить огромные пирамиды. Вызов функции выглядит как #(…) или ##(…), причем внутри скобок снова стоит произвольная цепочка. Тело функции разбито запятыми на аргументы (отсутствие запятых означает, что имеется один аргумент), вычисляемые слева направо по тем же правилам, что и вся программа. Предполагается, что первым аргументом является имя встроенной функции, остальные аргументы передаются этой функции для вычисления значения. Если вызов функции записан с одним диезом в виде #(...), то результат функции повторно сканируется, в противном случае результат передается дальше без обработки. Запись (...), где в цепочке внутри скобок соблюдается баланс скобок, защищает эту цепочку от вычисления. Процессор просто удаляет внешние скобки и оставляет внутренность без внимания. Так, если ум означает функцию умножения, а сл — функцию сложения, то результатом вычисления входной цепочки ((3 + 4)) * 9 = # (ум, # (сл, 3, 4), 9)' будет цепочка (3+4)*9 = 63 Обратите внимание на вторую пару скобок вокруг 3 + 4; они необходимы, чтобы в выходной цепочке 3 + 4 осталось заключенным в скобки. Все действия процессора подчиняются точно сформулированной процедуре, называемой алгоритмом Трак. Процессор содержит три структуры: активную цепочку, нейтральную цепочку и указатель сканирования. Для наглядности обычно считают, что нейтральная цепочка располагается слева, указатель сканирования — посередине и активная цепочка — справа. Указатель сканирования всегда указывает на левый конец активной цепочки, обозревая первую литеру. Литеры, как правило, переходят из активной в нейтральную цепочку; там литеры накапливаются до тех пор, пока их не станет достаточно для построения всех аргументов некоторой функции. Тогда эта функция выполняется и ее результат помещается в активную или нейтральную цепочку в соответствии с типом функции.Алгоритм Трак
Алгоритм состоит из 10 пронумерованных шагов. Работа процессора начинается с шага 1. В алгоритме кое-где говорится о различных отметках литер нейтральной цепочки. Представляйте себе эти отметки как флажки, поставленные у отмеченных литер (конечно, в реализации отметки будут представлены, вероятно, указателями). В любой практической реализации существует специальная клавиша «прерывание» для прекращения бесконечного цикла, предписанного алгоритмом. 1. Очистить процессор; для этого опустошить нейтральную цепочку, удалить содержимое активной цепочки, если оно есть, поместить туда цепочку # (пц, # (чц)) и установить указатель сканирования на первую литеру активной цепочки [59]. Перейти к следующему шагу. 2. Проанализировать литеру, на которую указывает указатель сканирования. Если ее нет, т. е. активная цепочка пуста, вернуться к шагу 1. 3. Если под указателем сканирования — литера табуляции, перевода строки, конца записи или возврата каретки, то удалить ее, продвинуть указатель к следующей литере и вернуться к шагу 2. 4. Если под указателем сканирования — левая скобка, то удалить ее и просмотреть активную цепочку вперед, пока не будет найдена соответствующая ей правая скобка. Переместить в неизменном виде все расположенные между этими скобками литеры в нейтральную цепочку, удалить правую скобку, продвинуть указатель сканирования вперед к следующей за ней литере и после этого вернуться к шагу 2. Если соответствующую правую скобку не удается найти, то вернуться к шагу 1. 5. Если литера, находящаяся под указателем сканирования,— запятая, то удалить ее, пометить самую правую литеру нейтральной цепочки как конец одного аргумента, а следующую литеру — как начало нового аргумента, продвинуть вперед указатель сканирования и вернуться к шагу 2. 6. Если под указателем сканирования — знак диез, а следующая литера — левая скобка, то это означает, что перед нами — начало активной функции. Удалить диез и скобку, продвинуть указатель сканирования после них, отметить самую правую литеру нейтральной цепочки одновременно как начало аргумента и начало активной функции и вернуться к шагу 2. 7. Если под указателем сканирования — знак диез и вслед за ним стоят еще один диез и левая скобка, то это значит, что начинается нейтральная функция. Удалить три литеры ##(, продвинуть указатель после них, отметить самую правую литеру нейтральной цепочки одновременно как начало аргумента и начало нейтральной функции и вернуться к шагу 2. 8. Если под указателем сканирования находится знак диез, но условия шагов 6, 7 не выполняются, то переместить диез в правый конец нейтральной цепочки, передвинуть указатель и вернуться к шагу 2. 9. Если под указателем сканирования оказалась правая скобка, это говорит об окончании функции. Удалить эту скобку, передвинуть указатель сканирования и отметить самую правую литеру нейтральной цепочки как конец аргумента и конец функции. Теперь нейтральная цепочка от самой правой отметки начала функции до только что поставленной отметки конца функции составляет вызов функции Трака. (Если в нейтральной цепочке нет отметки начала функции, то вернуться к шагу 1.) Удалить из нейтральной цепочки аргументы функции (все те аргументы, отметки которых стоят после отметки начала функции) вместе с отметками функции и аргументов. (Ввиду способа нанесения отметок все отметки начала стоят в действительности у литер, непосредственно предшествующих отмечаемым элементам.) Предполагается, что первым аргументом является имя встроенной функции Трака. Вычислить функцию с данными аргументами; лишние аргументы игнорируются, недостающие аргументы автоматически добавляются со значением «пустая цепочка». Значение функции присоединяется справа к нейтральной цепочке, если функция была отмечена как нейтральная, и слева к активной цепочке, если функция была отмечена как активная; в последнем случае указатель сканирования устанавливается на левый конец новой активной цепочки. Если первый аргумент не является именем никакой встроенной функции, то просто поместить в качестве результата функции пустую цепочку. Вернуться к шагу 2. 10. Если литера под указателем сканирования не удовлетворяет ни одному из условий шагов с 3-го по 9-й, то присоединить ее к правому концу нейтральной цепочки, удалить ее из активной цепочки, передвинуть указатель сканирования и вернуться к шагу 2.Функции Трака
Ниже перечислены функции Трака в активной записи, но все они могут вызываться также и в нейтральном режиме. У функции всегда есть значение в виде цепочки, однако функциям не возбраняется выдать в качестве значения пустую цепочку; в особенности это имеет смысл для тех функций, результат которых выражается в побочных эффектах. В дополнение к уже упомянутым структурам процессор может записывать цепочки в некоторой области памяти, называемой памятью бланков. Каждый бланк состоит из трех частей: имени бланка, в качестве которого может выступать любая цепочка, тела бланка, которое тоже может быть любой цепочкой, и указателя бланка, первоначально указывающего на позицию непосредственно перед первой литерой тела бланка. Указатель бланка всегда указывает на позицию непосредственно перед телом, непосредственно после него или между двумя литерами; иначе говоря, он всегда указывает на промежуток между литерами. В телах бланков вперемежку с литерами могут находиться порядковые метки сегментов. С каждой такой меткой связано некоторое положительное целое число, причем эти числа у разных меток не обязаны различаться. Приведенные ниже описания функций слегка переработаны в сравнении с предложениями Муэрса: #чц «Чтение цепочки» (один аргумент). Значением этой функции является входной поток литер до ближайшей литеры (не включая ее). В результирующую цепочку входят все возвраты каретки, переводы строк, концы записей и литеры табуляции, которые система передает программе в обычных условиях. Металитера всегда отбрасывается, а в системах, ориентированных на использование записей, отбрасывается также и все после металитеры в той же записи. #чл «Чтение литеры» (один аргумент). В качестве значения функции выдается следующая входная литера, какой бы она ни оказалась. Этим способом можно прочитать любую литеру, включая металитеру. #(пц,X) «Печать цепочки» (два аргумента). Второй аргумент X печатается на устройстве вывода. Значением функции является пустая цепочка. #(им,X) «Изменение металитеры» (два аргумента). Эта функция с пустым значением (со значением «пустая цепочка») делает металитерой первую литеру цепочки X. Первоначально роль металитеры играет апостроф. #(оц,N,В) «Определение цепочки» (три аргумента). Эта функция с пустым значением создает бланк с именем N и телом В. Указатель этого бланка указывает на точку перед первой литерой В. Если бланк с именем N уже существовал, то его предыдущее тело и указатель теряются. #(сц,N,P1,P2,...) «Сегментация цепочки» (не менее трех аргументов). Эта функция с пустым значением создает в бланке N порядковые метки сегментов. Непустые аргументы Р1, Р2, ... обрабатываются поочередно, слева направо (пустые аргументы игнорируются). Обработка одного аргумента Pi состоит в следующем. Тело бланка N просматривается слева направо, пока не будет найдена подцепочка, в точности равная Pi Эта подцепочка не должна содержать никаких ранее поставленных меток сегментов. Если это так, то подцепочка выбрасывается из тела бланка и на ее место ставится порядковая метка сегмента с номером i. Затем процесс поиска совпадающей подцепочки возобновляется с литеры, лежащей вслед за меткой. После окончания сегментации указатель бланка устанавливается на левый конец бланка. Можно несколько раз сегментировать один бланк. #(вц,N,А1,А2,...) «Вызов цепочки» (два или больше аргументов). Значением этой функции является тело бланка N, в котором метки сегментов заменены на некоторые подцепочки. Все метки с номером 1 заменяются на аргумент А1, метки с номером 2 — на А2 и т. д. Функции вц требуется такое количество аргументов, каков наибольший номер сегмента в бланке N. Напомним, что лишние аргументы игнорируются, а недостающие считаются пустыми цепочками. #(вс,N,Z) «Вызов сегмента» (три аргумента). Значением этой функции является подцепочка бланка N от текущего положения указателя бланка до ближайшей справа метки сегмента (в данной функции конец тела рассматривается как метка). Метка не входит в значение функции; указатель бланка помещается непосредственно перед литерой, ближайшей справа к найденной метке. Если перед выполнением функции указатель бланка уже указывал на правый край тела, то значением функции будет аргумент Z, возвращаемый в активном режиме, независимо от режима вызова функции. #(вл,N,Z) «Вызов литеры» (три аргумента). Значением функции является литера, лежащая сразу вслед за указателем бланка в бланке N. Указательпередвигается в промежуток, следующий за выбранной литерой. Указатель бланка пропускает все метки сегментов, поскольку они — не литеры. Если указатель бланка уже указывает на правый край цепочки, то в качестве значения функции выдается аргумент Z в активном режиме независимо от режима вызова функции. #(вн,N,D,Z) «Вызов нескольких литер» (четыре аргумента). Значением функции является подцепочка бланка N. Эта подцепочка начинается от текущего положения указателя бланка и содержит |D| литер вправо от него, если D положительно, или влево, если D отрицательно [60]. Литеры в значении функции расположены в том же порядке, что и в теле бланка, т. е. при отрицательном D цепочка не обращается. Метки сегментов, конечно, игнорируются. Указатель бланка передвигается в точку между выбранной подцепочкой и первой непрочитанной литерой в заданном направлении. (Если D равно нулю, то значением будет пустая цепочка, а указатель останется на месте.) Если указателю бланка приходится покинуть цепочку на любом из концов, то значением функции будет аргумент Z, помещаемый в активную цепочку, независимо от режима вызова функции. #(вн,N,X,Z) «Первое совпадение» (четыре аргумента). Бланк N просматривается вправо от указателя бланка в поисках подцепочки, совпадающей с X и не содержащей меток сегментов. Если такое совпадение найдено, то значением функции будет подцепочка бланка от исходного положения указателя до литеры, находящейся непосредственно перед совпадающей подцепочкой (из значения удаляются метки сегментов), а указатель бланка будет переставлен так, чтобы указывать на позицию непосредственно перед литерой, находящейся непосредственно после совпавшей подцепочки. Если совпадения не найдено, то значением функции будет аргумент Z в активном режиме независимо от режима вызова функции, а указатель бланка останется на прежнем месте. #(пу,N) «Переустановка указателя» (два аргумента). Эта функция с пустым значением возвращает указатель бланка N в его исходное положение перед первой литерой бланка. #(уо,N1,N2…) «Удалить определение» (два или более аргумента). Эта функция с пустым значением удаляет бланки с именами N1, N2, … из памяти бланков. #(ув) «Удалить все» (один аргумент). Эта функция с пустым значением удаляет из памяти бланков все бланки. Трак выполняет арифметические действия над цепочками из «десятичных» литер. У каждой цепочки имеется арифметическое значение. Оно определяется наиболее длинной подцепочкой, примыкающей к правому краю цепочки и состоящей только из десятичных цифр, перед которыми стоит не более одного знака плюс или минус. Так, арифметическим значением 3 является три, значением а — 4 является минус четыре, + + + +200 имеет значение двести, а значением пустой цепочки и abc является пустая цепочка. В арифметических операциях пустая цепочка воспринимается как нуль. Точность арифметических действий не ограничена — мы не должны подстраиваться под ограничения какой-либо реальной аппаратуры. Результат арифметических операций также будет содержать десятичную цепочку того же вида без старших нулей и без плюса для положительных чисел; нуль будет представлен как 0. #(сл,А,В) «Сложение» (три аргумента). Значением функции является сумма арифметических значений аргументов, перед которой помещена начальная нечисловая часть аргумента А. Начальная часть аргумента В теряется. #(вч,А,В) «Вычитание» (три аргумента). Значением функции является результат вычитания арифметического значения аргумента В из арифметического значения А; начальная нечисловая часть А присоединяется спереди к полученной десятичной цепочке, а начальная часть В теряется. #(ум,А,В) «Умножение» (три аргумента). Значением функций является произведение арифметических значений аргументов А и В, перед которым помещена начальная нечисловая часть А. Начальная часть В теряется. #(дл,А,В,Z) «Деление» (четыре аргумента). Значением функции является частное от деления числового значения аргумента А на числовое значение В, перед результатом помещается начальная часть А. Начальная часть В теряется. Выполняется целочисленное деление, у частного сохраняется только целая часть; остаток всегда неотрицателен. Если В имеет значение нуль, то значением функции будет аргумент Z в активном режиме независимо от режима вызова функции. Аналогично арифметическим значениям в Траке функционируют логические значения. Логическим значением цепочки считается наиболее длинная ее правая часть, состоящая целиком из нулей и единиц, т. е. являющаяся двоичной цепочкой. Так, цепочка abc0100 имеет логическое значение 0100, цепочка 1234567890 — значение 0, цепочка 43210—10, а логическим значением abc является, по определению, пустая цепочка. #(ло,А,В) «Логическое объединение» (три аргумента). Значением этой функции является побитовое логическое объединение Логических значений аргументов А и В. Если они имеют разные длины, то более короткое дополняется слева необходимым количеством нулей для уравнивания длин. Любые нелогические начальные части аргументов теряются. #(лп,А,В) «Логическое пересечение» (три аргумента). Значением функции является побитовое логическое пересечение логических значений аргументов Л и В. Если аргументы имеют неравные длины, то более длинный усекается слева для выравнивания длин. Любые нелогические начальные части аргументов теряются. #(лд,А) «Логическое дополнение» (два аргумента). Значение этой функции — побитовое логическое дополнение аргумента А, имеющее ту же длину. Нелогическая начальная часть аргумента теряется. #(лс,S,А) «Логический сдвиг» (три аргумента). Значением этой функции является сдвинутое логическое значение аргумента A. Величина сдвига дается арифметическим значением аргумента S. Если оно положительно, то происходит сдвиг влево, если отрицательно — то вправо. Значение функции имеет ту же длину, что логическое значение A; освобождающиеся позиции заполняются нулями. Нелогическая начальная часть А теряется. #(лц,S,А) «Логический циклический сдвиг» (три аргумента). Значением функции является результат циклического сдвига (поворота) логического значения аргумента А. Величина сдвига задается арифметическим значением аргумента S; сдвиг происходит влево, если значение S положительно, и вправо, если оно отрицательно. Циклический сдвиг не меняет длины аргумента. Нелогическая начальная часть А теряется. #(рв,A,B,T,F) «Равенство» (пять аргументов). Если аргумент А в точности совпадает как цепочка с аргументом В, то значением функции является аргумент Г, в противном случае значение функции — аргумент F. Отметим, что Т и F могут быть любыми цепочками. #(бл,A,B,T,F) «Больше» (пять аргументов). Значением этой функции является аргумент Т, если арифметическое значение А больше арифметического значения В, и аргумент F в противном случае. #(зб,A,F1,F2…) «Запись блока» (три или больше аргументов). Функция записывает бланки с именами F1, F2, ... на некоторое внешнее запоминающее устройство. После записи всех бланков они удаляются из памяти бланков и создается новый бланк с именем A, тело которого есть адрес во внешней памяти записанного блока бланков. Если уже есть бланк с именем A, то его старое значение теряется. «Адресом» блока должна быть цепочка; доступ к бланкам во внешней памяти осуществляется при помощи любого бланка, имеющего значением цепочку-адрес. Значение этой функции — пустая цепочка. #(иб,A) «Извлечь блок» (два аргумента). Эта функция с пустым значением извлекает из внешней памяти блок бланков, «адрес» которого находится в теле бланка с именем А. Бланки возвращаются в память бланков, и если какие-либо из них уже существуют, то прочитанные значения заменяют их старые значения. Внешний блок бланков по-прежнему остается доступным. #(уб,А) «Удалить блок» (два аргумента). Эта, функция с пустым значением освобождает внешнюю память, в которой хранится блок по адресу, указанному в теле бланка А; этот блок становится недоступным. Одновременно удаляется бланк А. #(си,S) «Список имен» (два аргумента). Значение этой функции— список имен всех бланков, присутствующих в данный момент в памяти бланков. Имена разделяются цепочкой S. #(пб,N) «Печать бланка» (два аргумента). Эта функция с пустым значением печатает тело бланка N; на печать выдаются также указатель бланка и метки сегментов. Муэрс предлагает печатать указатель бланка в виде <↑>, а метку сегмента — в виде <i>. Таким образом, результатом пб может быть нечто вроде aB<2>cdE<1><f><↑><1>hiJ; мы видим одно вхождение метки 2 и два вхождения метки 1. #(вт) «Включение трассировки» (один аргумент). Эта функция с пустым значением заставляет процессор начать трассировку выполнения функций. Всякий раз, когда функция готова к выполнению, на устройство вывода выдаются все ее аргументы. Если процессор работает в интерактивной системе, то после печати каждого списка аргументов делается пауза, позволяющая пользователю ввести некоторую цепочку. Если это будет пустая цепочка, то процессор продолжает работу, вычисляя функцию; любая другая цепочка вызывает переход к шагу 1 алгоритма Трак. #(кт) «Выключение (конец) трассировки» (один аргумент). Эта функция с пустым значением выключает трассировку; если трассировка не была включена, то выполнение функции не оказывает никакого воздействия.Примеры
Следующие примеры помогут вам почувствовать некоторые возможности языка Трак. Не думайте, однако, что эти конкретные примеры иллюстрируют все возможности каких-либо функций.#(оц,АА,Кот)’ #(оц,ВВ,(#(вц,АА)))’ #(пц,(#(вц,ВВ)))' #(пц,##(вц,ВВ))' #(пц,#(вц,ВВ))’Выполнение первой строки из этого ряда программ (заметьте, что каждая строка оканчивается металитерой — апострофом) приводит к запоминанию бланка с именем АА и телом Кот и к печати пустой цепочки. Вторая строка аналогичным образом создает бланк с телом #(вц,АА) и именем ВВ и печатает пустую цепочку. Дальше начинается самое интересное. Функция пц в третьей строке печатает #(вц,ВВ), поскольку внутренняя функция защищена скобками; та же функция в четвертой строке печатает #(вц,АА), поскольку внутренняя функция — нейтральная и, наконец, при выполнении пятой строки печатается Кот.
#(уо,#(си,(,)))'Эта программа делает точно то же, что и вызов #(ув). Аргументами уо должны быть имена бланков, и си генерирует список имен, разделенных запятыми.
#(оц, Факториал,(#(рв,Х,1,1,(#(ум,X,#(вц, Факториал,#(вч,Х,1)))))))' #(cц, Факториал,X)’ #(вц, Факториал,5)’В этих трех строках стандартным рекурсивным способом определяется функция факториал, цепочка Факториал сегментируется по аргументу X и затем вычисляется значение 5!. Необходимы обе пары защитных скобок; внешняя защищает рв от выполнения в момент создания бланка, а внутренняя позволяет избежать умножения в случае истинности условия. Попытайтесь удалить любую из этих пар скобок или заменить вызов рв на нейтральный.
#(вц, Факториал,5 #(оц, Факториал,( #(рв,Х,1, 1, #(ум,X,#(вц, Факториал,#(вч,Х,1))))))) #(cц, Факториал,X)’Этот пример делает то же, что предыдущий — определяет функцию факториал и вычисляет 5!. Однако здесь используется то, что аргументы функции вычисляются до вычисления самой функции; это позволяет спрятать определение и сегментацию бланка Факториал внутрь его вызова. Отметим, что после аргумента 5 вызова Факториал не нужно ставить запятую, поскольку он всегда возвращает в качестве значения пустую цепочку. Тема. Напишите процессор Трака для вашей системы. Процессор должен реализовывать описанные выше алгоритм Трак и встроенные функции. Если в вашей системе имеется возможность хранения файлов, используйте ее для организации внешней памяти бланков. Блоки, записанные в каком-либо сеансе работы с процессором, должны быть доступны в последующих сеансах. Разумно будет включить в ваш процессор как можно больше внутренних средств отладки. Рекомендации исполнителю. В каждой системе приняты свои соглашения относительно набора литер и способа завершения строки. Один из шагов алгоритма Трак выбрасывает из сканируемого текста незащищенные литеры возврата каретки, перевода строки и табуляции. Это позволяет спокойно вводить исходные данные, не думая о возможности случайного разбиения программы на несколько строк вследствие ограничений на длину строки физических устройств. Но выбрасывание этих литер означает также, что их следует явно указывать во входном потоке, чтобы мы могли при желании управлять форматом вывода программы. Так, например, если CR-LF обозначает последовательность литер «возврат каретки — перевод строки», то при вводе цепочки Один CR-LF Два мы увидим на печати ОдинДва в одной строке, в то же время исходные данные Один(CR-LF)Два приведут к печати слова Один на одной строке, а Два — на следующей. Позаботьтесь о том, чтобы ваш процессор правильно работал в этой ситуации. Описывая алгоритм, мы лихо проскочили вопрос об установке и поиске меток аргументов и функций в нейтральной цепочке. На самом деле весьма важно всегда иметь точный список функций и аргументов, в котором указан, в частности, порядок их появления. Проще всего добиться этого с помощью стека. Этим стеком распоряжается исключительно процессор. Каждый раз, когда алгоритм выполняет шаг 1, стек устанавливается в пустое состояние. При маркировке любого начала функции на стек помещается новый блок функции. В блоке функции имеется основная часть постоянного вида, включающая, как минимум, положение в стеке ближайшего нижнего, блока функции, режим вызова данной функции, положение в нейтральной цепочке первой литеры функции, число аргументов функции, обработка которых начата, и число законченных аргументов и положение в нейтральной цепочке начала аргумента, который в данный момент сканируется. Выше постоянной части в стеке располагаются элементы, указывающие для каждого законченного аргумента его начало и конец. Часть этой информации может неявно присутствовать в других местах. Среди типичных ошибок реализации — неправильная работа с пустой цепочкой и потеря информации о функциях, расположенных в нижней части стека, при обработке вышележащих функций. Память бланков точно так же требует большего внимания, чем ей уделялось в предшествующем изложении. Поскольку как имя, так и тело бланка представляют собой цепочки, имеет смысл хранить их вместе в некоторой разновидности памяти для цепочек. Необходимо также место, где хранились бы указатель бланка и метки сегментов; кроме того, нужно уметь находить бланки. В такой ситуации проще всего выделить достаточно большое пространство бланков и хранить бланки в виде связанного списка. У каждого бланка будет головная часть фиксированного размера; она будет включать указатель на следующий бланк, указатель бланка, начальную позицию и длину имени бланка, а также начало и длину тела. Имя и тело можно хранить сразу вслед за головной частью, а метку сегмента можно представлять некоторой парой литер, окружающих целое число (конечно, необходимо иметь какой-либо другой способ изобразить литеры метки как обычные литеры). Для выполнения поиска бланка можно пройти по списку бланков, а для исключения бланка можно удалить его из списка с помощью перестановки указателей, а затем передвинуть окружающие бланки, чтобы заполнить образовавшуюся дыру. Существуют и другие способы организации памяти бланков; каждому способу присущи свои достоинства и недостатки. Распределение памяти для процессора также не простая задача. Потребность в памяти для любой из структур — нейтральной цепочки, активной цепочки, стека аргументов и памяти бланков — может превзойти любую заранее установленную границу. Если для этих структур выделяются фиксированные области памяти, то любая из них может переполниться, в то время как в остальных свободного пространства будет хоть отбавляй. Имеется стандартный путь решения этой проблемы. Рассмотрим сначала нейтральную и активную цепочки. Поскольку нейтральная цепочка естественно смотрится слева от активной, выделим им одну область памяти на двоих; в этой области нейтральная цепочка будет расти от левого края вправо, а активная цепочка, наоборот, от правого края влево. При таком способе действий переполнение памяти не наступит, пока активная и нейтральная цепочки не используют в сумме всю выделенную им память. Стек аргументов можно таким же образом объединить с памятью бланков; один из двух промежутков между объединенными парами можно использовать для временного хранения цепочек, переписываемых с одного места на другое. Возможны дальнейшие усовершенствования. Выделим память для всех динамических структур в одной большой области, в которой разместим слева направо нейтральную цепочку, растущую вправо, свободный промежуток, активную цепочку, растущую влево, без всякого промежутка стек аргументов, свободный промежуток и память бланков, растущую влево. Если теперь активная и нейтральная цепочки израсходуют все пространство, в то время как между стеком аргументов и памятью бланков еще что-то останется, то передвинем активную цепочку и стек аргументов как единое целое вправо на некоторое расстояние, передавая тем самым часть пространства из правого свободного промежутка в левый. Разумеется, тот же прием работает и в другую сторону, так что процессор не останется без памяти, пока ему будет откуда ее взять. Обсуждая распределение памяти, мы считали, что нам удастся урвать большой аморфный кусок памяти, в котором можно хранить все, что нам будет угодно: литеры, указатели, целые числа, логические флажки и т. д. В языках программирования, по крайней мере в таких, как Паскаль или Алгол, это весьма затруднительно, если вообще возможно. Конечно, в языке ассемблера вся память аморфна, но платой за такую свободу обычно бывают ошибки в обращениях к памяти. Очень часто приходится выбирать между удобством и безопасностью; обычно находят какое-либо компромиссное решение. Вы неизбежно столкнетесь с этой проблемой при выборе языка программирования для реализации. В вашем процессоре должен быть достаточный набор инструментов анализа, так чтобы процессор вычислял, записывал и выдавал такие величины, как число выполнений каждого шага алгоритма и каждой встроенной функции, максимальная длина каждой внутренней области памяти, число переупаковок памяти из-за переполнений и число вызовов каждой внутренней подпрограммы. Такие инструменты решают три задачи. Во-первых, они служат средством отладки. Если между выдаваемыми числами существует какая-либо априорная зависимость и она не выполняется или если значения некоторых счетчиков не лезут ни в какие ворота, то, вероятно, это указывает на ошибку. Во-вторых, значения счетчиков помогут вам усовершенствовать именно те подпрограммы, которые затрачивают наибольшее время, и настроить параметры алгоритма распределения памяти. И наконец, значения счетчиков, оформленные подходящим образом и с необходимыми разъяснениями, помогут пользователю Трака в правильном и эффективном использовании процессора. Вероятно, значения счетчиков следует сообщать пользователю в конце каждого сеанса. Инструментовка. На примере этой задачи можно еще раз изучить влияние языка на программирование. Если вы изберете язык высокого уровня типа Паскаля с его многочисленными мерами безопасности, то обнаружите, что большую часть процессора до абсурда легко закодировать, но за эту легкость, вероятно, придется заплатить потерей эффективности и трудностями при реализации распределения памяти. Если, напротив, остановитесь на языке ассемблера, то вполне может случиться, что ваша программа будет эффективной как по памяти, так и по времени, но она будет очень длинной и трудной для отладки, причем вам придется написать многие из тех подпрограмм, которые предоставляются другими языками программирования. Использование языков промежуточного уровня: XPL, BLISS или Фортрана — быть может, объединит преимущества (и, возможно, недостатки) двух крайних подходов. Не исключено также, что некоторые части программы придется написать на одном языке, а остальную программу — на другом. Как бы то ни было, в документации необходимо обосновать выбор языка и привести соображения, которые возникнут у вас по окончании работы. Длительность исполнения. Для решения этой задачи в одиночку потребуется 7 недель, вдвоем — 4 недели, втроем — 3 недели. Развитие темы. Один очевидный способ расширить Трак — это допустить вызов бланка в виде функции с именем бланка в качестве первого аргумента, т. е. преобразовывать #(XYZ, ..., ... ) в #(вц, XYZ, ..., ). Если ввести правило, согласно которому телом неопределенного бланка считается пустая цепочка, то описанное выше преобразование автоматически обеспечивает пустое значение для неопределенной функции. Если, кроме того, просматривать бланки перед встроенными функциями, то пользователь сможет заменить какие-либо встроенные функции функциями, изготовленными специально для него. Еще один очевидный способ расширения — добавление новых встроенных функций. Предлагаем два набора встроенных функций. Первый дает дополнительные удобства при работе с цепочками и литерами. Второй набор расширяет возможности ввода/вывода.
Обработка цепочек и литер
#(зм) «Запрос металитеры» (один аргумент). Значением этой функции является однолитерная цепочка, состоящая из текущей металитеры. #(дц,А) «Длина цепочки» (два аргумента). Значением функции является длина цепочки А в виде десятичной цепочки. Длина пустой цепочки равняется нулю. #(нл,С) «Номер литеры» (два аргумента). Значением функции является десятичная цепочка, дающая номер первой литеры аргумента С в наборе литер конкретной реализации. Если цепочка С пуста, то и значение функции пусто. #(лн,D) «Литера по номеру» (два аргумента). Значением этой функции является цепочка из одной литеры, номер которой в наборе литер конкретной реализации задается арифметическим значением аргумента D. Если литеры, с таким номером не существует, то значение функции — пустая цепочка. #(дс,N) «Диапазон сегментов» (два аргумента). Значение этой функции — десятичная цепочка, равная максимальному номеру метки сегмента в бланке, имя которого задано аргументом N. Если такого бланка нет или в нем нет меток сегментов, то значением функции будет нуль. #(ио,R1,R2,V) «Изменение основания» (четыре аргумента). Для вычисления значения этой функции находится арифметическое значение аргумента V в системе счисления с основанием R1, затем оно переводится в систему с основанием R2. Множество возможных цифр для всех оснований есть (в возрастающем порядке) 0, 1, … 9, A, B,..,Z. Так, двоичной системе используются цифры 0 и 1 в десятичной — от 0 до 9, в шестнадцатеричной — от 0 до F. Арифметическим значением цепочки в данной системе счисления считается наиболее длинная ее правая подцепочка, которая, возможно, начинается с + или —, а в остальном состоит только из цифр, допустимых в этой системе. Это такое же правило, как правило Трака для десятичных значений. Аргументы R1 и R2 задают систему счисления, указывая наибольшую допустимую цифру (например, 9 для десятичной системы, 1 для двоичной и F для шестнадцатеричной). Если любой из аргументов R1 или R2 не является одной литерой в диапазоне от 0 до Z, то значение функции пусто.Ввод/вывод
#(ст) «Стоп» (один аргумент). Эта функция с пустым значением вызывает немедленный выход из процессора Трака. #(пв,F,Z) «Подключение ввода» (три аргумента). Эта функция с пустым значением подключает устройство ввода к файлу, имя которого задается аргументом F, и устанавливает указатель файла на первую запись файла. Если файл не может быть подключен, то значением функции является аргумент Z в активном режиме независимо от режима вызова функции. Любой последующий вызов функции чц приводит к тому, что устройство ввода читает цепочку из файла до ближайшей металитеры и передвигает указатель файла. Если аргумент F пуст, то вновь подключается стандартный файл ввода (ввод с клавиатуры в интерактивных системах). #(пы,F) «Подключение вывода» (два аргумента). Эта функция с пустым значение подключает устройство вывода к файлу F, и если такого файла еще нет, то создает его. Если аргумент F пуст, функция возвращает вывод на стандартное устройство вывода (на экран терминала в интерактивных системах). #(уу,N) «Установка указателя» (два аргумента). Эта функция с пустым значением устанавливает указатель файла ввода на запись, расположенную после N — 1 металитер. Если это условие не определяет запись в файле или если файлом служит ввод с клавиатуры, то выполнение функции ничего не меняет. #(чу) «Чтение указателя» (один аргумент). Функция выдает в качестве значения десятичную цепочку, представляющую текущее состояние указателя файла ввода. Если файл ввода подключен к клавиатуре, то значение функции пусто, #(чц,Z) «Чтение цепочки» (два аргумента). Эта функция есть видоизменение ранее определенной функции чц. Если из текущего файла ввода невозможен ввод, то значением этой функции является аргумент Z в активном режиме независимо от, режима вызова функции.Литература
Браун (Brown P. J). Macro Processing and Techniques for Portable Software Wiley, New York, NY, 1975. [Имеется перевод: Браун П. Макропроцессоры и мобильность программного обеспечения — М.: Мир, 1977.] Муэрс (Mooers С. N.). Computer Software and Copyright, Computing Surveys, 7, I, pp. 45—72, 1975. Хотя эта статья не посвящена непосредственно Траку, ее тематика порождена, по крайней мере отчасти, опасениями за чистоту Трака. Муэрс сформулировал если не закон, то во всяком случае четкую позицию в отношении к вопросам защиты программ. Муэрс (Mooers С. N.). How Some Fundamental Problems are Treated in the Design of the TRAC Language. In Symbol Manipulation Languages and Techniques, edited by D. G. Bobrow. North-Holland Publishing Co., Amsterdam, pp. 178—190, 1968. В этой работе Муэрс обсуждает некоторые решения, принятые при проектировании Трака. Трак сравнивается с другими языками для аналогичных целей, в частности с Лиспом. Общефилософские принципы, которые вы почерпнете из этой статьи, послужат отличными дрожжами для закваски познаний по основам Трака. Муэрс (Mooers С. N.). TRAC, A Procedure-Describing Language for the Reactive Typewriter. CACM, 9, 3, pp. 215—219, 1966. Нельсон (Nelson Т. Н.). Computer Lib or Dream Machines. Hugo's Book Service, Chicago, IL, 1974. Всемирный каталог познаний по компьютерам. Эта книга — увлекательный сборник. Она даже имеет два разных названия, в зависимости от того, откуда вы начнете читать ее — с начала или с конца. Нельсон считает, что Трак — предвестник будущих языков, и дает прекрасное введение в него. Стрейчи (Strachey С). A General Purpose Macrogenerator. Comput. J. 8, 3, pp. 225—241, 1966. В статье Муэрса Трак описывается с точки зрения его использования. Изложение проблем во многом повторяет предыдущую статью, но во встроенные функции внесены некоторые очевидные усовершенствования. Стрейчи в своей статье описывает очень похожий язык, в котором вместо встроенных функций имеются более мощные, чем в Траке, средства определения функций, и приводит листинг модельного процессора. Две эти статьи были написаны независимо и представляют собой яркий образец проявления исторической необходимости. Вегнер (Wegner P.). Programming Languages, Information Structures, and Machine Organization. McGraw-Hill, New York, NY, 1978. И Браун, и Вегнер с позиций общей информатики обсуждают Трак наряду с другими макропроцессорами.РЕШЕНИЯ
Ниже в качестве решений представлены законченные программы, однако это далеко не все, что должны сделать студенты. На примере конкретных задач мы обсуждаем искусство программирования, в частности некоторые полезные нюансы, о которых умалчивают многие руководства. Студентам необходимо представить больше внешней документации, больше выдач, больше подтверждений правильности программ. Заметим также, что мы не навязываем другим выбранные нами языки.29. Красьте с нами, или... ПОЛНОЕ РЕШЕНИЕ ЗАДАЧИ
В данной главе в полном виде приводится программа для задачи о раскраске карты (см. гл. 3). Читатели, которым довелось испытать это на собственной шкуре, знают как трудно описывать программу, излагая алгоритм прозрачно и просто. Когда решение головоломки рассказано, обычной реакцией бывает: «Как я не догадался!» вместо: «Как здорово!» Ну а программа — это, конечно, тоже решение головоломки. Из описаний всегда устраняют дух исследования, историю неудавшихся подходов и отступлений, упоминание о глупых ошибках, сбивавших с правильного пути. Если бы мы попытались полностью изложить процесс разработки программы, вы бы не знали, плакать вам или смеяться над тупостью автора. Так что лучше пойдем уже проторенной дорогой от задачи к решению, лишь изредка поглядывая по сторонам. [61] По условию задачи требуется раскрасить карту или неориентированный граф в минимальное число цветов так, чтобы никакие два соседних региона (никакие две смежные вершины) не были одного цвета. Хотя в данный момент не требуется точно специфицировать формат исходной и выводимой информации, а также внутреннее представление данных, можно сообразить, какие свойства графа будут существенны для любой программы. Очевидно, нужно знать число вершин графа, уметь регулярным образом обращаться к вершинам, уметь раскрашивать вершины и узнавать их цвет, определять, являются ли две вершины смежными, и, наконец, нужно уметь порождать много различных цветов. Проще всего удовлетворить перечисленным требованиям, обозначив вершины натуральными числами 1, 2, ..., n, где n — общее количество вершин. Аналогично и цвета обозначим натуральными числами (ясно, что при этом в нашем распоряжении окажется много цветов). Вопрос о конкретном способе определения смежности вершин целесообразно отложить. Раскрашивать можно двумя способами: либо предположить, что каждая вершина уже раскрашена в свой цвет и попытаться избавиться от нескольких цветов, либо предположить, что ни одна вершина еще не раскрашена, и пытаться добавлять как можно меньше цветов. Однако на любом пути мы сталкиваемся с неприятным теоретическим результатом (или с отсутствием оного): никто не знает, как раскрасить карту, не перебрав для худшего случая все возможные раскраски с минимальным числом цветов. Большинство специалистов считает, что нет более быстрого метода раскрашивания карты, чем перебор всех вариантов. Иными словами, какой бы умной ни была ваша программа и как бы быстро она ни работала в среднем, найдутся карты с n вершинами, требующие к цветов, на раскраску которых программа затратит порядка kn единиц времени. Возможно, кому-нибудь посчастливится найти алгоритм, и для худшего случая оказывавшийся не столь расточительным, но теоретики считают это маловероятным. Так что давайте займемся простой быстрой программой, а не суперсложной, которая вряд ли будет лучше.[62] Предлагаемое решение основано на наблюдении, что если некоторый подграф нельзя раскрасить в k цветов, то и весь граф, очевидно, тоже нельзя раскрасить в к цветов. На каждом шаге нашего алгоритма мы пытаемся добавить к уже раскрашенному подграфу еще одну вершину. Если сделать это не удастся, текущий раскрашенный подграф перекрашивается всеми возможными способами с использованием тех же цветов. Если новую вершину добавить все же нельзя, число цветов увеличивается на единицу» поскольку найден подграф, не раскрашиваемый выделенными цветами. В описании алгоритма предполагается, что есть вектор цвет, содержащий цвета, приписанные каждой вершине. Логическая функция связь позволяет узнать, связана ли вершина i с вершиной j.Алгоритм раскраски графа
1. (Начальная установка.) Предположим, что в графе имеется числовершин вершин, что переменная старшийцвет содержит номер старшего из уже использованных цветов, а нуль показывает, что вершина еще не наделена цветом. Для всех вершин n установить цвет[n] равным нулю (т. е. сделать все вершины нераскрашенными). Установить старшийцвет равным нулю, а переменную равной единице. 2. (Основной цикл.) Пока текущаявершина не превзойдет числовершин, выполнять шаги с 3-го по 7-й. Этим шагом начинается цикл, который повторяется, пока не будут раскрашены все вершины. Перед началом каждого прохождения цикла все вершины от 1 до текущаявершина — 1 правильно раскрашены в старшийцвет цветов. 3. (Подготовка одного узла.) Увеличить цвет[текущаявершина] на единицу. Установить булеву переменную флагцикла равной значению отношения цвет[текущаявершина] <= старшийцвет. Теперь рассматриваемая вершина имеет ненулевой цвет, и необходимо проверить, совместима ли текущаявершина со своими соседями. Заметьте, что впервые добавляемая вершина всегда имеет нулевой цвет. Прибавляя единицу к нулю, мы наделяем вершину допустимым цветом. Пока цикла имеет значение истина, выполнять шаги 4 и 5. 4. (Проверка цвета смежных вершин.) Присвоить переменной флагцикла значение ложь и установить i равным единице. Пока i меньше, чем текущаявершина, выполнять шаг 5. 5. (Проверка цвета каждого соседа.) Если вершина i и текущаявершина связаны (т. е. если связь(i, текущаявершина) имеет значение «истина») и если цвет[i] и цвет[текущаявершина] равны, значит, текущаявершина имеет недопустимый цвет. В этом случае установить значение i равным текущаявершина, чтобы прервать цикл, начинающийся в шаге 4, увеличить цвет[текущаявершина] на единицу чтобы попробовать следующий цвет, и установить значение флагцикла равным значению отношения цвет[текущаявершина] <= старшийцвет. В противном случае просто увеличить i на единицу, чтобы проверить следующего соседа. Заметьте, что последнее присваивание переменной флагцикла перекроет присваивание в шаге 4, но может установить переменную флагцикла равной значению ложь. Далее, если начинающийся в шаге 4 цикл завершается нормально (т. е. без насильственного присваивания переменной текущаявершина значения i), произойдет выход из цикла, начинающегося в шаге 3. Важно, чтобы при проверке допустимости раскраски использовались лишь вершины, номера которых строго меньше, чем текущаявершина, поскольку вершины с большими номерами еще не раскрашены. 6. (Продвинуться или вернуться?) Если текущаявершина получила допустимый цвет, мы хотим перейти к следующей вершине; в противном случае необходимо отступить. Поэтому, если цвет [текущаявершина] > старшийцвет, установить цвет [текущаявершина] равным нулю и уменьшить значение текущаявершина на единицу; в противном случае увеличить значение текущаявершина на единицу. Заметьте, что цвета вершин с номерами большими, чем текущаявершина, по-прежнему нулевые и что, когда мы возвращаемся к уже раскрашивавшейся вершине, мы продолжаем продвигать ее цвет со значения, оставшегося от предыдущей обработки. 7. (Добавление цвета, если это необходимо.) Если вершина нулевая, увеличить старшийцвет на единицу и установить значение текущаявершина равным единице. Если мы вернулись к самому началу, число цветов необходимо увеличить. Легко видеть, что данный алгоритм должен завершиться. В крайнем случае, он остановится, когда все вершины получат разные цвета. Также достаточно ясно, что перед началом каждого прохождения основного цикла все вершины от первой до (текущаявершина — 1) имеют допустимую раскраску. Чуть менее очевидно, что старшийцвет увеличивается только тогда, когда невозможно раскрасить некий начальный подграф выделенным числом цветов. Удостовериться в этом вам помогут эксперименты на небольших графах. Заметьте, что алгоритм правильно работает для пустого графа, для графов, все вершины которых изолированы, и для графов, все вершины которых связаны.Реализация
В нашей реализации мы используем Фортран. Ясно, что Фортран — очень бедный язык, с недостаточными возможностями определения данных и управления последовательностью действий. Однако мы выбрали его как раз для того, чтобы показать, что даже на неудобном языке можно написать хорошо структурированную, ясную программу. Теоретически каждую программу можно было бы написать на более новом, более выразительном языке; на практике большинству программистов время от времени приходится работать на архаичном языке, но плохие инструменты не могут служить оправданием для плохого программирования. Логическую функцию связь на Фортране можно представить двумерным логическим массивом, в котором (i,j)-й элемент имеет значение истина тогда и только тогда, когда вершина i связана с вершиной j. Первый элемент ввода — это запись с количеством вершин раскрашиваемого графа. Затем читаются наборы записей, где каждый набор описывает связи одной вершины. Первая запись набора содержит номер вершины и количество ее соседей; в оставшихся записях в произвольном порядке перечисляются соседи. Признаком конца исходных данных служит нулевой номер вершины. Вершины можно описывать в произвольном порядке, а описание одной вершины можно разбивать на несколько частей. Когда вершина i связывается с вершиной j, вершина j автоматически связывается с вершиной i. Единственными возможными ошибками являются выход номера вершины за допустимые границы и попытка связать вершину с ней самой. Ниже воспроизводится реальная программа.




 Исходные данные взяты с рис. 1 из гл. 3. Штаты перенумерованы сверху вниз; столбцы упорядочены слева направо. В каждой головной перфокарте справа присутствует название штата; вследствие заданного формата существенны только первые восемь литер карты. Для экономии места в книге данные разбиты на две колонки, но в остальном они точно соответствуют требованиям программы.
Исходные данные взяты с рис. 1 из гл. 3. Штаты перенумерованы сверху вниз; столбцы упорядочены слева направо. В каждой головной перфокарте справа присутствует название штата; вследствие заданного формата существенны только первые восемь литер карты. Для экономии места в книге данные разбиты на две колонки, но в остальном они точно соответствуют требованиям программы.

 Выдача выглядит наилучшим образом, если ее напечатать АЦПУ и повесить на стену. Пропорции приведенной в книге выдачи несколько нарушают симметрию. Заметьте, что горизонтальная печать решения экономит много бумаги, без всякой потери информации. Первоначально мы хотели напечатать номера и цвета вершин вертикально, что делается несколько проще, но выдача при этом получается весьма неряшливой. Реальная выдача приведена на предыдущей странице.
Выдача выглядит наилучшим образом, если ее напечатать АЦПУ и повесить на стену. Пропорции приведенной в книге выдачи несколько нарушают симметрию. Заметьте, что горизонтальная печать решения экономит много бумаги, без всякой потери информации. Первоначально мы хотели напечатать номера и цвета вершин вертикально, что делается несколько проще, но выдача при этом получается весьма неряшливой. Реальная выдача приведена на предыдущей странице.
Замечания по программе
Строки 1—19. Заголовок программы служит тем же целям, что и аннотация в научной статье. Вне зависимости от того, велика или мала программа, в ее начале должна присутствовать такого рода информация. В частности, в программе обязательна ссылка на соответствующую внешнюю документацию. Строки 22—26. Если бы программа была побольше, перед определением данных следовало бы поместить больше материала по алгоритмическим вопросам. В нашем же случае тексту программы предшествует полный словарь. Поскольку размеры модулей не должны превышать нескольких страниц, мы предпочли толковый словарь, в котором переменные упоминаются группами в соответствии со своей ролью, важностью и местом употребления. Очевидно, количество пояснений в словаре зависит от других комментариев, но ни одна переменная не должна быть выпущена. Мы пытались сделать шестилитерные имена мнемоничными, однако нелегко бороться против одного из глупейших фортрановских правил. Строки 62—89. Все переменные продекларированы, хотя в Фортране декларации не обязательны. Во-первых, лучше перестраховаться, а во-вторых, лучше увериться, что читающий программу точно знает наши намерения. Комментарии в строках 62—65 поясняют, почему мы отклоняемся от стандарта: к этому нас вынуждает компилятор; точно указаны изменения, которые могут потребоваться при выполнении программы на другой вычислительной установке. Во вводе/выводе использованы переменные номера каналов, так что если программа переносится на другую установку с другими соглашениями о номерах, для налаживания работы ввода/вывода потребуется только одно изменение. Строки 92—98. Начиная с этого места, перемежаются абзацы комментариев на естественном языке и абзацы инструкций на Фортране. Не давайте комментарии слишком часто, иначе будет трудно уследить за порядком выполнения программы. Разумеется, ничто не может оправдать недостаток комментариев. В нашей программе 145 строк комментариев и 157 строк с инструкциями на Фортране. По общему правилу комментарии пишутся перед соответствующими инструкциями. Строки 105—109. Помечать следует только инструкции CONTINUE и FORMAT. В Фортран-программе всегда много меток, и при отладке часто приходится перемещать их. Не накликайте беды, помечая самостоятельные инструкции, при перемещении которых легко ошибиться. По тем же причинам в одной строке закрывайте только один DO-цикл. Строки 110—115. Проверка исходных данных — одновременно одна из самых скучных и самых важных обязанностей программы. Не доверяйте ничьим данным, даже своим собственным. Обратите внимание на инверсию смысла логических проверок в условных инструкциях. Подобная инверсия — обычное для Фортрана дело. Трудно выработать твердую схему для ступенчатой записи условных инструкций (ввиду отсутствия else), но имеющиеся в программе примеры показывают возможные варианты. Строки 139-151. Метка 65 демонстрирует целесообразность расположения меток в порядке возрастания, с большим постоянным шагом. Проверка исходных данных, расположенная непосредственно перед меткой 65, добавлена после того, как при подготовке данных была допущена ошибка. Когда метки упорядочены, вставка дополнительных инструкций не вызывает затруднений. Обратите внимание также на использование переменной J. Она нужна потому, что стандартный Фортран не допускает употребления в индексных выражениях переменных с индексами. Только следуя всем, даже неприятным, правилам, можно гарантировать переносимость и правильность. Большинство компиляторовне требует временного использования J, но лучше быть готовым ко всему. Строки 155-162. Комментарии должны разъяснять, почему инструкция делает то, что она делает; как это делается, обычно видно из самой инструкции. Строки 196—211. Было бы излишним переписывать в программу из внешних документов весь алгоритм; читающего программу будут направлять к источникам соответствующие ссылки на литературу. Правда, для этого хорошую внешнюю документацию нужно иметь. О ней следует позаботиться до начала работы над программой. Строки 238—239. Стоящая особняком инструкция перехода может показаться несколько странной. Ее существование объясняется тем, что структура программы в точности повторяет структуру алгоритма. «Поборники эффективности» могут ворчать, что в строке 226 достаточно заменить GOTO 220 на GOTO 170, экономя две строки исходного текста и одну-две микросекунды на каждое прохождение цикла. Так-то оно так, но можно ли экономить за счет понятности? Сколько микросекунд машинного времени нужно сэкономить, чтобы окупить 5 мин времени программиста? Строки 277—301. Все форматы собраны в конце программы, чтобы не затемнять логику ее работы. Каждый класс инструкций ввода/вывода, каждый файл, канал, каждое обращение имеет свою последовательность меток. Эти последовательности не перемешиваются друг с другом и с обычными программными метками. Заметьте, что холлеритовы данные передаются посредством старомодных форматов nН, поскольку по стандарту Фортрана эти глупые счетчики необходимы, хотя большинство компиляторов их не требует.Заключительные замечания
На этом заканчивается обсуждение раскрашивания карт. Укажем, что на первоначальную разработку алгоритма ушло около 5 часов, написание программы заняло около 8 часов, ввод ее текста в системе с разделением времени занял около 3 часов, а тестирование и отладка потребовали около 2 часов. Большая часть тестового времени ушла на проверку соответствия между вводом и выводом. Две ошибки при вводе текста и две неправильно расположенные метки обнаружились либо компилятором, либо по нелепой первой выдаче. Дополнительная проверка ввода придумана во время подготовки тестовых данных. Алгоритм содержал один логический дефект, и его удалось вскрыть посредством первого же реального множества данных. Эта задача иллюстрирует также важность документирования для будущей работы. Приведенный здесь алгоритм на самом деле разработан примерно за 6 месяцев до написания главы. Была формально доказана его правильность. Группа программистов, видевших и алгоритм, и доказательство, единодушно признали их совершенно безукоризненными. Но пока автор собирался сесть писать главу, какие-то жулики украли единственную копию алгоритма и доказательства (хотя трудно себе представить, для чего им эти бумаги). Пришлось потратить еще около 5 часов на восстановление первоначального хода мыслей; при этом снова была допущена логическая ошибка. Пусть же поразят компьютер этих жуликов вечные ошибки четности!Литература
Кнут (Knuth D. E.). Estimating the Efficiency of Backtrack Programs. Mathematics of Computation, 29, 129, pp. 121—136, 1976. Хотя для наихудшего случая время работы алгоритма раскраски карт экспоненциально зависит от размера исходного графа, среднее время обычно весьма невелико. Однако аналитический вывод среднего значения, видимо, превышает наши возможности. Кнут описывает метод для оценки скорости работы программ, действующих по методу перебора с возвратами. Оценка дается вручную после просчета некоторых тестовых случаев. Кнут приводит примеры, иллюстрирующие его метод. Эппл, Хейкен (Appel К., Haken W.). Every Planar Map is Four Colorable. Bulletin of the American Mathematical Society, 82, 5, pp. 711—712, September 1976. Стин (Steen L. A.). Solution of the Four Color Problems. Mathematics Magazine, 49, 4, pp. 219—272, September 1976. Иссяк еще один источник диссертаций. Эппл и Хейкен объявили о доказательстве истинности гипотезы о четырех красках. В момент написания данной главы доказательство циркулировало в рукописном виде, и несколько видных специалистов по комбинаторике считали, что, по-видимому, оно верно. К моменту выхода в свет нашей книги доказательство наверняка появится в математических журналах. Стин описывает метод доказательства и его значение для математики. ЭВМ интенсивно использовалась для разработки доказательства и для проверки 1936 случаев в окончательном варианте доказательства. *Яглом И. М. Четырех красок достаточно. «Природа», 1977, № 6, с. 20—25. *Ахо А., Хопкрофт Дж., Ульман Дж. Построение и анализ вычислительных алгоритмов. Пер. с англ. — М.: Мир, 1979. Это как раз та книга, с которой программисту полезно советоваться в трудных случаях. На стр. 449 содержится ссылка на статью с подробным обсуждением теоремы о четырех красках. *Н. Вирт. Систематическое программирование. Введение. Пер. с англ. — М.: Мир, 1977. На наш взгляд было бы интересно испытать разные эвристики. Из п. 15 4 книги Н. Вирта читатель увидит, как можно механически получать программы, работающие по голой схеме перебора с возвратами. * Партия переводчика. В 1978 г. был утвержден новый американский стандарт языка Фортран. Описываемый в нем язык получил название Фортран-77 (см. Катцан Г. Язык Фортран-77. Пер. с англ.— М.: Мир, 1982). Ознакомившись с приводимой ниже программой, читатель, разумеется, легко заметит новые возможности Фортрана. Поскольку программа получена прямолинейным переписыванием авторского варианта, трактовка новых возможностей не вызовет затруднений. По той же причине отсутствуют комментарии. Лишь два момента вызвали небольшие заминки при переписывании программы. Во-первых, в строке 141, видимо, допущена опечатка и вместо OR следует читать AND. Во-вторых, инструкции 232 и 237 GOTO 190 выполняют сразу две функции: завершают условную инструкцию и передают управление на начало цикла. Любопытно сопоставить их с инструкцией 239 GOTO 170, которой автор уделил немало внимания. Небезынтересно также сопоставить авторские замечания с новым вариантом программы (см. с. 254—256).


30. Сжатые строки, или... ПРОГРАММА УПЛОТНЕНИЯ ТЕКСТОВ
В гл.11 был рассмотрен полезный алгоритм, предназначенный для сжатия текстовой информации. И работай вы программистом, скажем в библиотеке или в газете, то были бы вправе ожидать, что шеф выложит вам на стол одиннадцатую главу и предложит попытаться подключить описанный в ней алгоритм к уже работающей системе. А поскольку кажется вполне правдоподобным, что этот алгоритм мог бы обеспечить значительную экономию памяти, то и задача выглядит на первый взгляд привлекательной. Сомнения приходят позже. • Насколько сложны алгоритмы, необходимые для выполнения сравнений в словаре, какова сложность структур данных? • Как долго придется со всем этим возиться? • Работа алгоритма определяется наборами параметров. Как эти параметры выбрать? • В какой степени коэффициент сжатия зависит от вариаций в уплотняемом тексте? • Ради экономии памяти расходуется процессорное время. Когда можно считать, что овчинка стоит выделки? • Вообразим, что в первой версии программы все уже ясно и она работает правильно, хотя и не очень эффективно. Какие переделки позволят поднять ее производительность? • Можно ли в исходном проекте предусмотреть возможность внесения изменений и дополнений без больших переделок? • И наконец, сколько времени стоит потратить на эту задачу, чтобы считать, что она выполнена достаточно хорошо? Примерно те же вопросы должны возникнуть и у начальника, да еще наряду с сомнениями, тот ли вы программист, который осилит поставленную задачу. Тем не менее, нельзя допустить, чтобы сомнения вас парализовали. Энергично беритесь за дело, невзирая на отдельные трудности (но и не забывая о них) и сконцентрируйте все свои усилия на тех вопросах, которые кажутся легко разрешимыми. В данной работе мы в свою очередь испробуем, прежде всего, программу, использующую простые структуры данных и алгоритмы. А после того, как программа заработает правильно, постараемся ее улучшить, внося различные усовершенствования. Вполне может так случиться, что свойства программы будут зависеть от неких параметров, поэтому постараемся сделать так, чтобы их можно было легко менять; в первом варианте программы, однако, мы будем просто пробовать возможные значения. Для того чтобы исследовать, как влияют на результаты вносимые в программу изменения, исходная информация или параметры программы, мы будем разрабатывать ее как автономную, не являющуюся частью какой-либо большей системы,— и тогда эффективность интересующей нас программы не будет скрыта за накладными расходами ее окружения. На практике, разумеется, сжатие текстов, как правило, только часть некоторой большей задачи, предполагающей наличие значительных массивов текста. А положит конец нашей работе отнюдь не снижающаяся результативность, а усталость и скука.Как заточить карандаш
У каждого писателя своя манера подготовки к работе. Некоторым надо протрезветь, а кое-кому выпить, одни встают в 4 утра, другие поднимаются на ночь; некоторым необходима тишина, а другим требуется шумная веселая обстановка, а есть и такие, которые обходятся остроотточенным карандашом и традиционным блокнотом. Программисты — те же писатели, и им требуется найти удобный для себя распорядок и уютную окружающую обстановку. Прежде чем приступить к решению задачи о сжатии текста, хотелось бы предложить несколько рецептов, как сделать процесс программирования более приятным и плодотворным. Нас такая методика вполне устраивает, и вы уж по крайней мере испробуйте ее, прежде чем вернетесь к своей собственной. Программы должны быть читабельными, а это достигается, прежде всего, их единообразием и согласованностью. Такие качества обусловливают общепризнанный стиль программирования, когда повторяющиеся действия записываются по возможности сходными конструкциями. Чтобы повысить единообразие в программах, старайтесь программировать всегда в одной и той же окружающей обстановке. Почти все наши программы, в том числе большая часть приведенных в книге, написаны в старом садовом кресле-качалке, к которому из листов фанеры и пластмассы была на скорую руку прилажена доска для письма. Это сооружение располагается в жилой комнате, где легко включить стереозапись классической музыки и где всегда под рукой охлажденный чай в холодильнике. То, что нельзя начинать программировать, если в доме гости, — это, конечно, совершенно справедливо. И все же дома настолько спокойнее, чем в любом учреждении, что дел делается во много раз больше. Может быть, вы предпочтете какие-нибудь другие условия. Не оставляйте поисков, пока не найдете для себя действительно удобной обстановки, а потом поймите, каким образом ее воспроизвести всякий раз, когда программируете. Многие программисты работают так: набросают на обороте старого конверта несколько строк программы и мчатся к терминалу, чтобы поскорее их набрать и пропустить. А все остальное время занимаются тем, что вставляют в программу там и сям заплатки, и конечный результат их труда смотрится так, словно ужасный доктор Франкенштейн впопыхах прооперировал Шалтая-Болтая. На самом деле, немаловажный вклад в повышение читабельности вносит самодисциплина, одним из способов воспитания которой служат бланки для записи программ. Свободные художники, о которых упоминалось выше, часто с пренебрежением взирают на программистов, которые работают, заполняя клеточки на бланках, и, тем не менее, бланки оказывают сильное стабилизирующее влияние на манеру работы и во много раз облегчают разработку и использование метода ступенчатой записи программ. Кроме того, программу, написанную на бланках, можно отдать на перфорацию. Причем, как ни приятно освободиться от нудной работы, намного важнее, что девушки из перфораторной прочитают программу и проверят правильность пробивки. Поэтому многие описки никогда не попадут в машину, да и лишний глаз — вовсе не помеха. Теперь о борьбе с предрассудком. Старайтесь писать свои программы чернилами. Большинство институтских преподавателей программирования будет говорить, что не надо бояться допустить ошибку в программе (это-то достаточно справедливо) и что ластик может стать вашим самым мощным инструментом. К несчастью, ластик может оказаться чересчур мощным. Ведь коль скоро ошибки так просто исправить, значит, пока не совершишь очередную, можно особенно тщательно и не думать. В том же случае, когда вы пишете чернилами, ошибки обходятся дороже, в особенности из-за того, что измазанный переправленный бланк могут однажды на пробивку не принять. Из-за никчемных ошибок придется переписывать целую страницу. Неудача вынудит вас писать медленнее и глубже задумываться над каждой строкой; время, потраченное на написание, окупится при тестировании и отладке программы. Даже если у вас есть редактор текстов, который поощряет или навязывает правильный стиль программирования, все равно следует испробовать эти последние две рекомендации. Запись программы необходимо тщательно продумывать, а опыт показывает, что от электрических полей, окружающих терминалы компьютера, в наших мыслях нередко возникают короткие замыкания. Вместо того чтобы пользоваться блок-схемой, старайтесь сначала писать комментарии. Всякий раз, когда начинаете новую программу, пишите длинные комментарии, в которых как можно подробнее описывайте назначение программы и ее организацию. Относитесь к составлению комментариев как к важнейшей программистской задаче. После того как комментарии написаны, положите их перед собой и, пользуясь написанным как справочником, протранслируйте их вручную на используемый вами язык программирования. И если язык не очень нудный, как, например, язык ассемблера, то перевод не должен быть существенно длиннее комментариев, а может оказаться даже короче. Благодаря тому что комментарии написаны на отдельных листах (предположительно бланках), их можно рассматривать как документацию, которую нет надобности переписывать только из-за того, что транслируемая программа оказалась неверной. Конечно, если у вас изменятся замыслы в отношении программы, может быть, и потребуется переписать как комментарии, так и сам код. Ни одну программу не приводите к виду, пригодному для ввода в машину, до тех пор, пока не напишете ее полностью. Однако, как только закончите, пропустите, не откладывая, через машину и устраните все описки, все неправильно написанные идентификаторы, поставленные не на место точки с запятой и т. д. Ваша цель — получить чистый листинг, лучше бы с полной таблицей перекрестных ссылок. Такой «чистый» листинг не свободен, конечно, от ошибок — просто он не содержит совсем уж глупых, которые в состоянии обнаружить транслятор. Теперь садитесь за программу и пройдитесь по ней так, словно кто-то другой пытается вам ее продать. Проверьте каждую инструкцию, прокрутите каждый цикл, ищите неиспользуемые или употребляемые неверно переменные, старайтесь упростить структуру управления, подправляйте даже знаки препинания в комментариях. Причиной того, почему все это делается на листинге, а не на бланках, является тот факт, что многие ошибки отчетливее проявляются на фоне аккуратно отпечатанной программы. Именно в это время уже пора привести в порядок внешний вид программы, чтобы она стала как можно более наглядной. Если в листинге набралось уже столько правок, что за ними не видно саму программу, внесите все исправления, отпечатайте новый листинг и продолжайте дальше. Не жалейте бумагу — пропущенная ошибка вам может обойтись куда дороже. Эти предложения годятся, очевидно, не для любых программ и не во всех случаях. Многие системы программирования снабжены целым арсеналом средств, помогающих в процессе разработки программ. Пренебрегать этими возможностями было бы глупо и расточительно. Они особенно полезны при создании программ одноразового использования и для контроля хода работ в больших проектах. Однако мы не можем не предостеречь вас самым серьезным образом: машина не должна мешать вам принимать решения. Чарующая песня компьютера «Доверься мне — я все решу» соблазнила многих программистов и привела к крушению их замыслов.Анализ вопроса
Поскольку оба основных алгоритма (построение словаря и кодирование текста) уже разработаны, нам необходимо рассмотреть теперь, какими вспомогательными программами их надо снабдить. Прежде всего, отметим, что в обоих алгоритмах введенный текст просматривается слева направо и при сравнениях его на совпадение со словарем важны лишь несколько ближайших рядом стоящих литер. Это значит, что как для построения словаря, так и для кодирования можно применить одну и ту же программу ввода и что нам не следует заботиться о деталях доступа к входному потоку, поскольку программа ввода всегда выдает литеры для проведения сравнений или признак конца файла. Во-вторых, в обоих алгоритмах требуется поиск цепочки в словаре, но ни один из алгоритмов не должен зависеть от метода поиска. Поэтому и здесь алгоритмы могут быть снабжены общей обслуживающей программой, и по-прежнему нет необходимости уточнять детали. В-третьих, алгоритму кодирования потребуется хотя бы одна литера, нигде во вводимом тексте не используемая и выступающая в качестве управляющего кодирующего знака. Вместо того чтобы выбрать некую литеру до прочтения текста, можно в программе ввода отслеживать все поступающие на вход литеры и для кодирования употребить любую не встретившуюся. Процедура построения словаря, написанная на XPL, показана на рис. 30.1 [63] Здесь уместно кое-что пояснить. Процедура написана на XPL — языке, в достаточной степени похожем как на Паскаль, так и на PL/I, так что его легко понять (подтверждение того факта, что разобраться в специализированном языке, как правило, весьма несложно). Применительно к нашей задаче XPL обладает рядом достоинств, в том числе наличием в языке цепочек в качестве встроенного типа данных и удобных управляющих структур. Недостаток языка заключен, в частности, в том, что единственным видом структурированных данных являются одномерные статические массивы.
Язык содержит и редко встречающиеся средства— оператор конкатенации цепочек || и функцию SUBSTR, употребляемую для выделения из имеющейся цепочки подцепочки.[64] Программа ввода FILL.INPUT.BUFFER (заполнение входного буфера) загружает входной буфер, если он оказывается пустым, и выдает пустую цепочку в случае, когда вводимый файл исчерпан. Если вводить больше нечего, происходит выход из программы BUILD.DICTIONARY (построение словаря). Заметим, что сравнить длину цепочки с нулем и проверять, не пустая ли она,— это одно и то же, но в данном случае первое предпочтительнее, поскольку в XPL операция LENGTH весьма эффективна. Посмотрите теперь как выглядит процедура ввода (рис. 30.2).
Здесь уместно кое-что пояснить. Процедура написана на XPL — языке, в достаточной степени похожем как на Паскаль, так и на PL/I, так что его легко понять (подтверждение того факта, что разобраться в специализированном языке, как правило, весьма несложно). Применительно к нашей задаче XPL обладает рядом достоинств, в том числе наличием в языке цепочек в качестве встроенного типа данных и удобных управляющих структур. Недостаток языка заключен, в частности, в том, что единственным видом структурированных данных являются одномерные статические массивы.
Язык содержит и редко встречающиеся средства— оператор конкатенации цепочек || и функцию SUBSTR, употребляемую для выделения из имеющейся цепочки подцепочки.[64] Программа ввода FILL.INPUT.BUFFER (заполнение входного буфера) загружает входной буфер, если он оказывается пустым, и выдает пустую цепочку в случае, когда вводимый файл исчерпан. Если вводить больше нечего, происходит выход из программы BUILD.DICTIONARY (построение словаря). Заметим, что сравнить длину цепочки с нулем и проверять, не пустая ли она,— это одно и то же, но в данном случае первое предпочтительнее, поскольку в XPL операция LENGTH весьма эффективна. Посмотрите теперь как выглядит процедура ввода (рис. 30.2).
 Программы ввода и вывода используют встроенные функции и всегда читают или печатают цепочки. На самом же деле PRINT (печать) является макрокомандой, внутри которой и скрыта работа вывода. Программа FILL.INPUT.BUFFER при необходимости распечатывает буфер ввода и, кроме того, регистрирует данные о каждой встретившейся литере. Функция BYTE при использовании ее в выражении преобразует выбранную из цепочки литеру в целое число таким образом, чтобы можно было ее использовать в арифметических операциях. В нашем случае литеры употребляются для индексирования логического вектора CHARACTERISED (встречаемость литер), в котором регистрируются все встретившиеся литеры. Кроме того, BYTE употребляется в BUILD.ENCODING.TABLE (формирование таблицы кодировок) для обратного превращения целых чисел в литеры; таким образом, BYTE выполняет те же функции, что и ORD и CHAR в Паскале.
В качестве структуры хранения информации в словаре выберем сначала простую неупорядоченную таблицу, в которой будет осуществляться линейный поиск. Такую структуру можно будет запросто отладить, хотя она, по-видимому, окажется мучительно неэффективна. Но как только у нас все заработает, можно попытаться ускорить поиск. В каждом гнезде словаря будут четыре поля: цепочка литер, частота гнезда во время построения словаря, кодировка, присвоенная этой цепочке, и счетчик обращений к ней при сжатии текста. Эти поля запоминаются в соответствующих четырех массивах, описанных в строках 66—73 главной программы (вот тут-то начинает давать о себе знать ограниченность структур данных в XPL). Первое полноценное гнездо всегда имеет номер 0, а последнее — DICTIONARY.TOP (вершина словаря). Максимальный размер словаря задает макро DICTIONARY.SIZE (размер словаря). При поиске требуется лишь полный просмотр всех гнезд словаря; новые гнезда могут добавляться в конец таблицы. При исключении низкочастотных гнезд на их место переписываются высокочастотные гнезда; читателю надлежит убедиться самому, что при работе цикла, описанного в строках 261—270, информация не теряется. Ниже программа приведена полностью, причем программы работы со словарем описаны в строках 195—296. Обратите внимание, что вычисление параметров, влияющих на степень сжатия, разнесено по самостоятельным подпрограммам, приведенным в строках 154—193, что позволяет с легкостью их отыскать и заменить. Мы предпочли здесь удобство в ущерб эффективности: в окончательной рабочей версии желательно исключить подпрограммы вычисления параметров, а требуемые функции переписать прямо в тех местах, где они должны использоваться.
Программы ввода и вывода используют встроенные функции и всегда читают или печатают цепочки. На самом же деле PRINT (печать) является макрокомандой, внутри которой и скрыта работа вывода. Программа FILL.INPUT.BUFFER при необходимости распечатывает буфер ввода и, кроме того, регистрирует данные о каждой встретившейся литере. Функция BYTE при использовании ее в выражении преобразует выбранную из цепочки литеру в целое число таким образом, чтобы можно было ее использовать в арифметических операциях. В нашем случае литеры употребляются для индексирования логического вектора CHARACTERISED (встречаемость литер), в котором регистрируются все встретившиеся литеры. Кроме того, BYTE употребляется в BUILD.ENCODING.TABLE (формирование таблицы кодировок) для обратного превращения целых чисел в литеры; таким образом, BYTE выполняет те же функции, что и ORD и CHAR в Паскале.
В качестве структуры хранения информации в словаре выберем сначала простую неупорядоченную таблицу, в которой будет осуществляться линейный поиск. Такую структуру можно будет запросто отладить, хотя она, по-видимому, окажется мучительно неэффективна. Но как только у нас все заработает, можно попытаться ускорить поиск. В каждом гнезде словаря будут четыре поля: цепочка литер, частота гнезда во время построения словаря, кодировка, присвоенная этой цепочке, и счетчик обращений к ней при сжатии текста. Эти поля запоминаются в соответствующих четырех массивах, описанных в строках 66—73 главной программы (вот тут-то начинает давать о себе знать ограниченность структур данных в XPL). Первое полноценное гнездо всегда имеет номер 0, а последнее — DICTIONARY.TOP (вершина словаря). Максимальный размер словаря задает макро DICTIONARY.SIZE (размер словаря). При поиске требуется лишь полный просмотр всех гнезд словаря; новые гнезда могут добавляться в конец таблицы. При исключении низкочастотных гнезд на их место переписываются высокочастотные гнезда; читателю надлежит убедиться самому, что при работе цикла, описанного в строках 261—270, информация не теряется. Ниже программа приведена полностью, причем программы работы со словарем описаны в строках 195—296. Обратите внимание, что вычисление параметров, влияющих на степень сжатия, разнесено по самостоятельным подпрограммам, приведенным в строках 154—193, что позволяет с легкостью их отыскать и заменить. Мы предпочли здесь удобство в ущерб эффективности: в окончательной рабочей версии желательно исключить подпрограммы вычисления параметров, а требуемые функции переписать прямо в тех местах, где они должны использоваться.











Результаты
Программа была пропущена, а в качестве исходных данных было использовано ее собственное короткое предисловие. Результаты отпечатаны ниже и снабжены номерами строк, чтобы было легче на них ссылаться. В строках 67—71 показана таблица кодировок. При таком коротком текстовом файле нет ничего удивительного, что словарь получился маленьким. Сжатие составляет лишь 0.973 отчасти из-за того, что строки текста в основных комментариях не раздуты за счет тех самых пробелов, которые столь милы сердцу большинства программ сжатия. Тем не менее, имеются некоторые любопытные моменты, о чем свидетельствует строка 62. Обратите внимание, что сжатия «D F» не произошло, поскольку другое сжатие слопало «D» еще раньше. То, что получилось, помещено на следующей странице.О предпринятых усовершенствованиях
Как предрекалось выше, линейный поиск в словаре не очень-то эффективен. Когда текст всей исходной программы был взят в качестве исходных данных, для его сжатия на машине со средним быстродействием потребовалось 127 с, что страшно долго для файла в 500 строк. Таблица 30.1. Сравнение двух алгоритмов организации словаря
Таблица 30.1. Сравнение двух алгоритмов организации словаря
 Заметьте, что, для того чтобы гарантировать при поиске в словаре отыскание самой длинной из цепочек, совпадающих с началом текста на входе, необходимо просмотреть все гнезда словаря. А вот если гнезда словаря расположить в порядке от самых длинных к самым коротким, поиск можно было бы прекратить при первом же удачном сравнении, ибо волей-неволей найденная цепочка была бы самой длинной из всех возможных. Причем процедуру поиска можно было бы не менять, и выбрасывание низкочастотных гнезд не нарушило бы порядок следования цепочек — от длинных к коротким. Однако при заведении нового гнезда необходимо все более короткие цепочки сдвинуть в таблице на одну позицию вниз. Чтобы определить, где производить вставку, мы ввели массив LENGTH.VECTOR (массив длин), i-я компонента которого указывает на гнездо словаря, в котором начинаются цепочки длиной i литер (если таковые есть) или короче (если нет ни одной цепочки длиной i). В случае если цепочки длиной i литер или меньше отсутствуют, значение LENGTH.VECTOR(I) равно значению DICTIONARY.TOP + 1. Программы, приведенные на с. 278—280, обеспечивают правильное хранение новой структуры данных. Чтобы создать новую версию программы сжатия, в соответствующие места нашей программы помещаются вставки, которые приведены ниже. Отметим, что для облегчения этого процесса массив вставок снабжен необходимыми комментариями.
Заметьте, что, для того чтобы гарантировать при поиске в словаре отыскание самой длинной из цепочек, совпадающих с началом текста на входе, необходимо просмотреть все гнезда словаря. А вот если гнезда словаря расположить в порядке от самых длинных к самым коротким, поиск можно было бы прекратить при первом же удачном сравнении, ибо волей-неволей найденная цепочка была бы самой длинной из всех возможных. Причем процедуру поиска можно было бы не менять, и выбрасывание низкочастотных гнезд не нарушило бы порядок следования цепочек — от длинных к коротким. Однако при заведении нового гнезда необходимо все более короткие цепочки сдвинуть в таблице на одну позицию вниз. Чтобы определить, где производить вставку, мы ввели массив LENGTH.VECTOR (массив длин), i-я компонента которого указывает на гнездо словаря, в котором начинаются цепочки длиной i литер (если таковые есть) или короче (если нет ни одной цепочки длиной i). В случае если цепочки длиной i литер или меньше отсутствуют, значение LENGTH.VECTOR(I) равно значению DICTIONARY.TOP + 1. Программы, приведенные на с. 278—280, обеспечивают правильное хранение новой структуры данных. Чтобы создать новую версию программы сжатия, в соответствующие места нашей программы помещаются вставки, которые приведены ниже. Отметим, что для облегчения этого процесса массив вставок снабжен необходимыми комментариями.


 Можно рассчитывать, что при использовании поиска до первого совпадения во время построения словаря сравнений будет меньше, а более сложная процедура добавления новых гнезд может занять при этом большее время. Тем не менее, из табл. 30.1 видно, что, несмотря на меньшее число сравнений при поиске в упорядоченном словаре, как время построения словаря, так и время кодирования текста увеличивается. Следует, однако, отметить, что для сравнений в первоначальной программе можно обойтись лишь дешевыми проверками длин цепочек, в то время как при поиске в упорядоченном словаре все сравнения требуют дорогих операций сопоставления цепочек. Чтобы повысить эффективность программы, надо бы, конечно, что-то предпринять. Но с другой стороны, проведенная переделка программы иллюстрирует важный принцип отладки. Если структура программы заменяется на функционально эквивалентную, то результаты при тех же исходных данных должны оставаться неизменными. На фактический процесс сжатия организация словаря влиять не должна, только параметры сжатия должны сказываться на содержании словаря. Следовательно, убеждаясь, что результаты работы программы с простым линейным поиском и с поиском до первого совпадения совершенно одинаковы (за исключением временной статистики), мы проверяем правильность изменений в подпрограммах, оперирующих со словарем. Это является также контролем на отсутствие ошибок в других частях программы: если бы в какой-нибудь другой подпрограмме был ляпсус, то он вполне мог бы проявиться в программах работы со словарем. А если уж результаты остаются постоянными после того, как подключается правильная программа поиска до первого совпадения, не исключено (но вовсе и не обязательно), что скрытых ошибок, влияющих на словарь, нет.
Можно рассчитывать, что при использовании поиска до первого совпадения во время построения словаря сравнений будет меньше, а более сложная процедура добавления новых гнезд может занять при этом большее время. Тем не менее, из табл. 30.1 видно, что, несмотря на меньшее число сравнений при поиске в упорядоченном словаре, как время построения словаря, так и время кодирования текста увеличивается. Следует, однако, отметить, что для сравнений в первоначальной программе можно обойтись лишь дешевыми проверками длин цепочек, в то время как при поиске в упорядоченном словаре все сравнения требуют дорогих операций сопоставления цепочек. Чтобы повысить эффективность программы, надо бы, конечно, что-то предпринять. Но с другой стороны, проведенная переделка программы иллюстрирует важный принцип отладки. Если структура программы заменяется на функционально эквивалентную, то результаты при тех же исходных данных должны оставаться неизменными. На фактический процесс сжатия организация словаря влиять не должна, только параметры сжатия должны сказываться на содержании словаря. Следовательно, убеждаясь, что результаты работы программы с простым линейным поиском и с поиском до первого совпадения совершенно одинаковы (за исключением временной статистики), мы проверяем правильность изменений в подпрограммах, оперирующих со словарем. Это является также контролем на отсутствие ошибок в других частях программы: если бы в какой-нибудь другой подпрограмме был ляпсус, то он вполне мог бы проявиться в программах работы со словарем. А если уж результаты остаются постоянными после того, как подключается правильная программа поиска до первого совпадения, не исключено (но вовсе и не обязательно), что скрытых ошибок, влияющих на словарь, нет.
Выбор параметров
Конструированием словаря управляют четыре параметра: размер словаря, порог укрупнения гнезд, начальное значение счетчика укрупненных гнезд и порог исключения гнезд. Выбор, который мы сделали, может показаться несколько странным. Размер словаря определяет макро DICTIONARY.SIZE и задается в нашем случае равным 100 (не забудьте, что массивы в XPL начинаются с нулевого индекса), а начальное значение счетчика в гнезде — посредством функции FIRST.COUNT. (начальный счетчик)— устанавливается равным единице. Укрупнение гнезд производится в случае, когда каждое из них имеет частоту не меньше, чем DICTIONARY.SIZE/(DICTIONARY.SIZE — DICTIONARY.TOP + 1) + 1, т. е. когда частоты обоих гнезд больше величины, обратно пропорциональной свободному пространству словаря. При этом мы исходили из представления (которое не слишком-то хорошо себя оправдало), что, когда словарь почти заполнен, записать новое гнездо должно быть труднее. Исходя из вида приведенного выражения, мы называем порог укрупнения гнезд завышенным порогом укрупнения. Исключение гнезд осуществляется в случае, если их частоты по крайней мере не больше средней частоты,— предполагается, что она является приближенным значением медианы. Чтобы установить, в какой степени такой выбор параметров действительно необоснован, изменим каждый из них, кроме размера словаря, и положим их значение равным пяти. Таблица 30.2. Небольшое исследование влияния параметров В табл. 30.2 отражены результаты обработки обоих файлов. Из таблицы видно, что как порог укрупнения, так и порог исключения оказались неудачными. Вполне возможно, что завышенный порог укрупнения не позволяет объединить и поместить в таблицу достаточное число укрупненных гнезд и, кроме того, быть может, средняя частота, взятая в качестве порога исключения, является плохим приближением медианы, что приводит к ликвидации слишком большого числа гнезд. Все это — лишь очень поверхностное исследование, и надо бы собрать еще дополнительный материал. Однако нас заест тоска раньше, чем программа станет более эффективной.
Заключительные замечания
Должно быть, эта глава совершенно не похожа на проект, выполненный на пять с плюсом. Над самой программой можно бы было потрудиться и побольше, особенно над комментариями. Немало среди них путаных и бесполезных. В результате напечатанная программа еще на полпути к завершению, и вы можете полюбоваться, на что похожи ваши собственные недоделанные программы. Вернитесь назад и еще раз разберите программу, задаваясь при этом мысленным вопросом: «А как бы можно было вылизать данную строку (комментарий, процедуру), чтобы достичь кристальной ясности?» И после того, как вы, ехидничая по поводу чужих способностей, закончите, посмотрите, положа руку на сердце, нельзя ли ваши рекомендации применить к вашим собственным программам. Желательно, чтобы законченный проект включал в себя также наглядное доказательство правильности алгоритмов, дополнительную печать и хотя бы несколько рекомендаций по повышению эффективности словаря. Составление программы заняло около восьми часов, а отладка — около четырех. Причем из четырех часов отладки два ушло на устранение обычных описок и на наведение красоты печати. Остальные два часа отладки были посвящены тому, чтобы добавить «+1» в 91-ю строку измененного файла. Одна эта маленькая коварная ошибка вызвала массу трудностей и полностью нарушила режим работы программы поиска в упорядоченном словаре. В конце концов, ошибка была обнаружена после того, как мы объяснили всю программу другому программисту. Придерживаясь принципа беспристрастности, он не разделял нашего превратного толкования программы и моментально обнаружил «ляп». Кроме того, около часа было затрачено на вставку и отладку временных переменных (средства подсчета времени в эксплуатирующейся у нас системе развиты в недостаточной степени) и порядка четырех часов на жонглирование параметрами.
В табл. 30.2 отражены результаты обработки обоих файлов. Из таблицы видно, что как порог укрупнения, так и порог исключения оказались неудачными. Вполне возможно, что завышенный порог укрупнения не позволяет объединить и поместить в таблицу достаточное число укрупненных гнезд и, кроме того, быть может, средняя частота, взятая в качестве порога исключения, является плохим приближением медианы, что приводит к ликвидации слишком большого числа гнезд. Все это — лишь очень поверхностное исследование, и надо бы собрать еще дополнительный материал. Однако нас заест тоска раньше, чем программа станет более эффективной.
Заключительные замечания
Должно быть, эта глава совершенно не похожа на проект, выполненный на пять с плюсом. Над самой программой можно бы было потрудиться и побольше, особенно над комментариями. Немало среди них путаных и бесполезных. В результате напечатанная программа еще на полпути к завершению, и вы можете полюбоваться, на что похожи ваши собственные недоделанные программы. Вернитесь назад и еще раз разберите программу, задаваясь при этом мысленным вопросом: «А как бы можно было вылизать данную строку (комментарий, процедуру), чтобы достичь кристальной ясности?» И после того, как вы, ехидничая по поводу чужих способностей, закончите, посмотрите, положа руку на сердце, нельзя ли ваши рекомендации применить к вашим собственным программам. Желательно, чтобы законченный проект включал в себя также наглядное доказательство правильности алгоритмов, дополнительную печать и хотя бы несколько рекомендаций по повышению эффективности словаря. Составление программы заняло около восьми часов, а отладка — около четырех. Причем из четырех часов отладки два ушло на устранение обычных описок и на наведение красоты печати. Остальные два часа отладки были посвящены тому, чтобы добавить «+1» в 91-ю строку измененного файла. Одна эта маленькая коварная ошибка вызвала массу трудностей и полностью нарушила режим работы программы поиска в упорядоченном словаре. В конце концов, ошибка была обнаружена после того, как мы объяснили всю программу другому программисту. Придерживаясь принципа беспристрастности, он не разделял нашего превратного толкования программы и моментально обнаружил «ляп». Кроме того, около часа было затрачено на вставку и отладку временных переменных (средства подсчета времени в эксплуатирующейся у нас системе развиты в недостаточной степени) и порядка четырех часов на жонглирование параметрами.
Примечания
1
Семь лет — традиционный срок ученичества в средневековых ремесленных мастерских Англии. — Прим. перев. (обратно)2
Чиппендейл (Chippendale) Томас (1718–1779) — английский мебельный мастер. Сочетал функциональную целесообразность форм с изяществом линий. — Прим. перев. (обратно)3
Мы называем нашего читателя «студентом». Это, однако, не должно отпугнуть тех, кто не учится в соответствующем учебном заведении. Научиться программировать можно и в одиночку; желая вдохновить тех, кто вынужден осваивать предмет самостоятельно, мы предлагаем им для решения набор задач, достаточно близких к реальным. Учтите, однако, что осваивать предмет под руководством преподавателя все же неизмеримо легче. (обратно)4
Предлагаются такие общедоступные языки, как Фортран, Кобол, Алгол, язык ассемблера, APL, XPL, PL/I, Бейсик, Паскаль, Лисп, Снобол и др. Это не означает, что не подходит какой-нибудь менее известный или менее распространенный язык, тем более что в наших рекомендациях мы руководствовались собственными вкусами. В любом случае приветствуется использование языков и трансляторов более высокого уровня, типа WATFIV, PL/C или SPITBOL, требующих и более серьезного к себе отношения. Можно также использовать задачу для изучения нового языка («полное погружение» — метод тяжелый, но эффективный). (обратно)5
На русском языке вышли 3 тома (как, впрочем, и на английском). — Прим. перев. (обратно)6
Один из способов сокращения памяти, требуемой для запоминания позиций, состоит в том, чтобы хранить позицию в виде массива битов, отводя для каждой клетки один бит (а не слово памяти). Как это ни странно, такой способ позволяет также получить выигрыш во времени, если воспользоваться командами поразрядных логических операций над векторами битов, имеющихся в системах команд почти всех ЭВМ и в некоторых языках программирования высокого уровня (например, в PL/I). Если обозначить через р исходную позицию, через p1, p2, …, p8 — позиции, сдвинутые на одну клетку в направлении всех соседей клетки, и через r — новую позицию, то каждый бит r будет однозначно определяться битами с тем же номером в позициях p1, p2, …, p8, т. е. будет логической функцией от них. Всякую логическую функцию можно, как известно, записать с помощью элементарных логических операций: ∧ (логическое И), ∨ (логическое ИЛИ), ⊕ (сложение по модулю два) и ¬ (логическое отрицание). Задача состоит в том, чтобы выразить r через p1, p2, …, p8 экономно, с использованием возможно меньшего числа операций. Необходимое число операций удается уменьшить до 29 (и это, вероятно, не предел), что при размере машинного слова в 48 битов (над всеми битами слова логические операции выполняются параллельно) составляет чуть более половины логической операции на обработку одной ячейки. — Прим. перев. (обратно)7
Теперь это замечание имеет лишь исторический интерес. Разъяснение вы найдете в литературе к гл. 29. (обратно)8
Английское существительное format (формат) служит для обозначения размера, формы и общего оформления публикации. Фортран присвоил это слово для описания формы и структуры записей данных. Но для обозначения того процесса, которым управляет фортранная инструкция FORMAT, удобного глагола не существует. Поэтому, говоря о процессе оформления текста по заданному образцу или схеме, наряду с глаголом to edit (редактировать) в этой главе будем использовать глагол to format (форматировать). Следует ли это считать жаргоном или нормальным развитием английского языка — дело вкуса читателя. (Примерно так же обстоит дело с терминологией в русском языке. В скобках указаны термины, которые используются в переводе этого этюда. Спорным, конечно, является и слово «форматор» (formattor). — Перев.) (обратно)9
Выпускающий редактор этой книги утверждает, что процесс подготовки большинства изданий проходит отнюдь не так идиллически, как это здесь обрисовано. Хотя в издательстве «Прентис Холл» набор текста производится при помощи ЭВМ, все же большая часть работы по оформлению, размещению и расклейке материала еще делается вручную. В частности, наборщики требуют дополнительного вознаграждения за исправления вкравшихся в текст ошибок. Тем не менее ручной труд в печатном деле отходит в прошлое, а для полной победы автоматизации недостает, пожалуй, только устройства непосредственного ввода рукописного текста. (обратно)10
i — первая буква английского слова italics (курсив). — Прим. перев. (обратно)11
Тут автор неточен. Статистика М показывает, сколько соперников, считавшихся до турниров сильнейшими (имеющих меньшие номера), заняло в обеих классификациях одинаковые места (возможно, и не самые высокие). — Прим. перев. (обратно)12
Все права на изобретение деловой игры менеджмент принадлежат фирме Avalon Hill Company, 4517 Harford Road, Baltimore, MD, 21214, которая ее опубликовала. Мы слегка изменили правила, чтобы этюд легче было программировать. (обратно)13
Профсоюз водителей грузовиков. — Прим. перев. (обратно)14
Инвестиционный фонд — тип финансового института — вкладывает в ценные бумаги денежный капитал, аккумулированный путем эмиссии собственных ценных бумаг. Прибыли фонда обусловлены разницей между полученными и выплаченными дивидендами и процентами. — Прим. перев. (обратно)15
Читатели, знакомые с вычислительными методами, должны были заметить, что приведенная формула соответствует решению уравнения относительно дохода методом Ньютона. (обратно)16
Журнал деловых кругов США — Прим. перев. (обратно)17
В лингвистике диграф — комбинация из двух букв, обозначающая один звук; аналогично, триграф — из трех букв, квадриграф — из четырех и т. д. — Прим. перев. (обратно)18
Попав в калах, камень уже никогда не покинет его: Кроме того, не существует циклических последовательностей ходов, приводящих к исходной позиции, поскольку любом ход либо помещает в калах хотя бы один камень, либо перемещает некоторые камни ближе к калаху. Если реализовать изменение, упомянутое в следующем абзаце, то любая игра должна заканчиваться в состоянии, когда все камни лежат в одном из двух калахов. (обратно)19
Перебор в ширину называют также полным перебором. — Прим. перев. (обратно)20
Достаточно проверить только непосредственный предшественник, при этом будут найдены все отсечения. — Прим. перев. (обратно)21
Это не совсем так. Число простых чисел среди первых n (при n → ∞) примерно равно n/ln n. Таким образом, отношение числа простых и составных чисел есть — Прим. перев.
(обратно)
— Прим. перев.
(обратно)
22
Напомним, что книга издана в 1978 г. — Прим. перев. (обратно)23
Дата в журнале представлена в последовательности месяц, число, год. — Прим. перев. (обратно)24
Дополнительную трудность вызывает использование традиционных английских мер. Однако сделано это умышленно, и вы должны выдавать результаты в тех же единицах. Если бы скорость измерялась в д/д, т. е. в дюймах в день, было бы еще хуже… (обратно)25
Напомним, что натуральное число — это неотрицательное целое число. (обратно)26
Файл ввода/вывода состоит из записей, которые могут быть разной длины. Каждое физическое устройство может накладывать свои ограничения на длину записи. Предполагается, что перед первой операцией ввода/вывода с данным файлом указатель текущей позиции в нем установлен на конец воображаемой нулевой записи. При выводе по мере надобности создаются новые записи. (обратно)27
−q нулей и d+q цифр по стандарту Фортрана и Фортрана-77. — Прим. перев. (обратно)28
Английское словосочетание to lose patience имеет два значения — «потерять терпение» и «проиграть пасьянс». — Прим. перев. (обратно)29
Эта грустная шутка основана на созвучии Las Vegas (Лас Вегас) и lost wages (потерянные зарплаты). — Прим. перев. (обратно)30
Фактически поиск максимального в столбце элемента М на шаге 3 алгоритма обращения есть одно из таких изменений. М называется ведущим элементом, а сама операция — выбором ведущего элемента; на самом деле необходимо лишь, чтобы М был ненулевым. Максимальный элемент используется, чтобы уменьшить арифметическую погрешность ЭВМ. При обращении матрицы Гильберта ведущим элементом всегда должен оказываться ; если же алгоритм выбирает в качестве ведущего элемент, лежащий ниже, то это означает, что погрешность уже очень велика.
(обратно)
; если же алгоритм выбирает в качестве ведущего элемент, лежащий ниже, то это означает, что погрешность уже очень велика.
(обратно)
31
Как здесь не отметить, что самую плодотворную идею по части быстрого умножения вы можете позаимствовать у кроликов. Их многочисленное потомство — тому порука. (обратно)32
Дадим небольшое пояснение к рисунку: long — длинный, stack — стек, control — управляющий pop … into — удалить вершину … и поместить в, abort — аварийное окончание. Остальные ключевые слова имеют тот же смысл, что в языке Паскаль. — Прим. перев. (обратно)33
В алгоритм, вероятно, необходимо внести следующие изменения: a) на шаге 1 заменить max (m, 2n) на max (2m − 2n, 2n); b) на шаге 4 заменить 23·2i на 23·2i−1. Прежде чем приступать к программированию алгоритма Тоома—Кука или алгоритма деления, рекомендуем тщательно разобраться в них, ознакомившись с теорией, например по книге Кнута, неоднократно цитируемой здесь — Прим. перев. (обратно)34
На самом деле ai+1 = (ai/5²) · (2i − 1)/(2i + 1)). Чтобы не выполнять умножение, можно хранить кроме ai еще одно число bi, равное (21000 × 16)/52i−1. Тогда переход к следующему члену осуществляется по формулам: bi+1 = bi/5², ai+1 = bi+1/(2i + 1). — Прим. перев. (обратно)35
Эти алгоритмы для очень длинных чисел работают еще быстрее алгоритма Тоома—Кука, затрачивая на умножение n-разрядных чисел время, пропорциональное n log n log log n — Прим. перев. (обратно)36
В § 4.4этой книги приведены алгоритмы перевода чисел в десятичную систему. — Прим. перев. (обратно)37
В журнале «Наука и жизнь» № 2, 1978, с. 150–151; № 8, 1978, с. 142—143, опубликован вариант этой игры под названием «Быки и коровы». — Прим. перев. (обратно)38
Здесь автор имеет в виду вариант той же игры, в котором вместо цифр используются фишки, окрашенные в шесть цветов. — Прим. перев. (обратно)39
В оригинале, разумеется, все рассуждения проводятся для английского текста. — Прим. перев. (обратно)40
В криптографии используются некоторые слова, которые люди непосвященные часто употребляют не совсем правильно. Шифрование — это способ засекречивания сообщения путем замены или перемешивания букв, кодирование же подразумевает замену целых слов или фраз, а не отдельных букв. Лица, владеющие шифром или кодом, шифруют или кодируют свои сообщения, а получатели сообщений дешифруют или декодируют их. Лица, пытающиеся узнать чужой секрет, расшифровывают сообщения; различие между этими глаголами соответствует различию между знанием секрета шифра и попыткой разгадать его. Тот, кто составляет секретные сообщения, занимается криптографией, или тайнописью, а тот, кто стремится прочитать чужое секретное сообщение, занимается анализом криптограмм (cryptanalysis). Применяемые для этого методы составляют предмет науки, которая по-английски называется cryptology. (обратно)41
American Standart Code for Information Interchange—американский стандартный 8-разрядный код для обмена информацией. — Прим. перев. (обратно)42
Признак косвенной адресации, — Прим. перев. (обратно)43
Аббревиатуры от Register-Register (регистр-регистр), Register-Storage (регистр-память), IMmediate (непосредственная), CHaracter (байтовая). — Прим. перев. (обратно)44
На языке ассемблера разряд косвенной адресации задается звездочкой перед полем адреса, как, например, LN,R1 * A,R.2. (обратно)45
Аббревиатуры от Overflow (переполнение), Less than (меньше, чем), Greater than (больше, чем), Equal (равно). — Прим, перев. (обратно)46
При установке признака результата предполагается, что в операциях отношения слева стоит первый из указанных операндов, а справа — второй. То есть, если выработан признак «меньше, чем», значит, первый операнд меньше второго. (обратно)47
Хотя во всех командах Reverse значения двух операндов и меняются ролями, результат записывается туда же, куда и раньше. (обратно)48
Мнемоническим обозначениям команд арифметических операций с вещественными числами предшествует буква «F» в силу исторически сложившегося названия представления вещественных чисел как чисел с плавающей точкой (floating point). Это отражается также в мнемонике кодов операций FLOATR, FLOAT и FLOATI. (обратно)49
Эти команды обозначены FIXR, FIX и FIXI, поскольку представление целых чисел исторически называется представлением с фиксированной точкой (fixed point). (обратно)50
Счетчик сдвига, по абсолютной величине больший 32, определяет те же действия, что и соответствующий счетчик, по модулю равный или меньший 32. При выполнении команды сдвига большие значения счетчика заменяются меньшими (обратно)51
Такое многозначное употребление слова «литера» вновь возникнет при обсуждении загрузчика УМ. Постарайтесь четко уяснить разницу между литерами (байтами) в памяти и литерами во входном и выходном файлах. Во внутренней литере всегда содержится достаточно данных, чтобы представить одну внешнюю литеру, в то время как внешней литеры иногда недостаточно, чтобы закодировать одну внутреннюю литеру. (обратно)52
Вообще, если A есть начальный адрес текущего загружаемого модуля, то всегда выполняется соотношение САР — А = СОР. То есть САР и СОР при всех обстоятельствах изменяются согласованно, образуя тандем. (обратно)53
Чтобы вспомнить различие между внутренними и внешними литерами, перечитайте раздел о файле абсолютной загрузки в гл. 25. (обратно)54
Стиль последующего изложения показывает, сколь высоко оценивает автор квалификацию своих читателей. — Прим. перев. (обратно)55
В русском переводе приходится склонять нетерминальные символы грамматики. — Прим. перев. (обратно)56
Одной из главных трудностей при доказательстве правильности программ является выделение смысла программы из написанных программистом императивов. Поскольку правильность зависит от отображений желаемого в действительное, ценно все, что помогает вскрыть намерения. Вводимое в Мини разграничение функций и подпрограмм — шажок в этом направлении. Заметим также, что хороший программист никогда не использует процедуру и как функцию, и как подпрограмму, ну а Мини просто придает этому правилу силу закона. (обратно)57
Возможно, читателя заинтересуют следующие вопросы: 1. При какой точности выполнения операций с плавающей точкой можно гарантировать конечность первого цикла в функции integersqrt? 2. Не может ли получиться так, что после завершения этого цикла будет выполнено неравенство ?
3. Нельзя ли избавиться от второго цикла в функции integersqrt, выполнив все операции первого в целочисленной арифметике? Как следует выбрать начальное приближение и условие завершения цикла?
4. Действительно ли нужно прибавлять 1 при вычислении значения limit? 5. Можно ли в заголовке цикла маркировки составных чисел заменить 2*i на i*i?. — Прим. перев.
(обратно)
?
3. Нельзя ли избавиться от второго цикла в функции integersqrt, выполнив все операции первого в целочисленной арифметике? Как следует выбрать начальное приближение и условие завершения цикла?
4. Действительно ли нужно прибавлять 1 при вычислении значения limit? 5. Можно ли в заголовке цикла маркировки составных чисел заменить 2*i на i*i?. — Прим. перев.
(обратно)
Последние комментарии
4 часов 25 минут назад
4 часов 33 минут назад
4 часов 43 минут назад
4 часов 48 минут назад
6 часов 17 минут назад
6 часов 20 минут назад